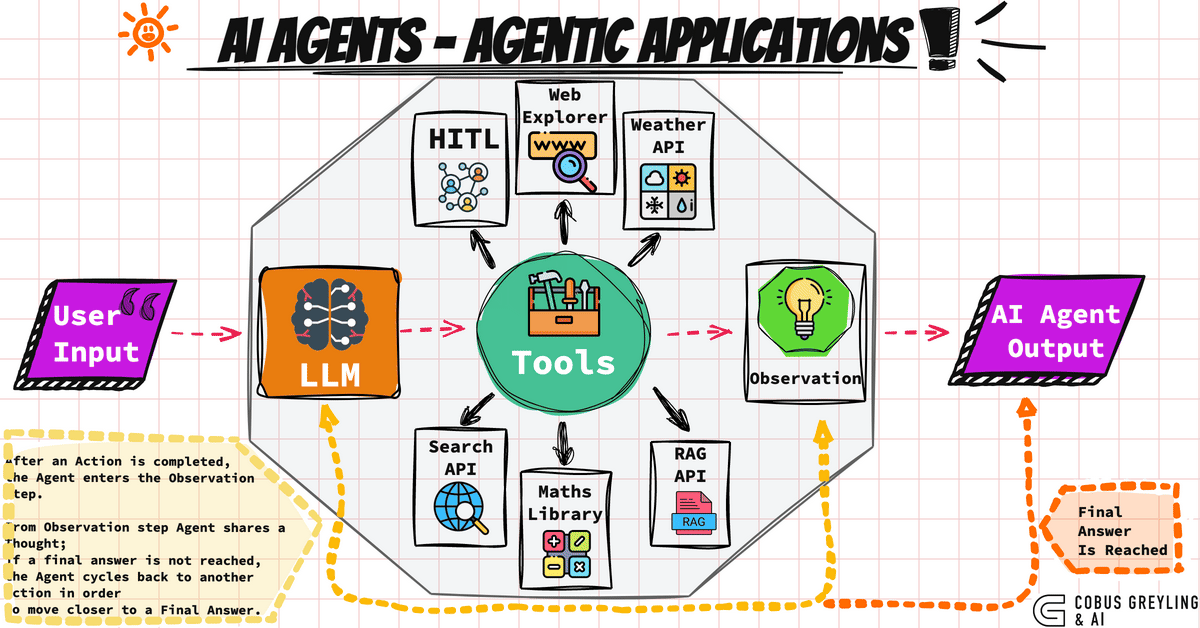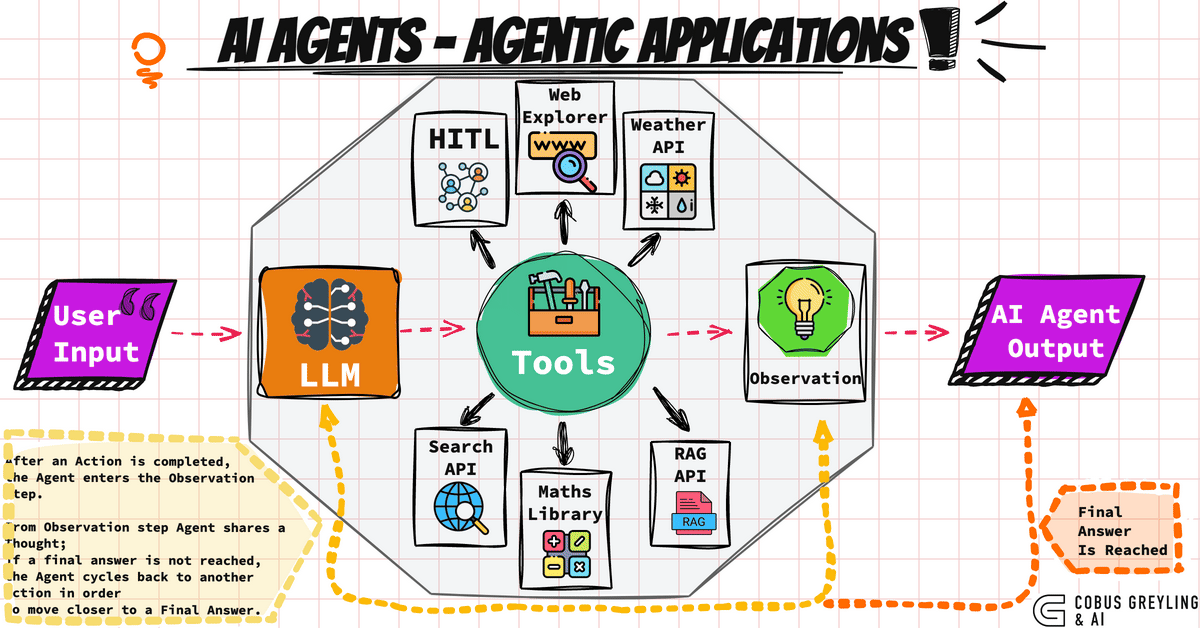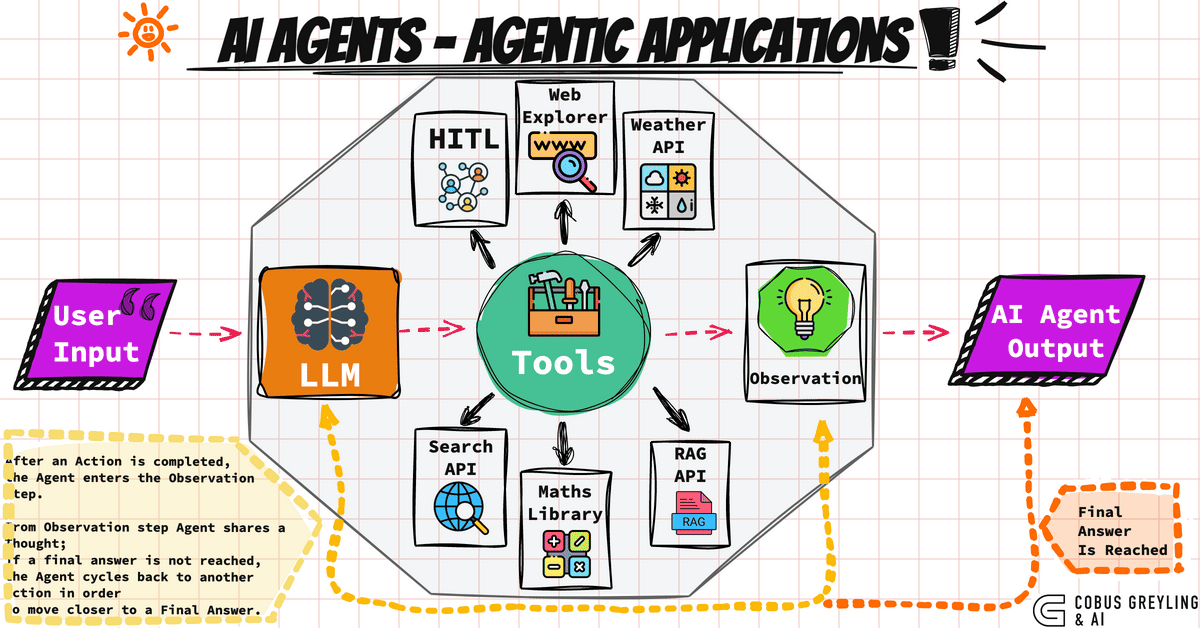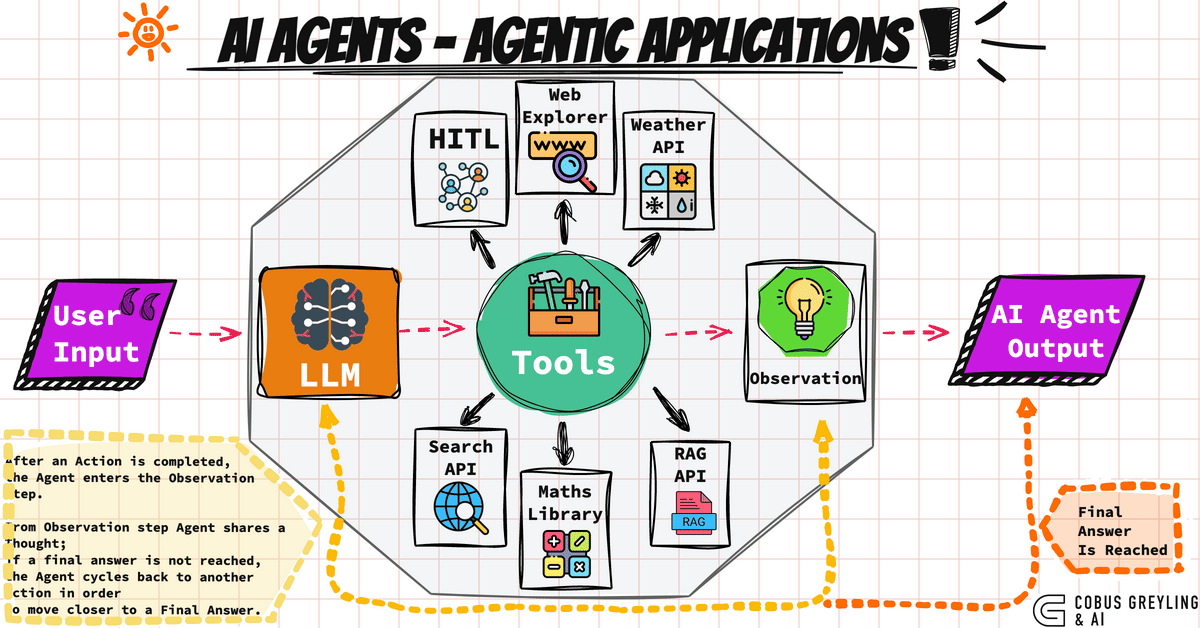
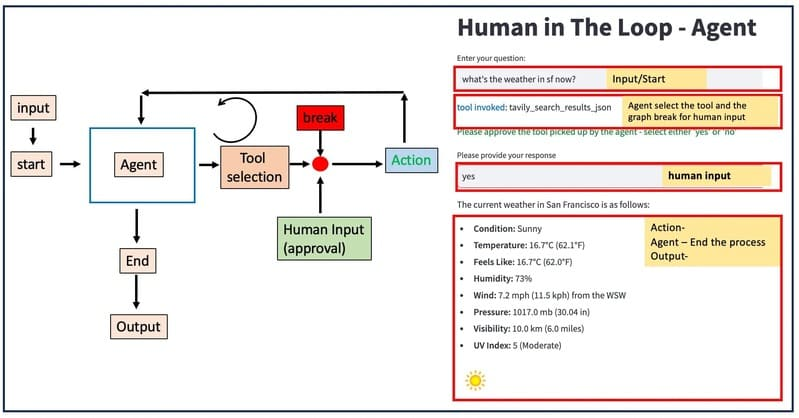
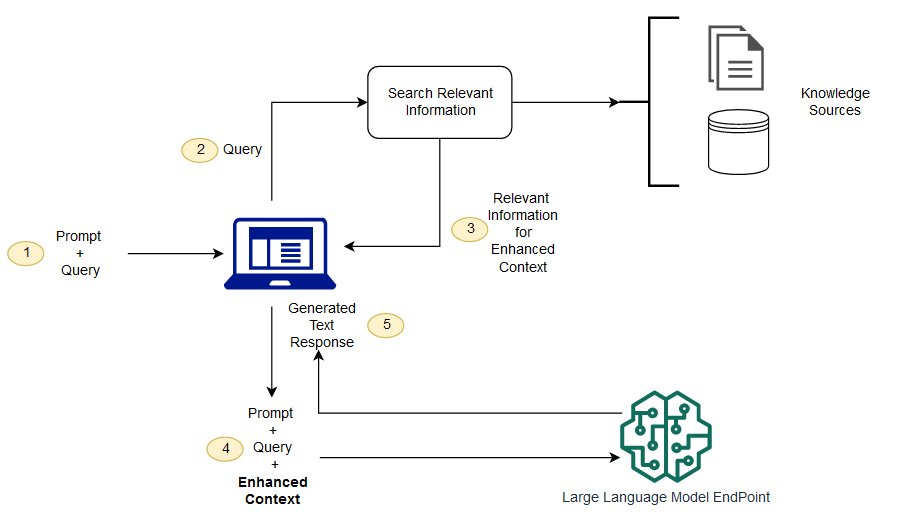
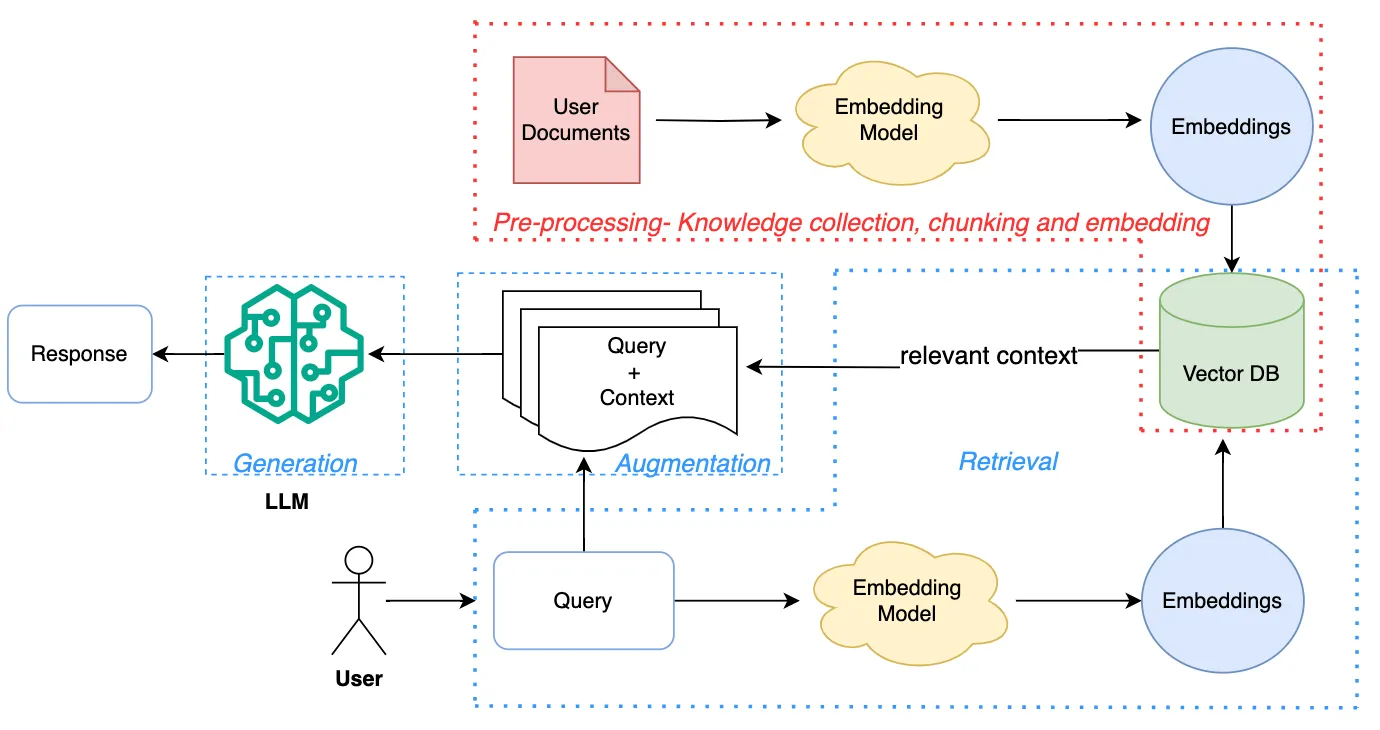
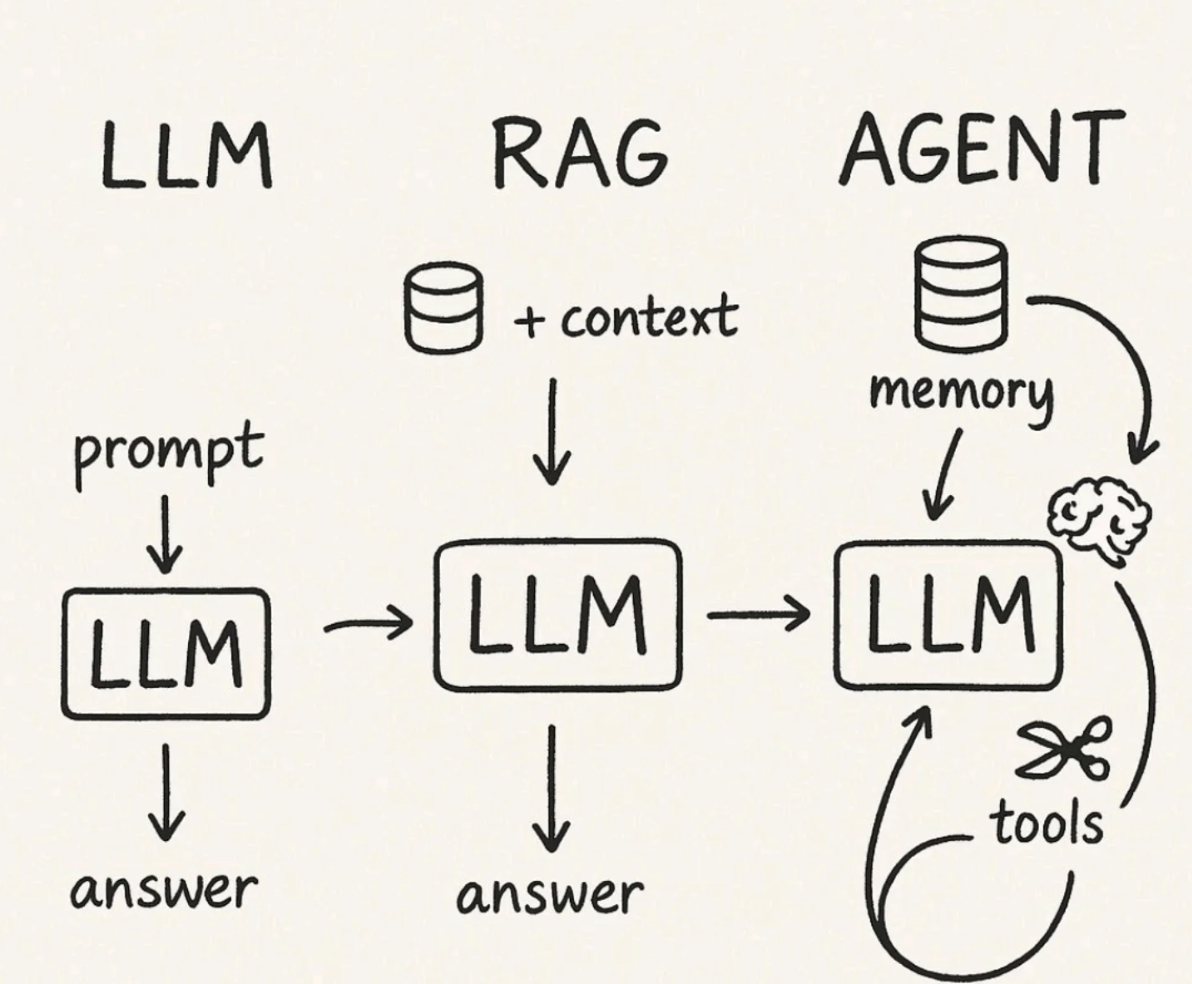
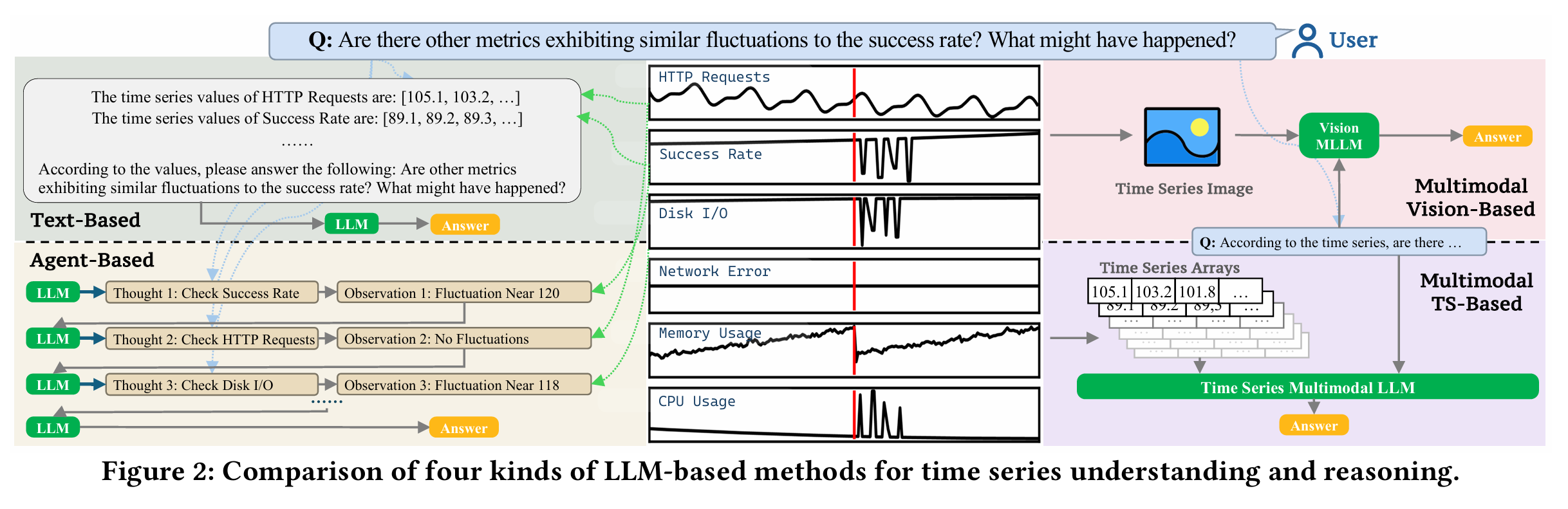
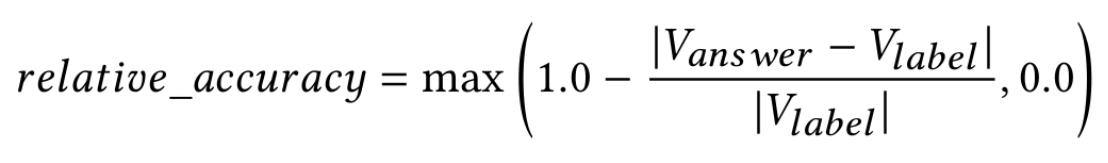最近回想起自己读博士期间的生活,不禁想到那些“混日子”的日子。说是混日子,其实是科研之外的一些生活细节和琐事——它们虽不关论文、不涉及动力系统,但却在我心中留下了深刻的印记。

其中最让我念念不忘的,就是吃。在新加坡的那几年里,除了写论文、开组会、改论文,我花了不少时间在寻找美食上。其实早在2013年12月5日那天,我就曾写过一篇文章,系统地回顾了从2010年7月抵达新加坡,到2013年12月这三年多时间里,所吃过的那些美食。在新加坡国立大学(NUS)读博的那些年,除了在NUS Block S17 五楼办公室的清晨与黄昏,图书馆的冷气与长夜,还有一样无法忽视的记忆——味道。新加坡的餐饮像它的文化一样多元,无论是小贩中心里的鸡饭,还是海鲜餐厅里的黑胡椒螃蟹,每一口都饱含着异乡生活的真实感。

还记得 Clementi MRT 附近的 Block 328 食阁里,有一家叫“黄土地”的西安小吃摊。最爱点一份羊肉泡馍、或者肉夹馍加一碗凉皮。那种在异国城市中突然被熟悉气息包围的感觉,温暖又踏实。说起自助餐,不得不提的是Novena地铁站附近的维也纳海鲜。那是我在新加坡最常去的海鲜自助餐厅。螃蟹、麦片虾、三文鱼、牛排……每一样都让我念念不忘。某次离新加坡不久前,我和胡大师、曾同学、卫教授在串烧工坊烧烤聚餐,几个人一边大快朵颐一边感叹时光飞逝。同样记忆深刻的还有螃蟹米粉——宏茂桥那一锅令人上瘾的美味。那晚是我即将启程回国前几天的夜晚,我特意独自赶到 Ang Mo Kio,只为再尝一次那浓郁的蟹汤和弹牙的米粉。汤汁乳白色浓稠,喝下一口,多年来所有科研的疲惫和未来的不确定似乎都被安抚。

除了热闹的聚餐,也有安静的食光。我常常和卫教授去 Vivo City 的武藏拉面店或者 Holland Village 的拉面店,点一碗拉面,一口汤一口面,仿佛回到学生时代的晚餐店。那里也是我思考论文方向的地方,有时是对抗困意的作战基地,有时是独处时最好的慰藉。讲到早期的用餐记忆,还记得 West Coast Plaza 内曾有一家叫“川江号子”的火锅店,是我们刚来新加坡那会的“根据地”。当年预算紧张,川江号子实惠管饱,三两朋友围坐一锅,从中午涮到下午,牛百叶、午餐肉、宽粉、海带……热腾腾的烟雾像是青春的蒸汽。虽然后来它关门了,但在我的记忆里,那锅火锅一直在咕嘟咕嘟地冒着泡。

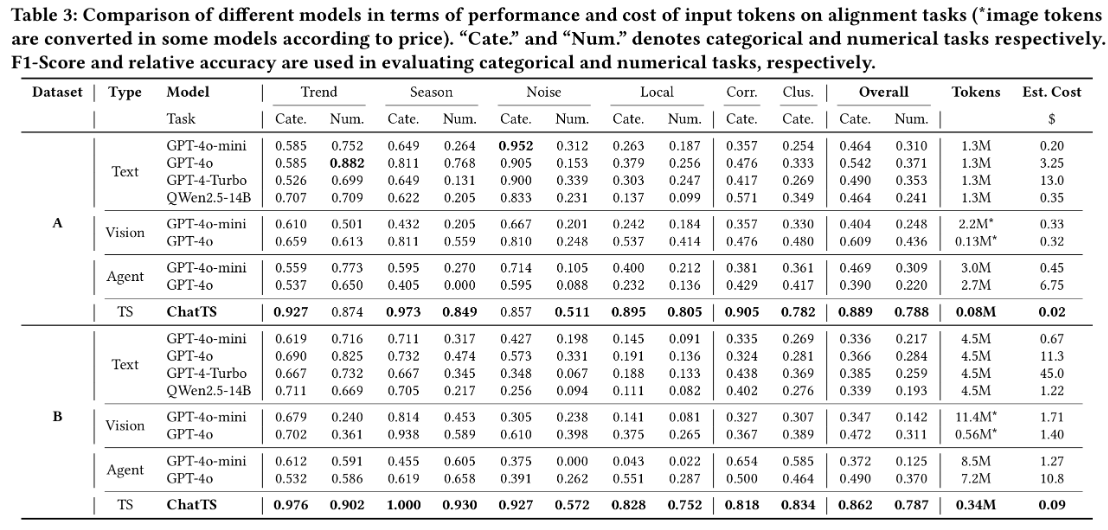
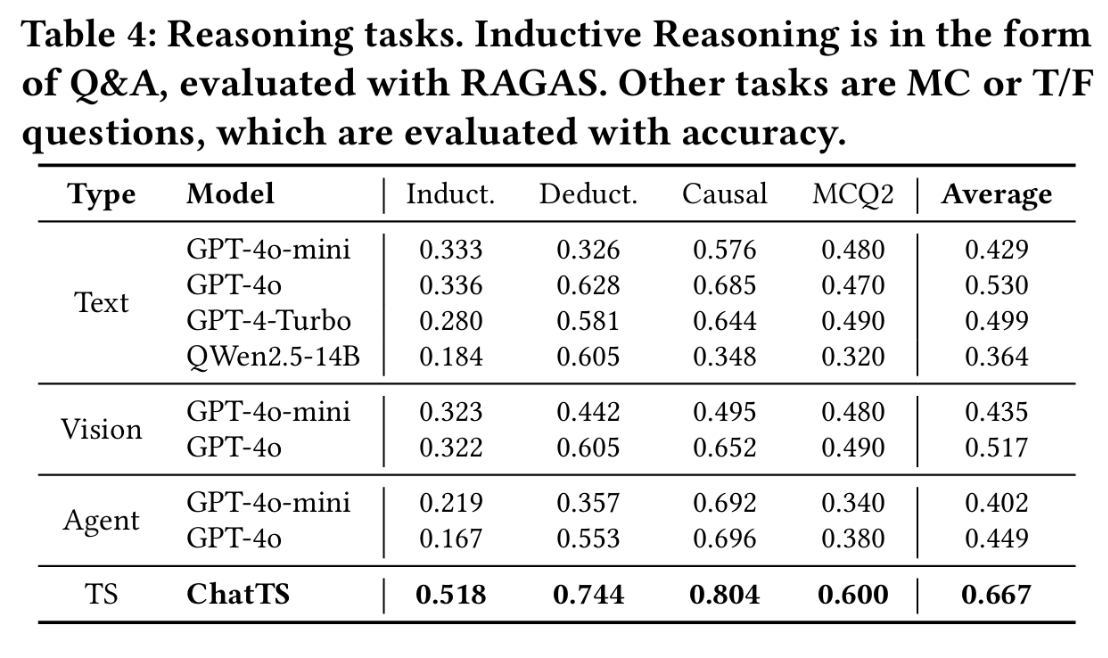
福苑家传菜,则是另一种风格。清淡的江浙菜,精致而不张扬。我和富贵常在周末去那里点几道菜:东坡肉、清炒苋菜、葱油拌面。一次次的聚餐中,我们谈未来,也聊现实。后来我和司北一起去珍宝海鲜楼吃饭,那顿饭是对友情的致敬——在克拉码头边吃着辣椒螃蟹,看着对岸灯火。新加坡有太多让人难忘的味道,鸡饭是最简单却最百吃不腻的快餐选择,印尼烧烤的香料气息浓烈而持久,肉骨茶那种略带中药味的滋补感曾让我在感冒时一碗见底。在Science Canteen、Buona Vista、在 Holland Village、在 Clementi,每一顿饭都是我博士旅程中的一页页篇章,记录着论文的进展、友谊的温度和生活的温柔。

有些饭,是为了果腹;有些饭,是为了回忆。新加坡的味道,已然融进我生命的一部分,留在了心的角落,和那些并肩走过的朋友们一起,静静存在。下面是我整理过的当年在新加坡吃过的美食。
自助餐
| 餐厅名称 | 地址或附近地标 | 备注 |
| 添一点火锅 | West Coast 的生松附近 | 总是感觉不是很卫生 |
| 川江号子 | West Coast Plaza 内部 | 已关闭 |
| 汤王火锅 | West Coast 的生松附近 | 味道一般 |
| 川丰乐清油火锅 | Outram Park 地铁站附近 | 味道不错 |
| 国府珍锅 | China Square Center,Downtown MRT | 2014年夜饭吃的,一人一小锅的火锅 |
| Sakura | Clementi Woods | 日本自助,性价比不高 |
| 维也纳海鲜 | Novena 地铁站,United Square | 黑胡椒螃蟹和麦片虾很好吃 |
| 川苑酒家(自助) | — | 点菜自助,需三人起 |
| 翡翠拉面小笼包 | Holland Village MRT 附近 | 小笼包不错,但自助容易腻 |
| 首尔花园 | Clementi Mall | 韩国烧烤,学生中午优惠,约18新币 |
| Buffet Town | City Hall MRT 附近 | 有海鲜、寿司、披萨,类似维也纳海鲜 |
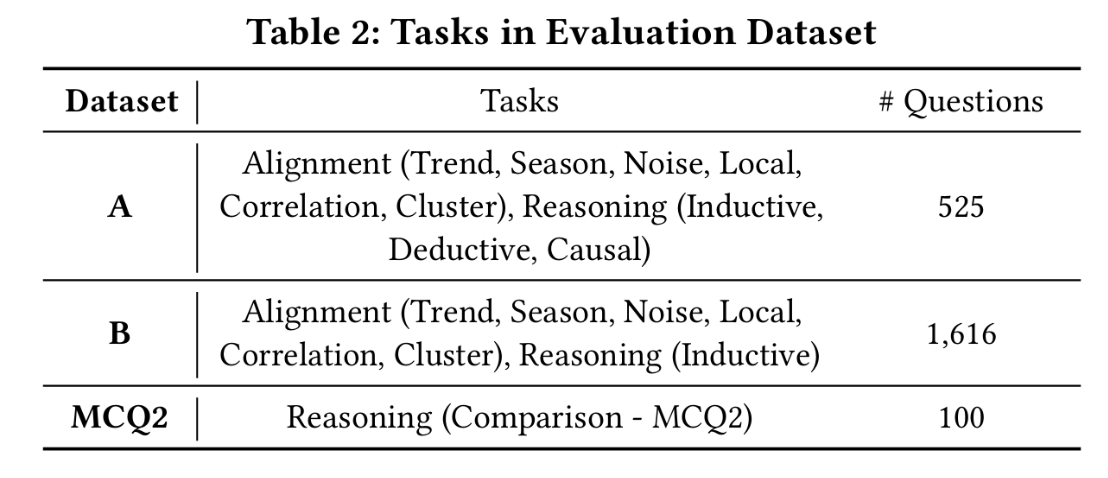
点菜餐厅
| 餐厅名称 | 地址或备注 |
| 川苑酒家(点菜) | 起初人均30+新币,现在50+ |
| 老成都川菜馆 | 人均约50+ |
| 密斯湘菜馆 | — |
| 羊贵妃西安美食 | — |
| 同福聚-重庆千品烤鱼 | — |
| 重庆烤鱼 | — |
| 风波庄 | 吃了一些小吃 |
| 蟹老宋 | 螃蟹还不错 |
| 东北人烤肉坊 | — |
| 刘大妈烧烤 | 吃牛羊肉烧烤 |
| 串烧工坊 | Bugis 地铁站 D 出口 |
| 思味冒菜馆 | — |
| 福苑家传菜 | — |
| 食尚小厨 | 6 Clementi Rd #01-06, Singapore 129741 |
海鲜餐厅
| 餐厅名称 | 地址或备注 |
| 珍宝海鲜楼(Jumbo) | 东海岸店、克拉码头店 |
| 维也纳海鲜 | 已在自助餐中列出,去过无数次 |
| 无招牌海鲜 | VivoCity 店 |
| 龙海鲜螃蟹王(Mellben) | 232 Ang Mo Kio Ave 3, SG 560233 |
日本拉面
| 餐厅名称 | 地址或备注 |
| 武藏拉面 | VivoCity |
| RamenPlay | 253 Holland Ave #01-01,Holland Village MRT Station Exit A |
食阁美食
| 餐厅名称 | 地址或备注 |
| 西安小吃黄土地 | Clementi MRT,Block 328 一楼 |
| Chinatown 麻辣香锅 | 珍珠坊附近 |
| Holland Village 鱼头米粉 | XO鱼头米粉,味道一般 |
汉堡快餐
| 品牌 | 分店位置或备注 |
| 麦当劳 | NUS Engineering、Clementi FairPrice 附近、机场 T2 航站楼 |
| KFC | — |
| Burger King | 机场 T2 航站楼 |
外卖熟食
| 来源 | 备注 |
| West Coast Plaza Cold Storage | 卖烧鸡、烧肉、排骨等,还有寿司外卖 |
读博士的时候,科研实在太难了,一天天的几乎什么也做不出来。那时候每天对着数学论文发呆,内心充满了挫败感,每一天起床都要面对一天的失败。可是真要完全躺平、天天玩也不现实。于是我换了个思路:既然纯数学搞不定,不如去学点计算机的东西。那几年我认真看了好几遍《C++ Primer》、《数据结构与算法导论》、《算法导论》,然后跑到 UVA Online Judge 上刷题,回头一看居然刷了 700 多道。毕竟能做出题目还是很有成就感的,远比在抽象的数学世界里摸索强得多。
除此之外,我还经常跑到 NUS 的游泳池里面去游泳。有可能是工作日的早上去,也有可能是周末的早上跟卫教授从PGPR的宿舍区坐A2过去。每次游至少一公里,在水中放空自己,有时候也试图思考些问题。虽然说实话,在泳池里也没得出什么有价值的数学结论,但却是真的能放松下来,身体和脑子都得到了舒缓。

2015年3月以后,原来的游泳池关闭了,只剩下 UTown 屋顶的泳池。那里水不深,但环境非常好,站在泳池边可以俯瞰整个 UTown,一边游泳一边吹风。那个时候我的论文已经有了着落,同时偶尔觉得自己也没那么失败。

除此之外,我在各种社交网站上也有活跃,例如Wordpress、知乎、还有其他的社交平台(如当年的人人网)上,经常发帖和看帖子。另外就是在玩暗黑3、骑马与砍杀、极品飞车9、Dota等电脑游戏。新加坡的饮食多元化,我还经常在食阁(Food Court)和 West Coast Plaza用餐,无需自己做饭,享受各种美食如火锅、海鲜自助餐等。我闲暇时还喜欢看电视剧。什么《神探狄仁杰》系列、燕双鹰系列,看个遍。有时一集接一集地刷,看着剧情跌宕起伏,觉得现实生活也许不需要那么多答案,只要能有点节奏、有点情节,也不错。
这些,就是我博士那几年科研之外的日常生活。日常的工作和生活说不上充实,但至少有血有肉、有喜有忧。在那个总感觉自己走不出学术迷雾的阶段里,这些平凡又真实的片段,构成了我坚持读博的理由。博士读不读得出来是一个问题,但人的精气神不能丢,生活也不能垮。有时候,活着本身就是最有意义的研究课题。