AI is about to go mainstream. It will show up in the connected home, in your car, and everywhere else. While it’s not as glamorous as the sentient beings that turn on us in futuristic theme parks, the use of AI in fraud detection holds major promise. Keeping fraud at bay is an ever-evolving battle in which both sides, good and bad, are adapting as quickly as possible to determine how to best use AI to their advantage.
There are currently three major ways that AI is used to fight fraud, and they correspond to how AI has developed as a field. These are:
- Rules and reputation lists
- Supervised machine learning
- Unsupervised machine learning
Rules and reputation lists
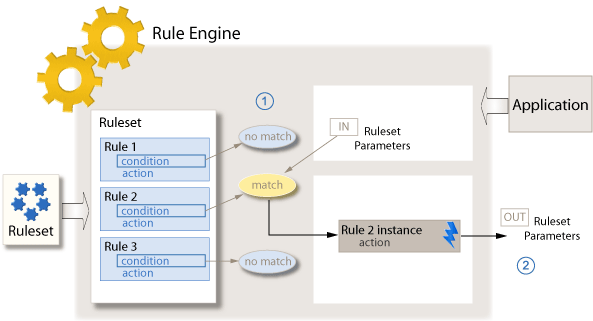
Rules and reputation lists exist in many modern organizations today to help fight fraud and are akin to “expert systems,” which were first introduced to the AI field in the 1970s. Expert systems are computer programs combined with rules from domain experts.They’re easy to get up and running and are human-understandable, but they’re also limited by their rigidity and high manual effort.
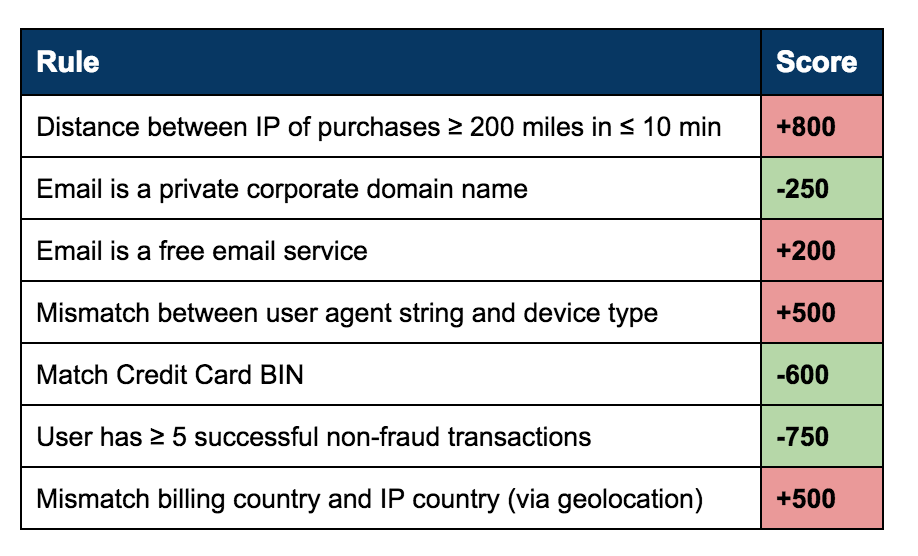
A “rule” is a human-encoded logical statement that is used to detect fraudulent accounts and behavior. For example, an institution may put in place a rule that states, “If the account is purchasing an item costing more than $1000, is located in Nigeria, and signed up less than 24 hours ago, block the transaction.”
Reputation lists, similarly, are based on what you already know is bad. A reputation list is a list of specific IPs, device types, and other single characteristics and their corresponding reputation score. Then, if an account is coming from an IP on the bad reputation list, you block them.
While rules and reputation lists are a good first attempt at fraud detection and prevention, they can be easily gamed by cybercriminals. These days, digital services abound, and these companies make the sign-up process frictionless. Therefore, it takes very little time for fraudsters to make dozens, or even thousands, of accounts. They then use these accounts to learn the boundaries of the rules and reputation lists put in place. Easy access to cloud hosting services, VPNs, anonymous email services, device emulators, and mobile device flashing makes it easy to come up with unsuspicious attributes that would miss reputation lists.
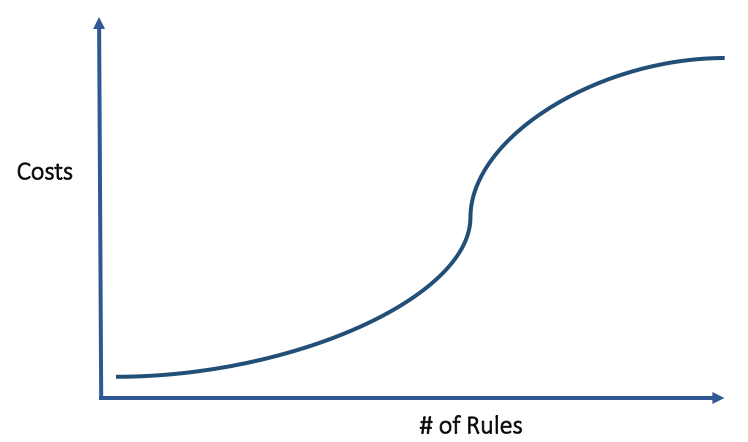
Since the 1990s, expert systems have fallen out of favor in many domains, losing out to more sophisticated techniques. Clearly, there are better tools at our disposal for fighting fraud. However, a significant number of fraud-fighting teams in modern companies still rely on this rudimentary approach for the majority of their fraud detection, leading to massive human review overhead, false positives, and sub-optimal detection results.
Supervised machine learning (SML)
Machine learning is a subfield of AI that attempts to address the issue of previous approaches being too rigid. Researchers wanted the machines to learn from data, rather than encoding what these computer programs should look for (a different approach from expert systems). Machine learning began to make big strides in the 1990s, and by the 2000s it was effectively being used in fighting fraud as well.
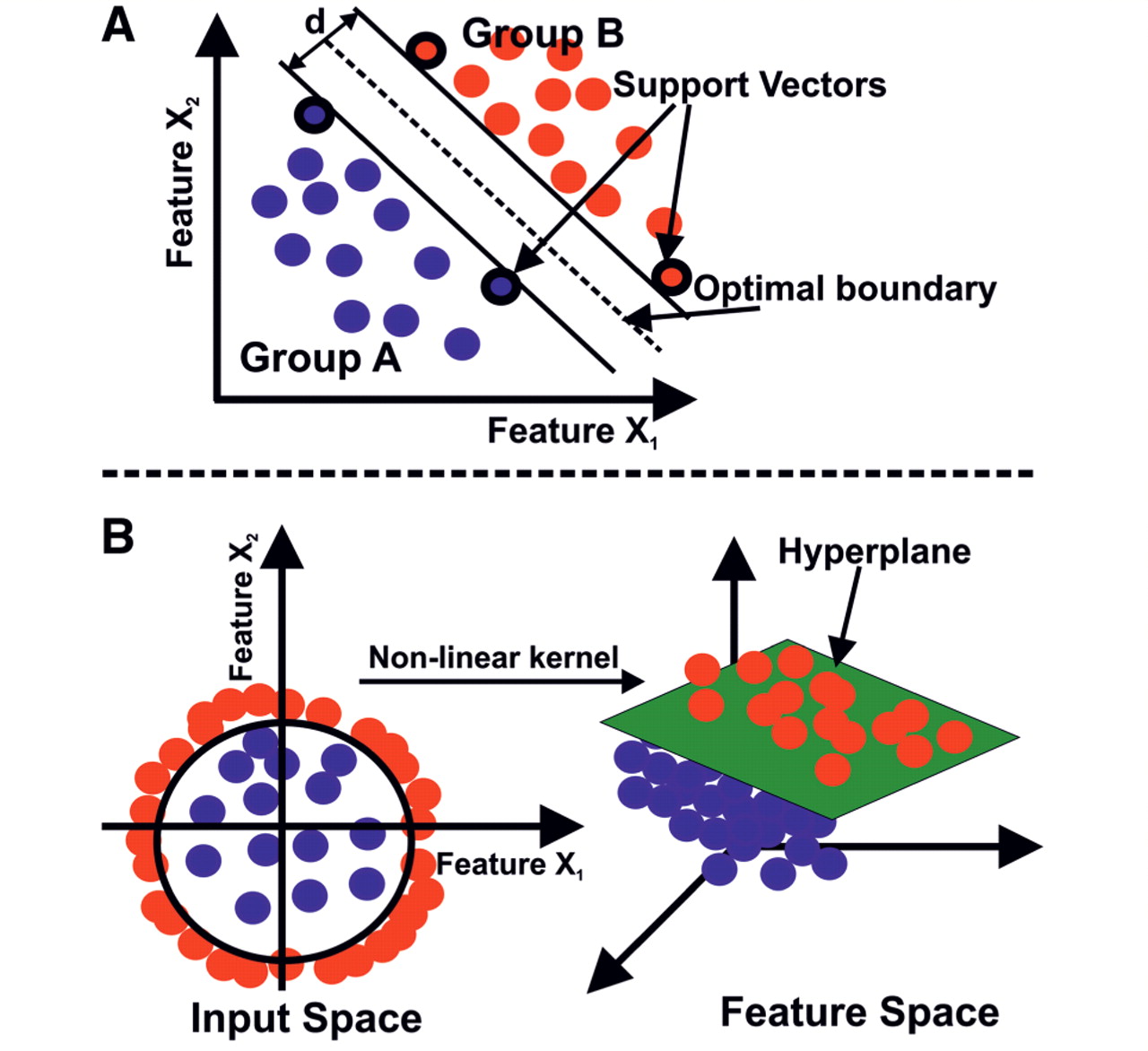
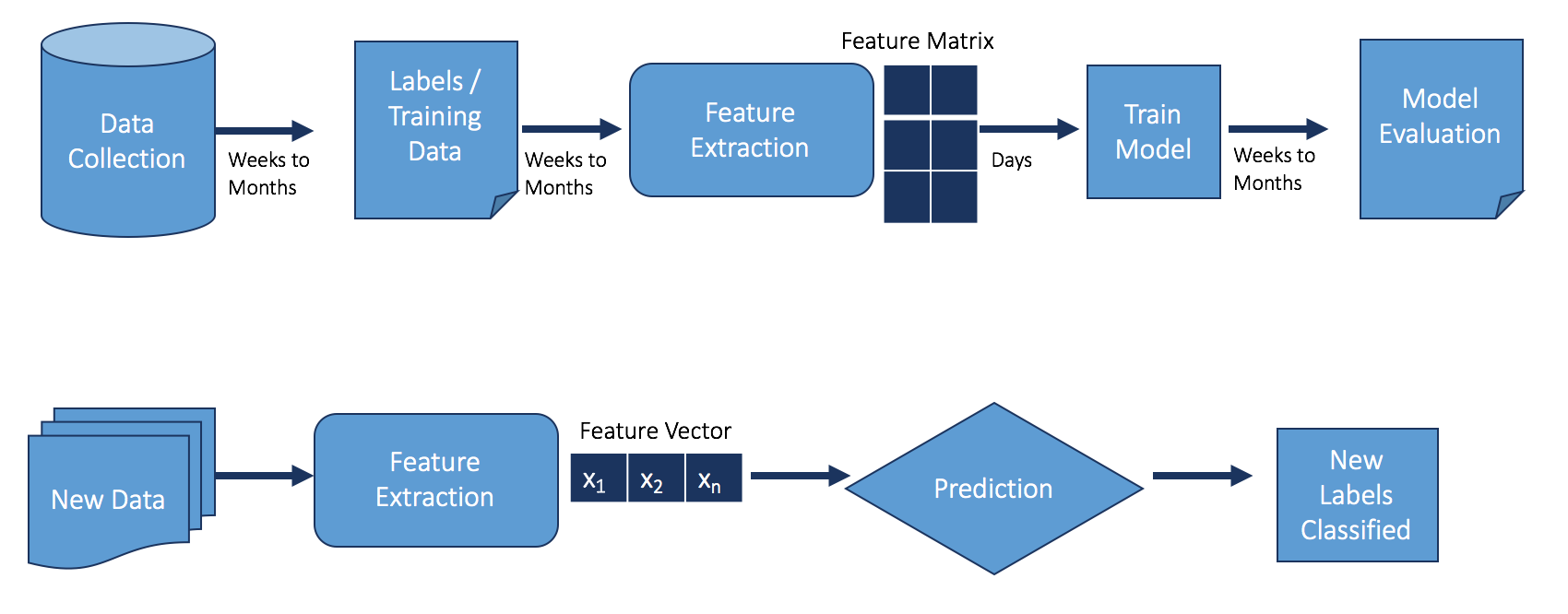
Applied to fraud, supervised machine learning (SML) represents a big step forward. It’s vastly different from rules and reputation lists because instead of looking at just a few features with simple rules and gates in place, all features are considered together.
There’s one downside to this approach. An SML model for fraud detection must be fed historical data to determine what the fraudulent accounts and activity look like versus what the good accounts and activity look like. The model would then be able to look through all of the features associated with the account to make a decision. Therefore, the model can only find fraud that is similar to previous attacks. Many sophisticated modern-day fraudsters are still able to get around these SML models.
That said, SML applied to fraud detection is an active area of development because there are many SML models and approaches. For instance, applying neural networks to fraud can be very helpful because it automates feature engineering, an otherwise costly step that requires human intervention. This approach can decrease the incidence of false positives and false negatives compared to other SML models, such as SVM and random forest models, since the hidden neurons can encode many more feature possibilities than can be done by a human.
Unsupervised machine learning (UML)
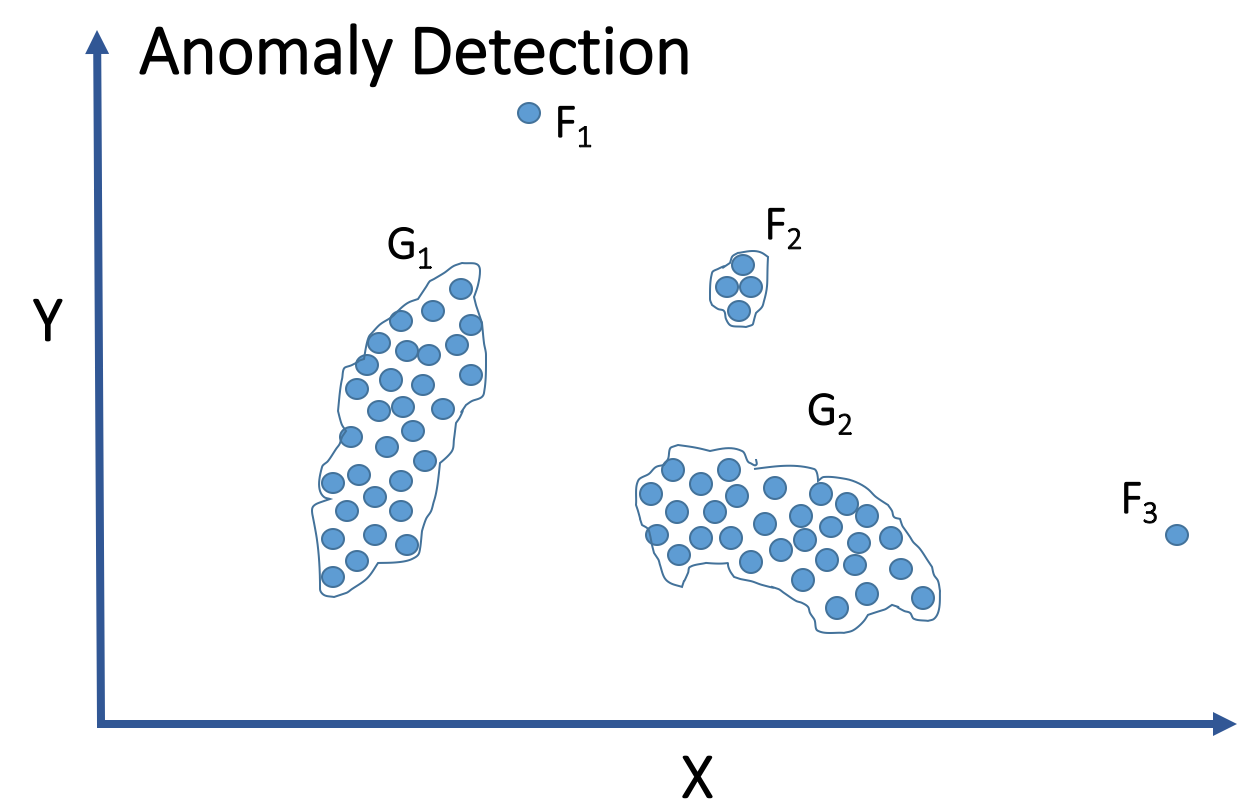
Compared to SML, unsupervised machine learning (UML) has cracked fewer domain problems. For fraud detection, UML hasn’t historically been able to help much. Common UML approaches (e.g., k-means and hierarchical clustering, unsupervised neural networks, and principal component analysis) have not been able to achieve good results for fraud detection.
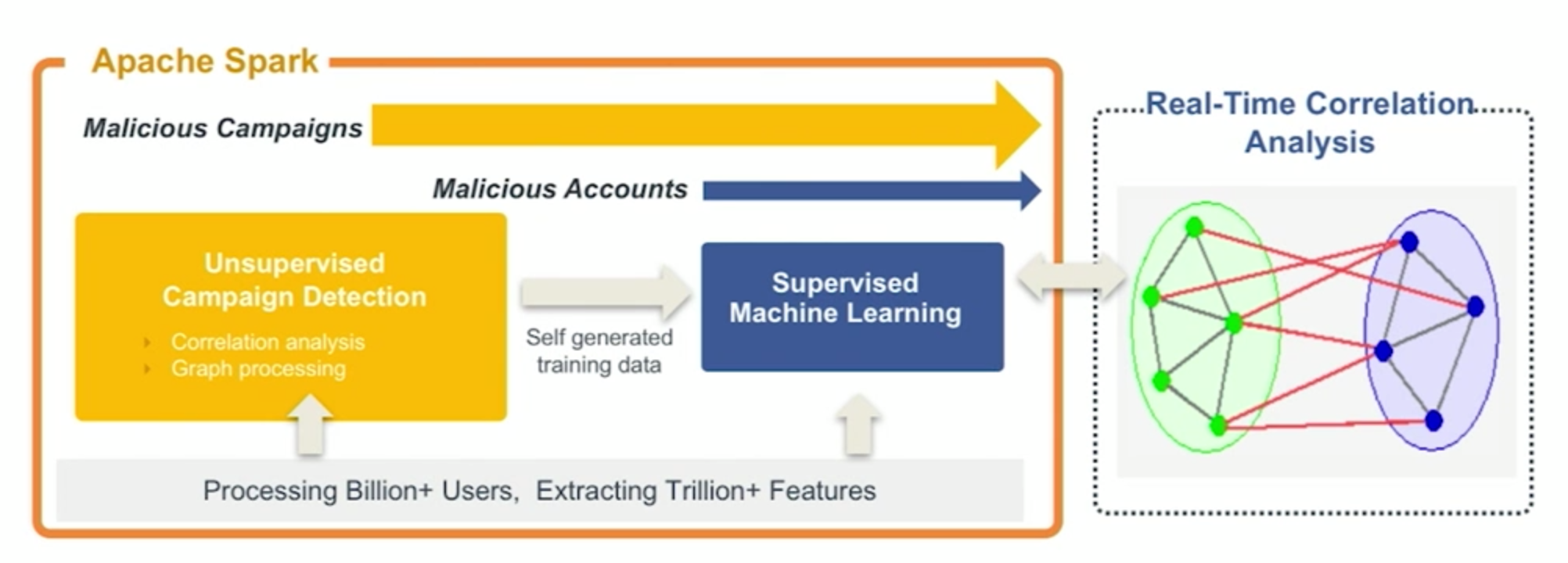
Having an unsupervised approach to fraud can be difficult to build in-house since it requires processing billions of events all together and there are no out-of-the-box effective unsupervised models. However, there are companies that have made strides in this area.
The reason it can be applied to fraud is due to the anatomy of most fraud attacks. Normal user behavior is chaotic, but fraudsters will work in patterns, whether they realize it or not. They are working quickly and at scale. A fraudster isn’t going to try to steal $100,000 in one go from an online service. Rather, they make dozens to thousands of accounts, each of which may yield a profit of a few cents to several dollars. But those activities will inevitably create patterns, and UML can detect them.
The main benefits of using UML are:
- You can catch new attack patterns earlier
- All of the accounts are caught, stopping the fraudster from making any money
- Chance of false positives is much lower, since you collect much more information before making a detection decision
Putting it all together
Each approach has its own advantages and disadvantages, and you can benefit from each method. Rules and reputation lists can be implemented cheaply and quickly without AI expertise. However, they have to be constantly updated and will only block the most naive fraudsters. SML has become an out-of-the box technology that can consider all the attributes for a single account or event, but it’s still limited in that it can’t find new attack patterns. UML is the next evolution, as it can find new attack patterns, identify all of the accounts associated with an attack, and provide a full global view. On the other hand, it’s not as effective at stopping individual fraudsters with low-volume attacks and is difficult to implement in-house. Still, it’s certainly promising for companies looking to block large-scale or constantly evolving attacks.
A healthy fraud detection system often employs all three major ways of using AI to fight fraud. When they’re used together properly, it’s possible to benefit from the advantages of each while mitigating the weaknesses of the others.
AI in fraud detection will continue to evolve, well beyond the technologies explored above, and it’s hard to even grasp what the next frontier will look like. One thing we know for sure, though, is that the bad guys will continue to evolve along with it, and the race is on to use AI to detect criminals faster than they can use it to hide.
Catherine Lu is a technical product manager at DataVisor, a full-stack online fraud analytics platform.