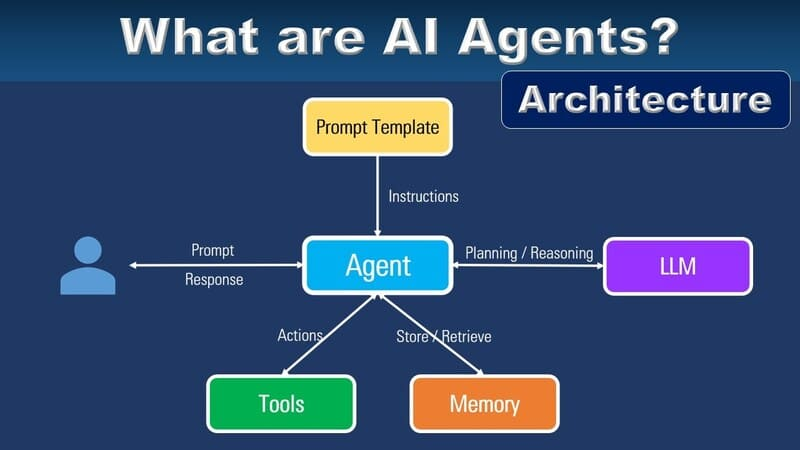
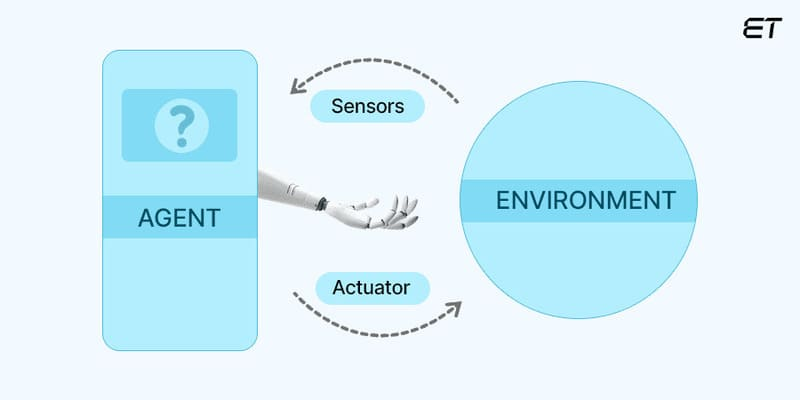
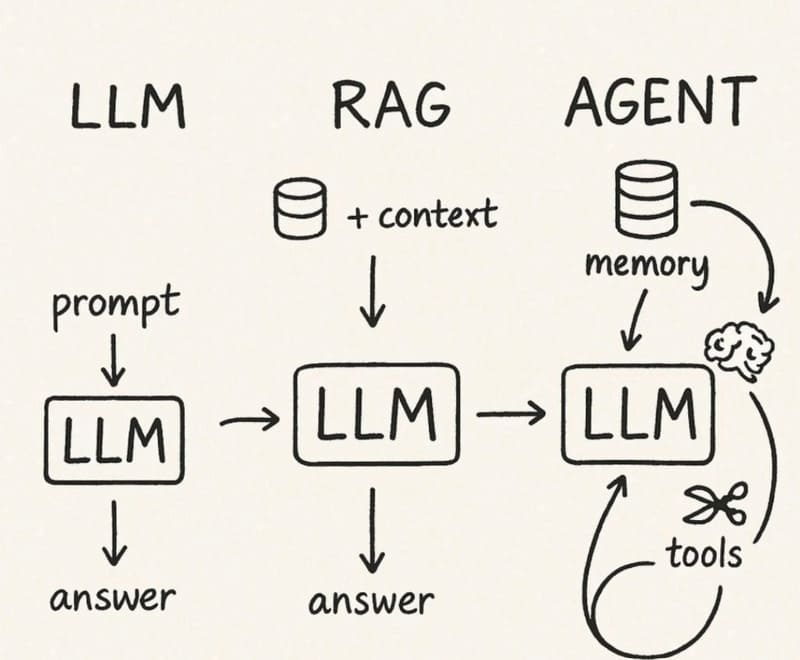
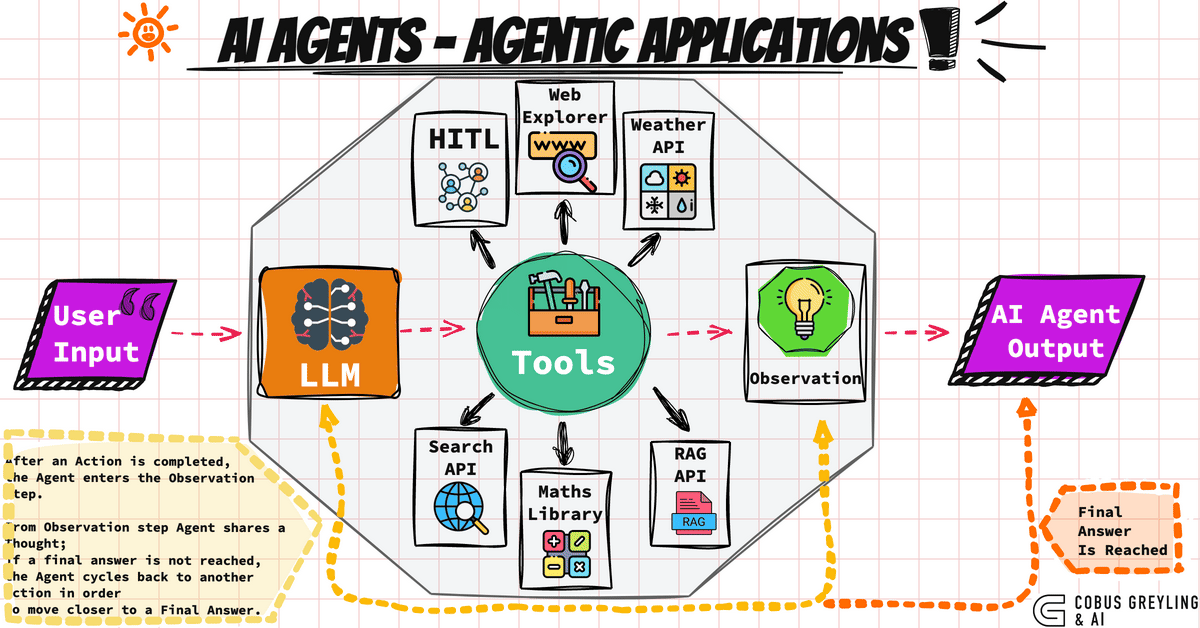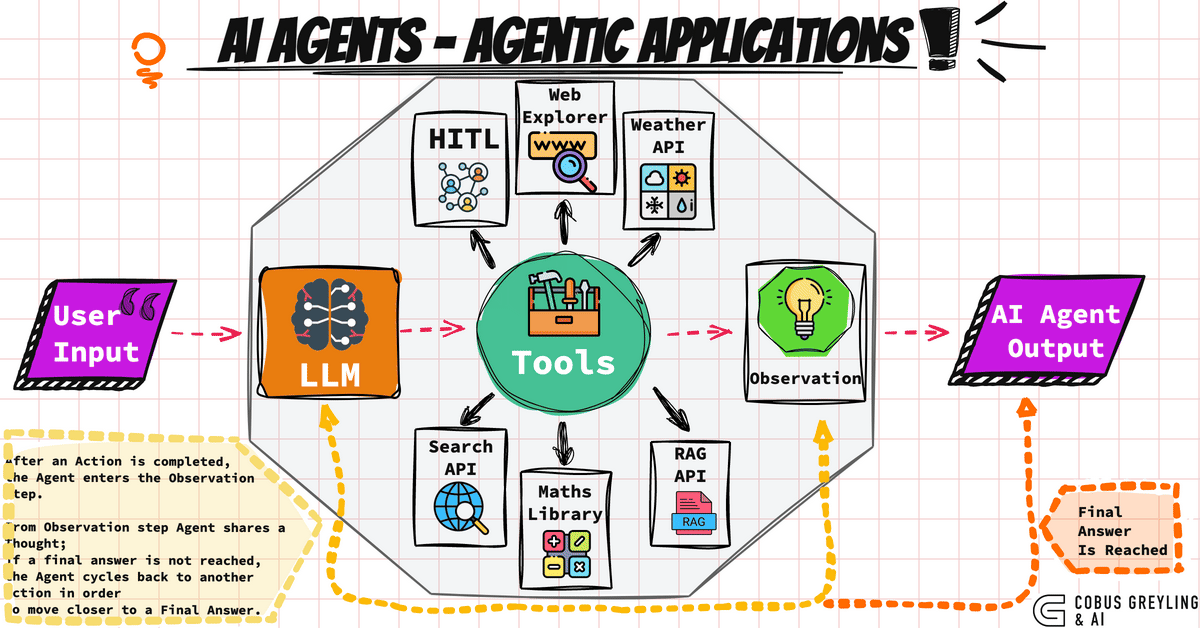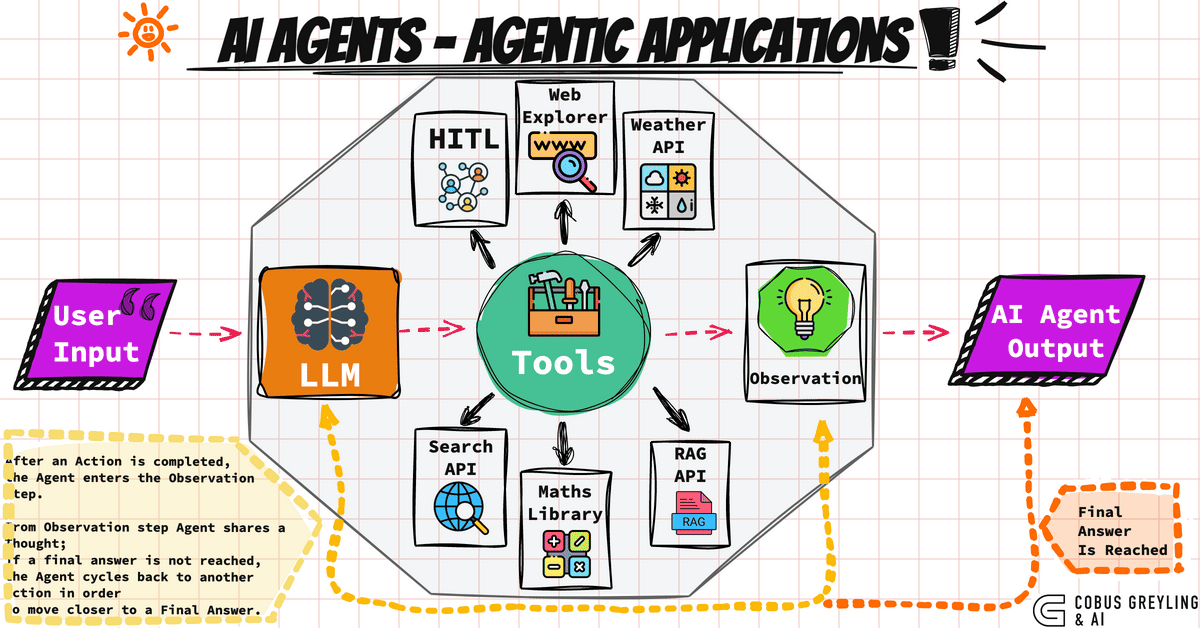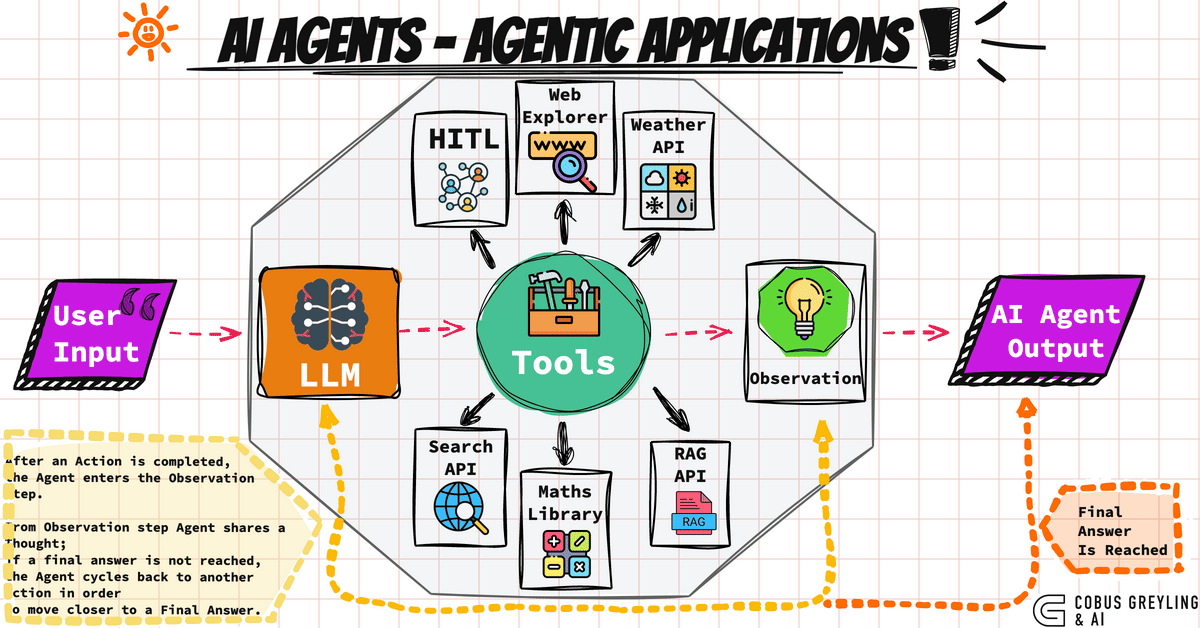
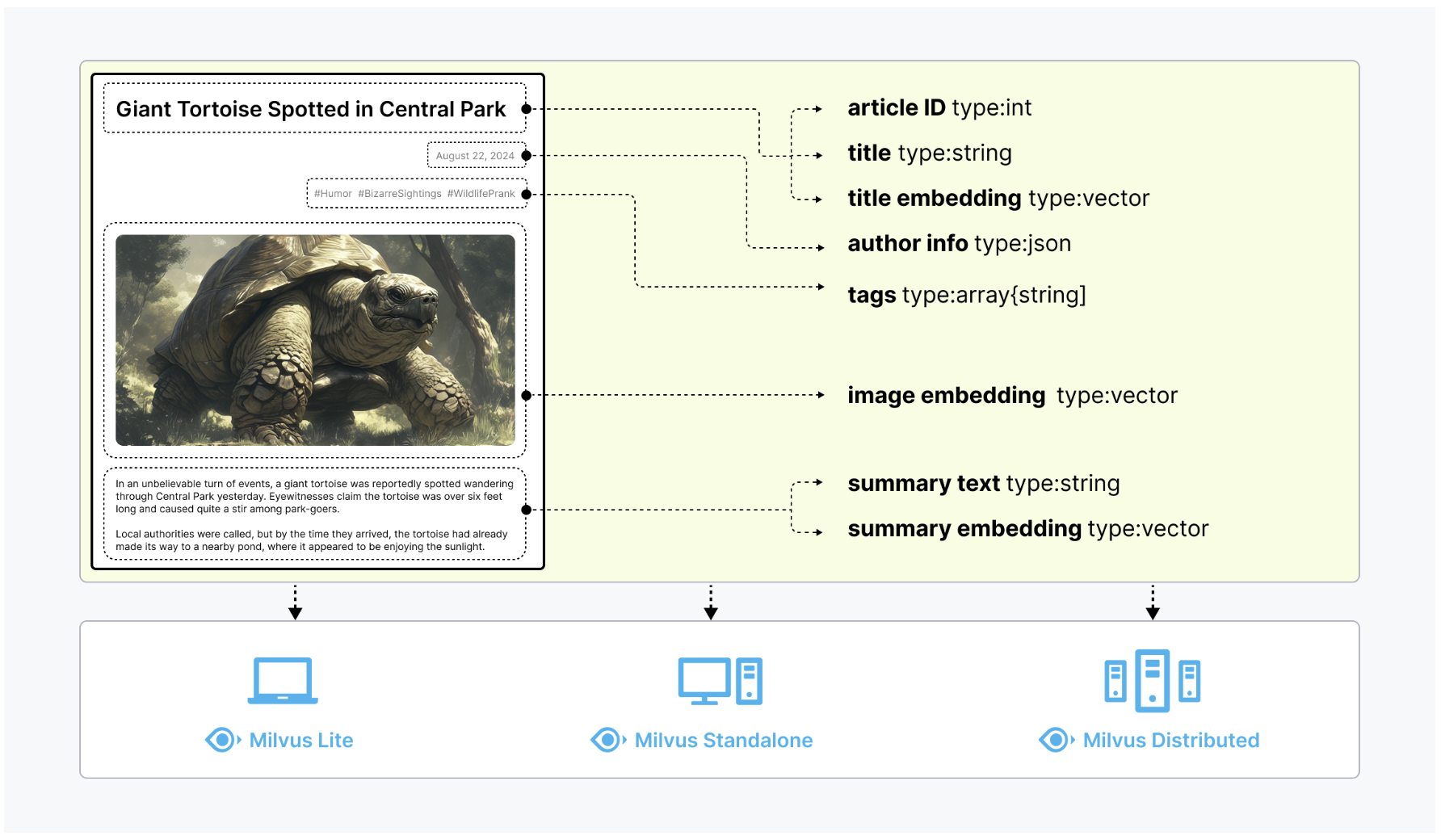
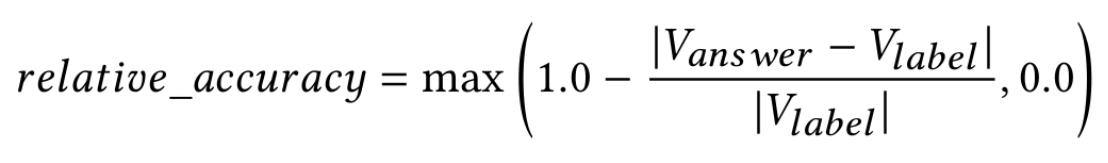AI Agent的核心意义,在于其能够解构复杂任务,自动学习与适应用户需求,从而不断提升服务质量。通过自然语言处理、情感分析、行为预测等技术,智能体能够形成个性化、精准的服务方案,满足不同用户的需求。例如,智能面试助手能够通过简历分析与行为数据,自动评估候选人,提供更加客观的面试评价;智能客服则可以在电商平台中自动解答用户咨询,大幅降低人工成本的同时提升客户满意度。
ChatTS: Aligning Time Series with LLMs via Synthetic Data for Enhanced Understanding and Reasoning 这篇文章是清华大学、字节跳动与必示科技三方共同创作而成。
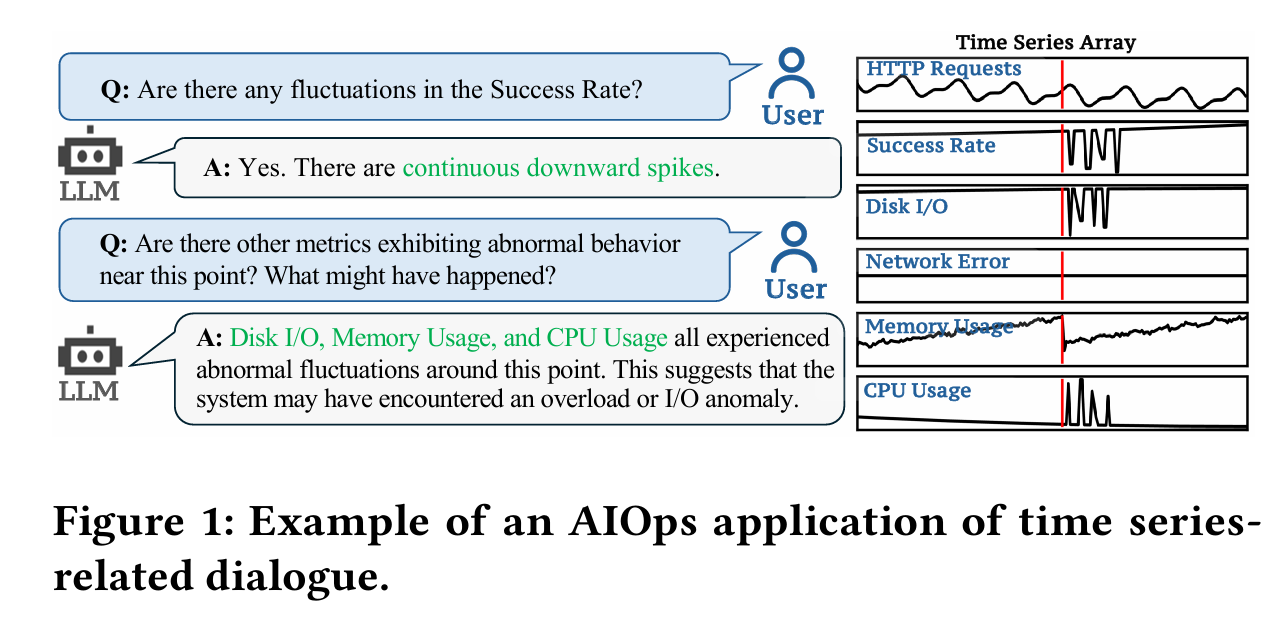
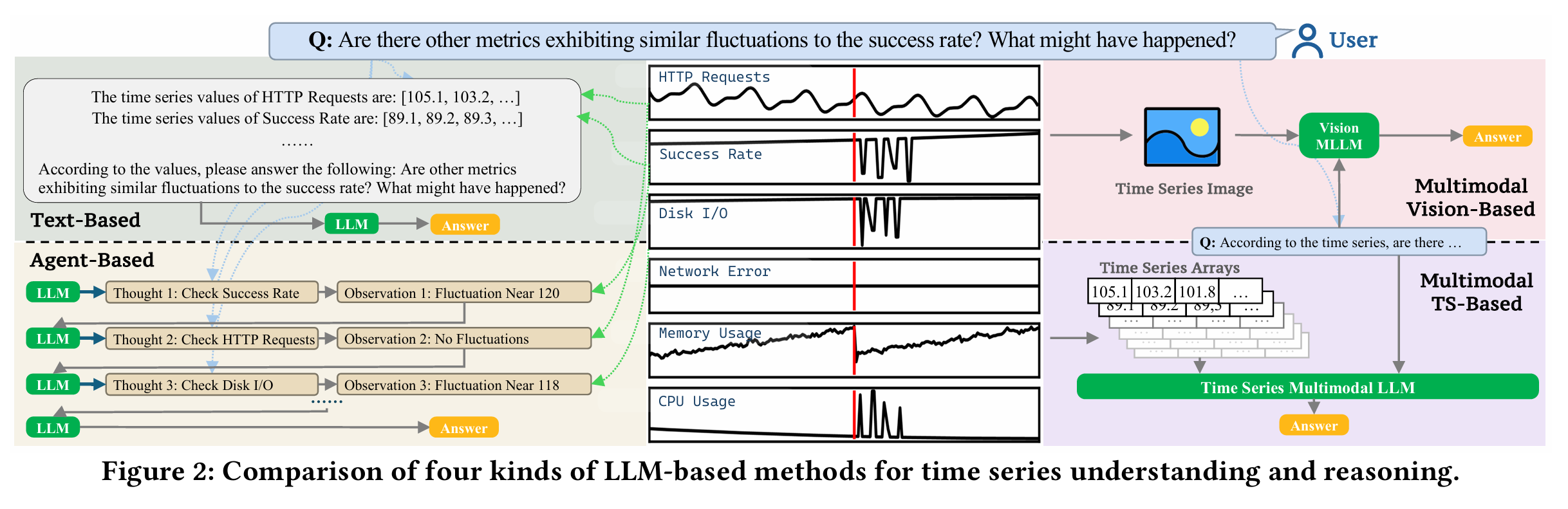
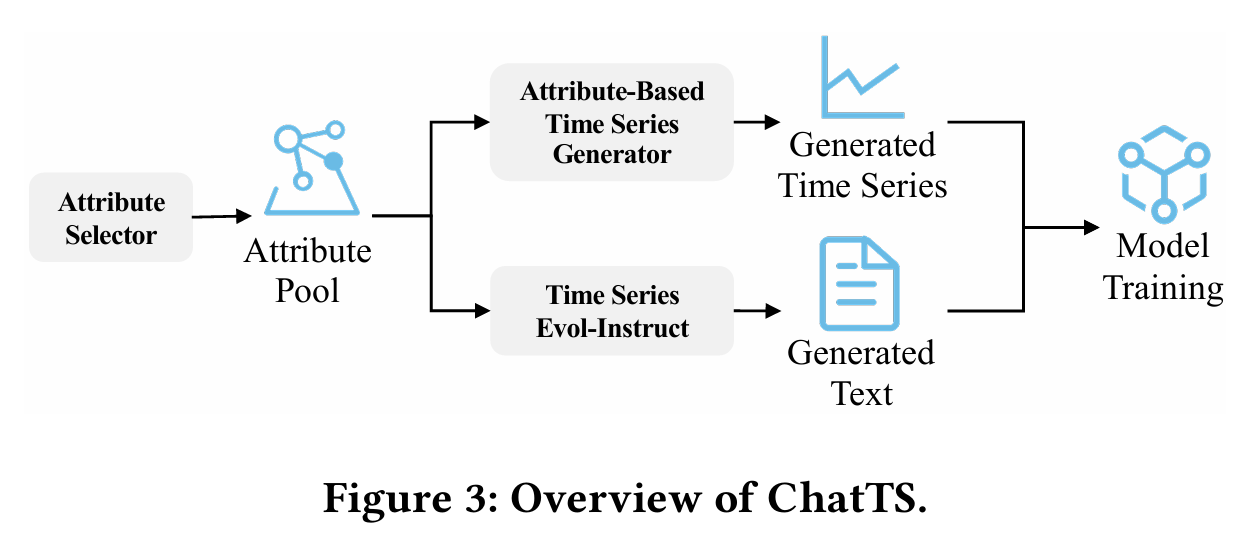
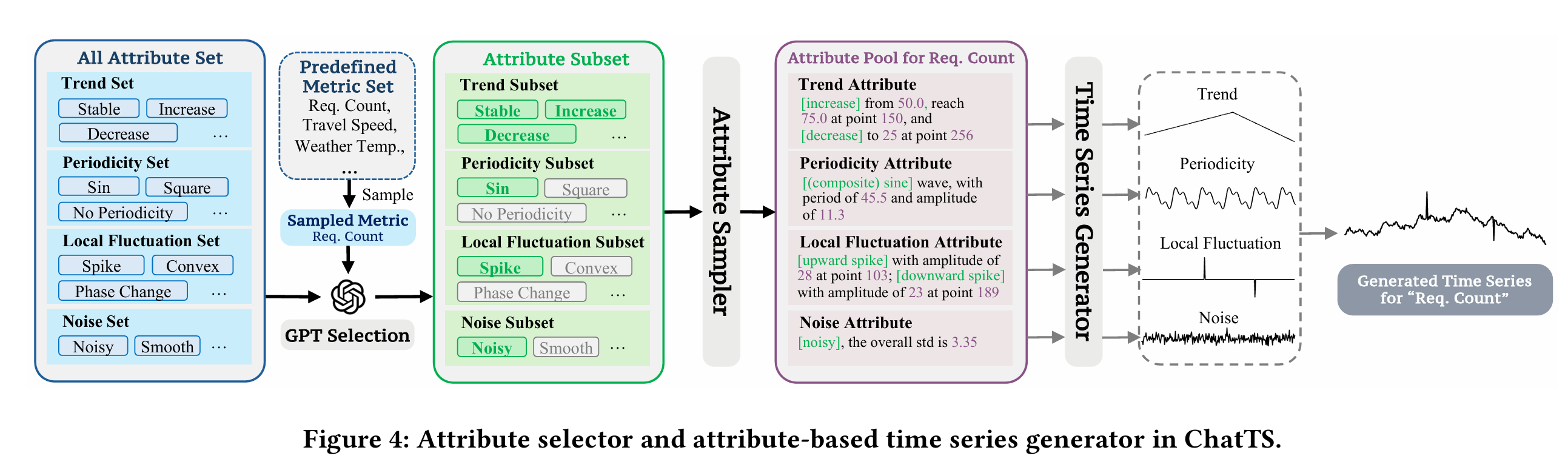
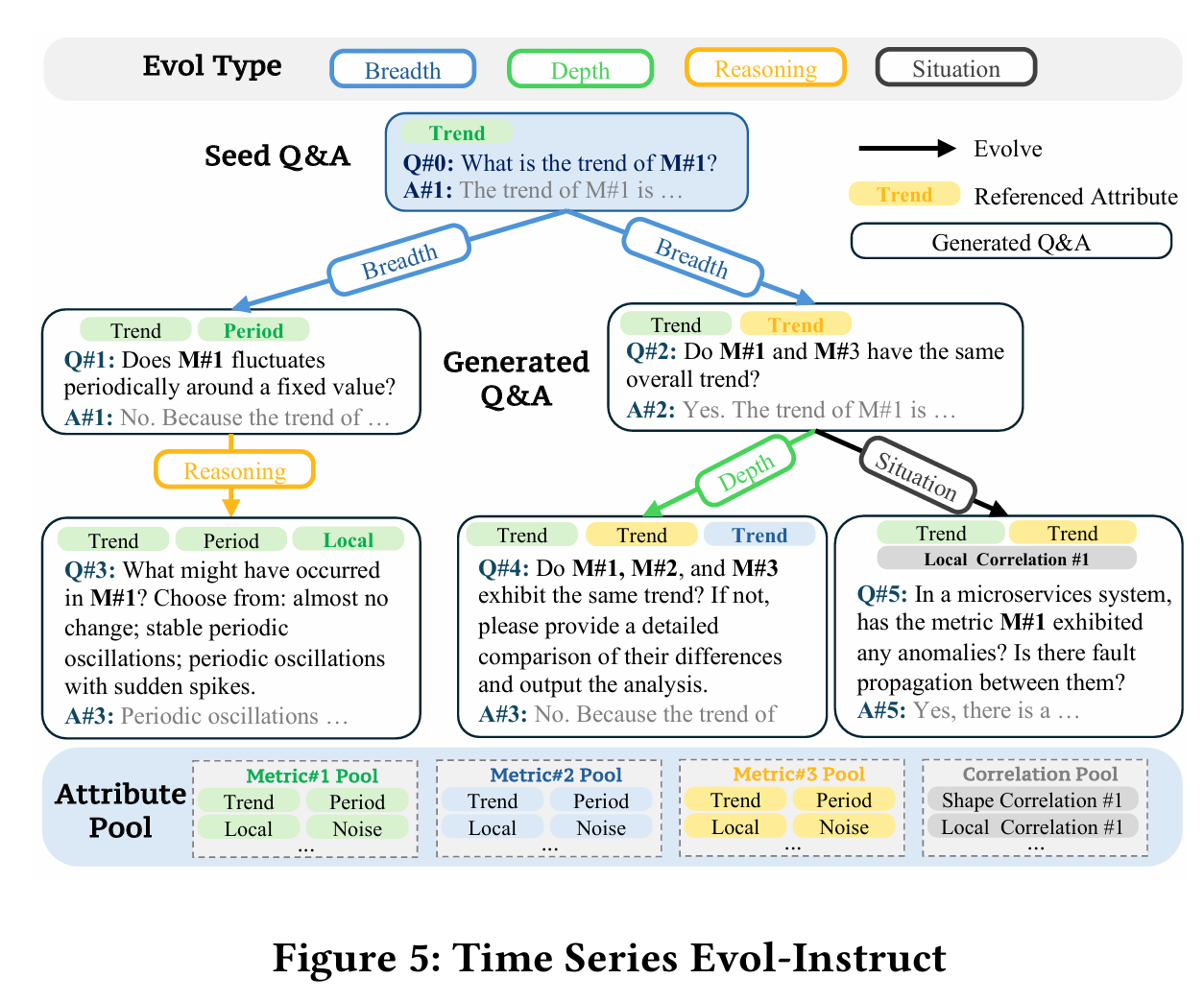
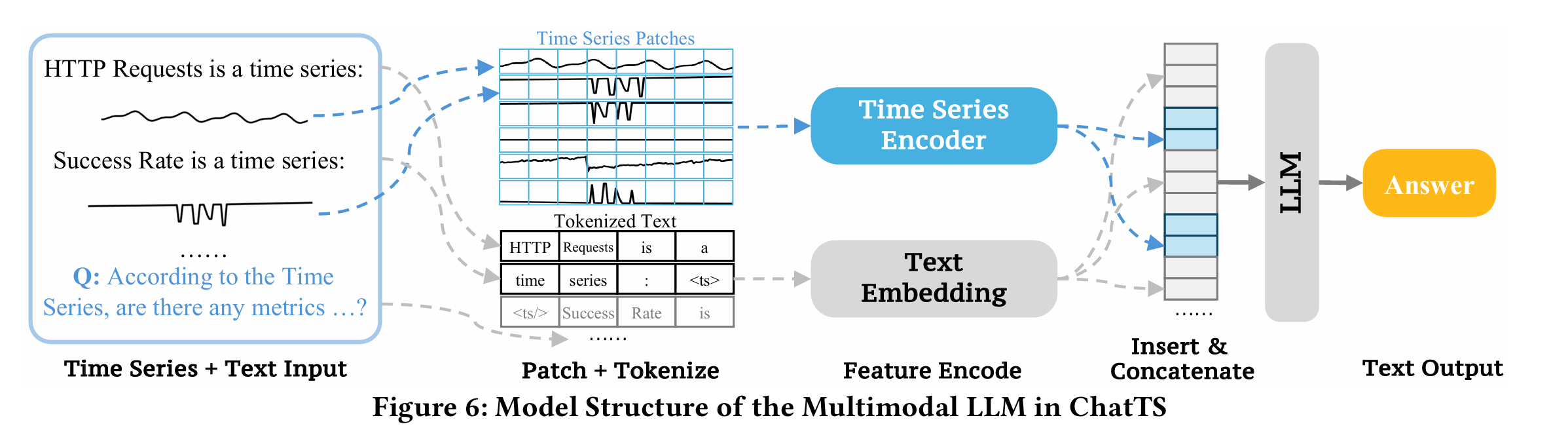
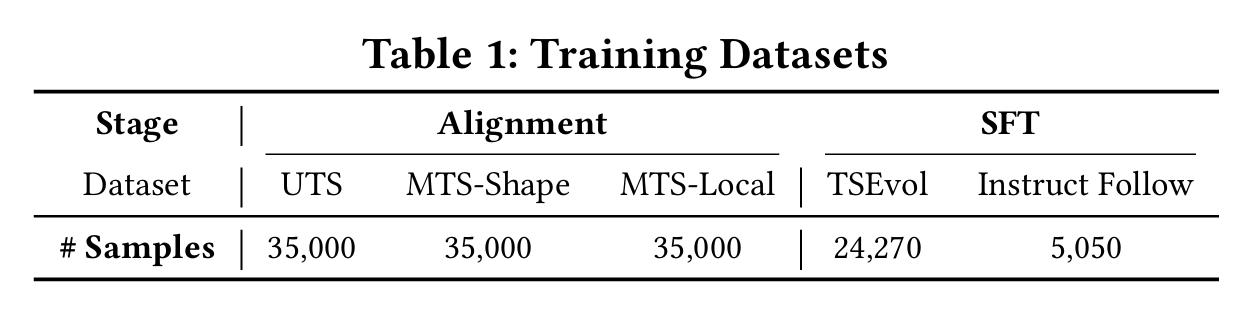
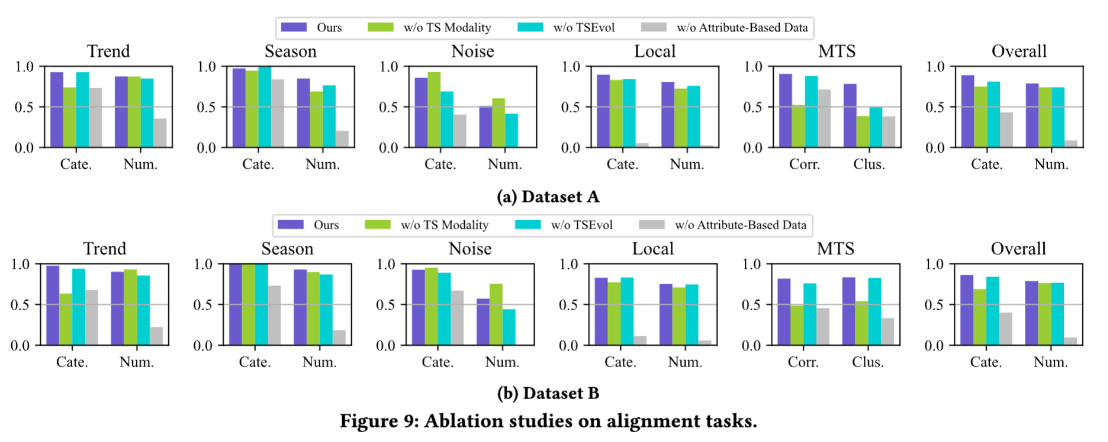
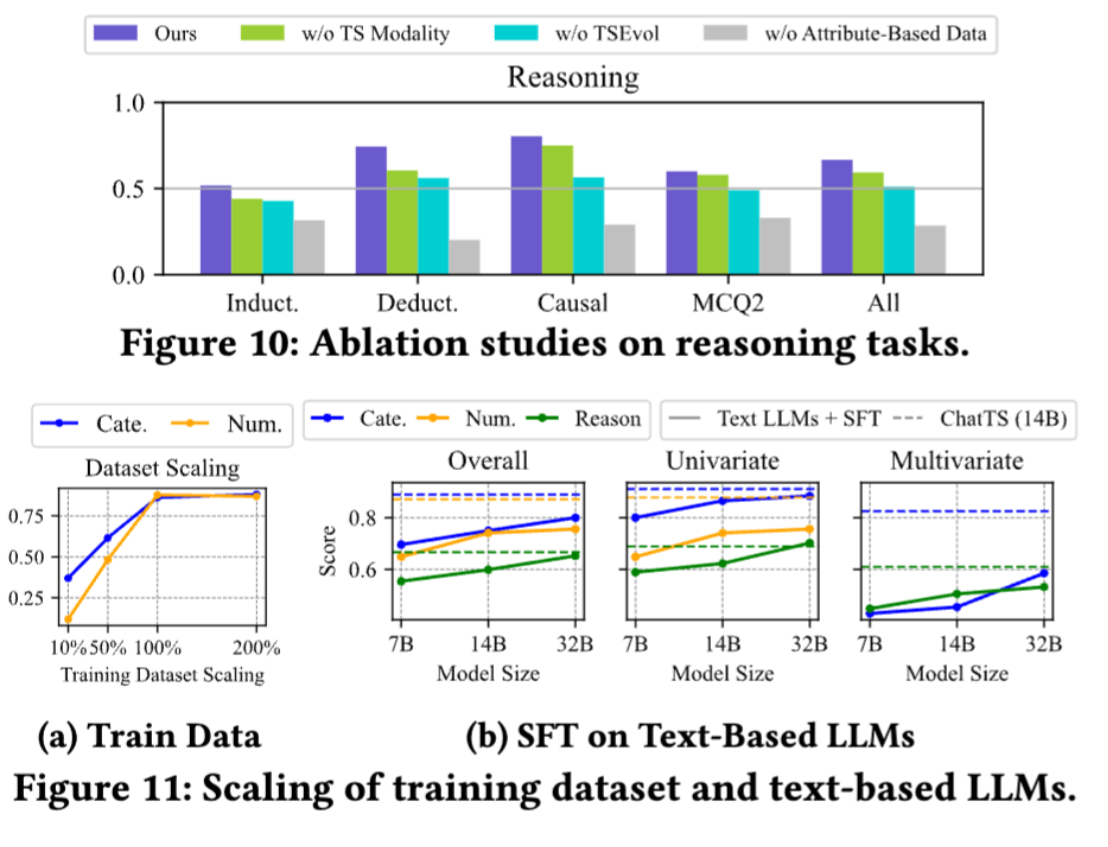
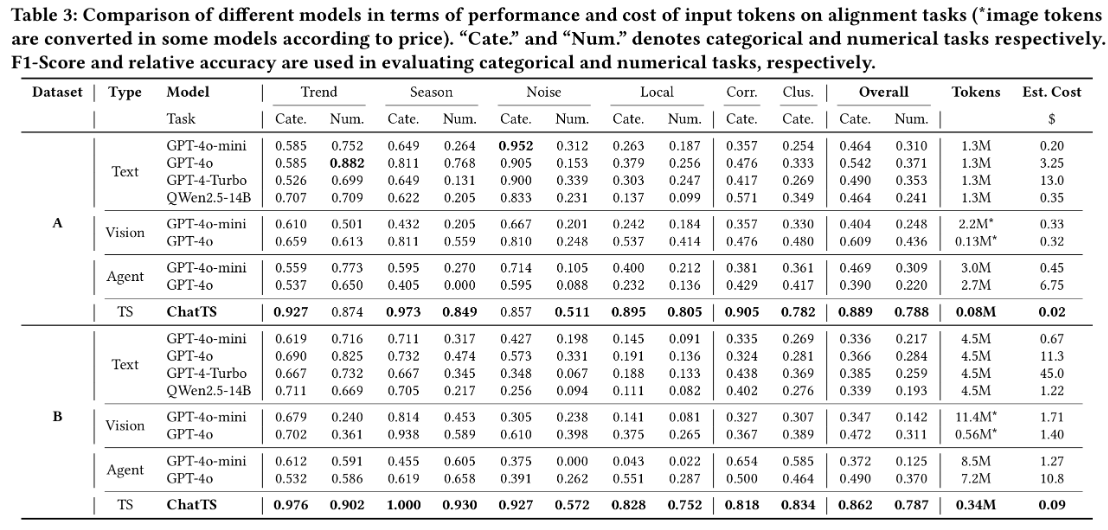
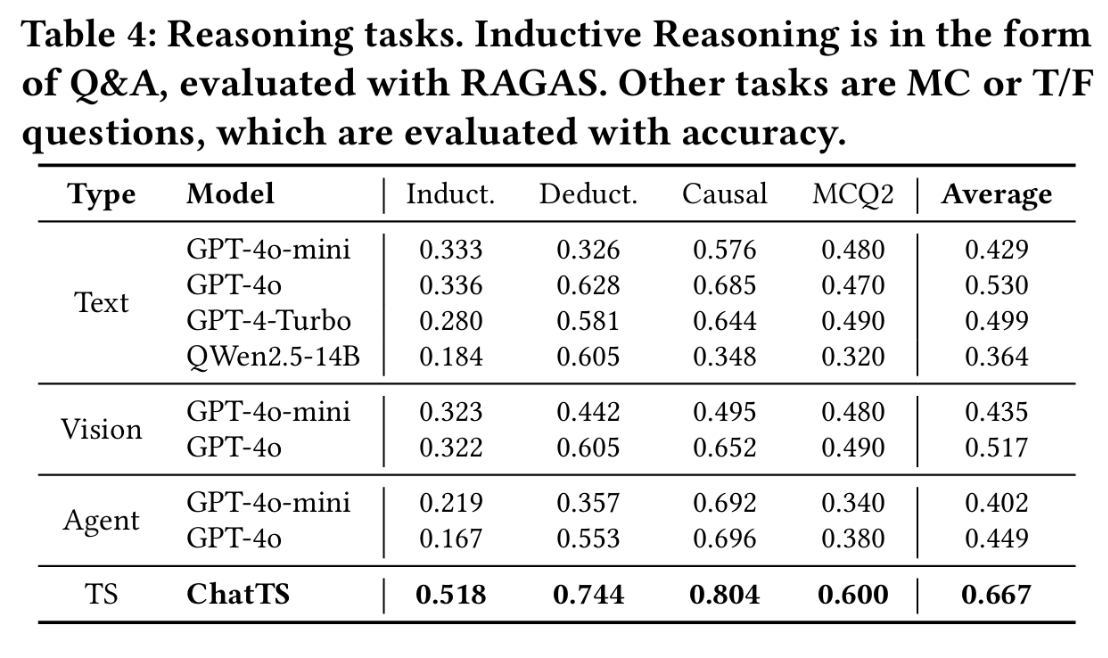
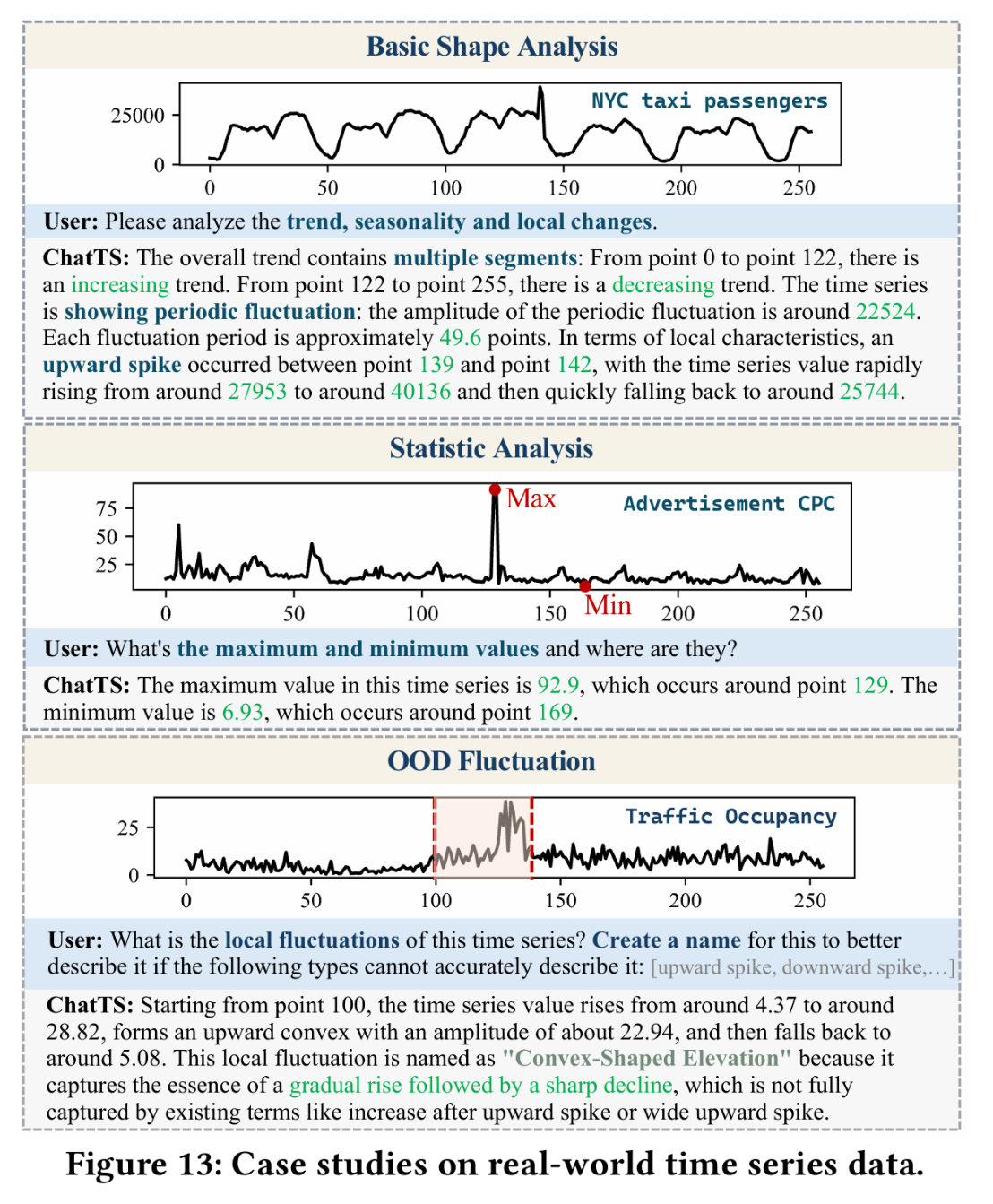
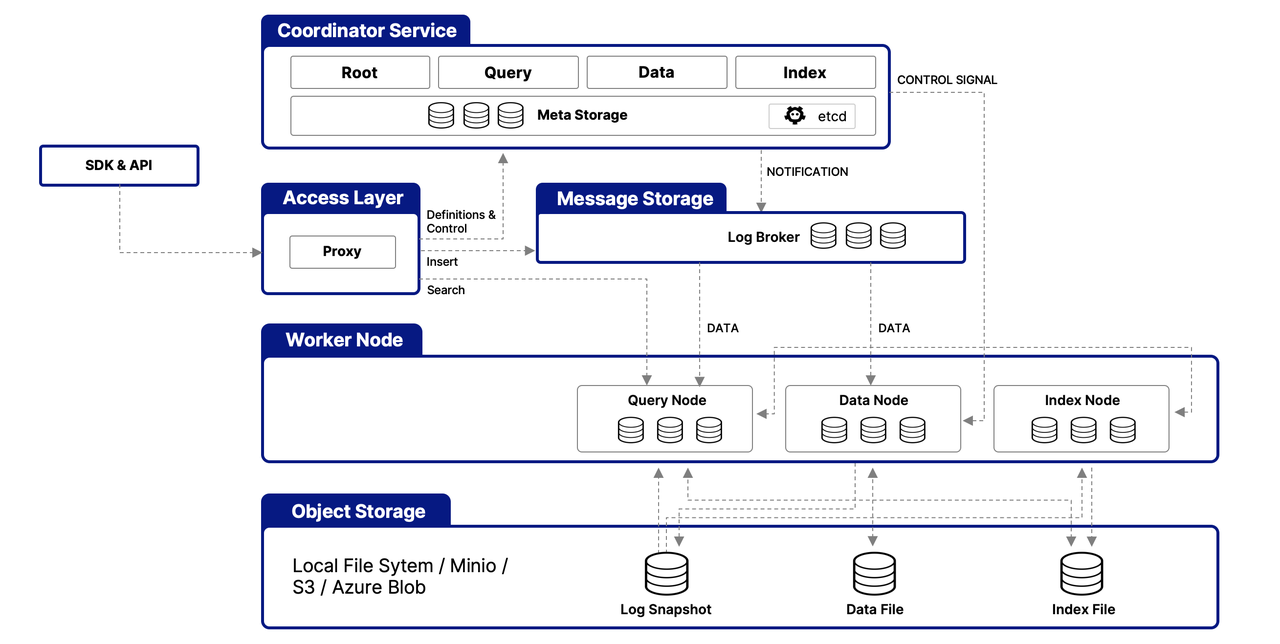
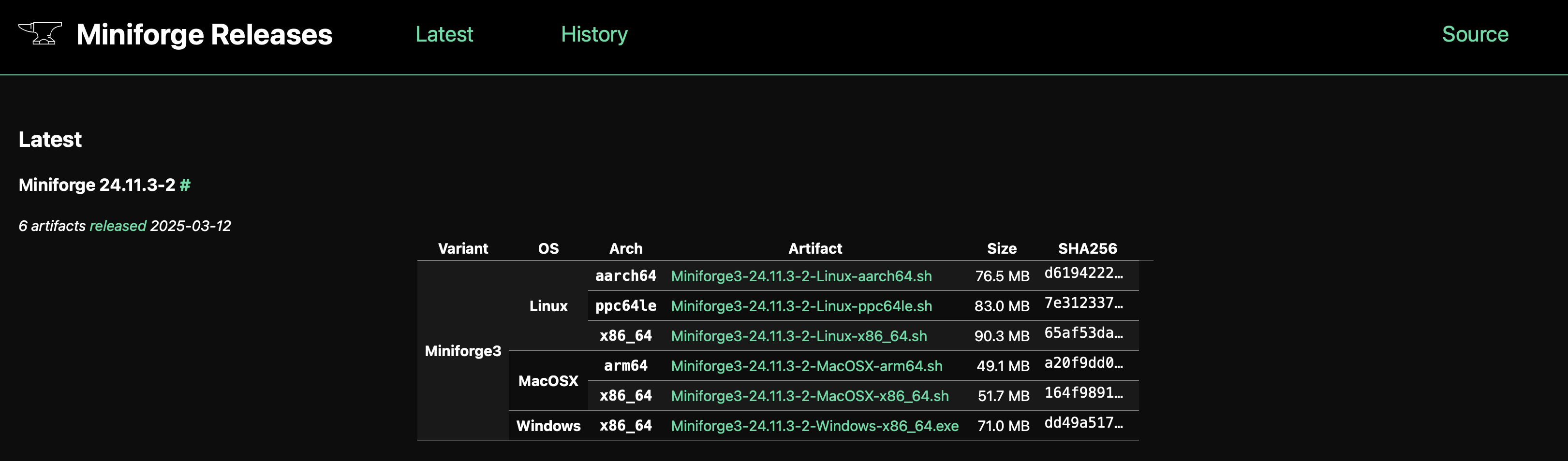
在实际的工作中,时间序列在运维领域中占据着非常重要的地位,尤其是近些年大语言模型(LLM)的发展,极大地推动了时间序列这一领域的发展。这篇论文介绍了一个叫做ChatTS的模型,它是专为时间序列分析设计的新型多模态大语言模型(MLLMs)。为缓解训练数据稀缺问题,作者们提出基于属性的合成时间序列生成方法,可自动生成具有详细属性描述的时序数据。同时,作者们创新性地提出时间序列演化式指令生成方法(Time Series Evol-Instruct),通过生成多样化时序问答对来增强模型的推理能力。ChatTS是首个以多元时间序列作为输入,并进行理解和推理的时间序列多模态大语言模型,且完全基于合成的数据集微调。作者们在包含真实数据的基准数据集上开展评估,涵盖6项对齐任务和4项推理任务。
from transformers import AutoModelForCausalLM, AutoTokenizer, AutoProcessor
import torch
import numpy as np
# Load the model, tokenizer and processor
model = AutoModelForCausalLM.from_pretrained("./ckpt", trust_remote_code=True, device_map=0, torch_dtype='float16')
tokenizer = AutoTokenizer.from_pretrained("./ckpt", trust_remote_code=True)
processor = AutoProcessor.from_pretrained("./ckpt", trust_remote_code=True, tokenizer=tokenizer)
# Create time series and prompts
timeseries = np.sin(np.arange(256) / 10) * 5.0
# 构造异常的时间序列取值
timeseries[100:] -= 10.0
prompt = f"I have a time series length of 256: <ts><ts/>. Please analyze the local changes in this time series."
# Apply Chat Template
prompt = f"<|im_start|>system\nYou are a helpful assistant.<|im_end|><|im_start|>user\n{prompt}<|im_end|><|im_start|>assistant\n"
# Convert to tensor
inputs = processor(text=[prompt], timeseries=[timeseries], padding=True, return_tensors="pt")
# Move to GPU
inputs = {k: v.to(0) for k, v in inputs.items()}
# Model Generate
outputs = model.generate(**inputs, max_new_tokens=300)
print(tokenizer.decode(outputs[0][len(inputs['input_ids'][0]):], skip_special_tokens=True))
如果是使用vLLM推理的话,可以参考这份代码:
import chatts.vllm.chatts_vllm
from vllm import LLM, SamplingParams
# Load the model
language_model = LLM(model="./ckpt", trust_remote_code=True, max_model_len=ctx_length, tensor_parallel_size=1, gpu_memory_utilization=0.95, limit_mm_per_prompt={"timeseries": 50})
# Create time series (np.ndarray) and prompts (chat_templated applied)
ts1, ts2 = ...
prompt = ...
# Model Inference
outputs = language_model.generate([{
"prompt": prompt,
"multi_modal_data": {"timeseries": [ts1, ts2]}
}], sampling_params=SamplingParams(max_tokens=300))
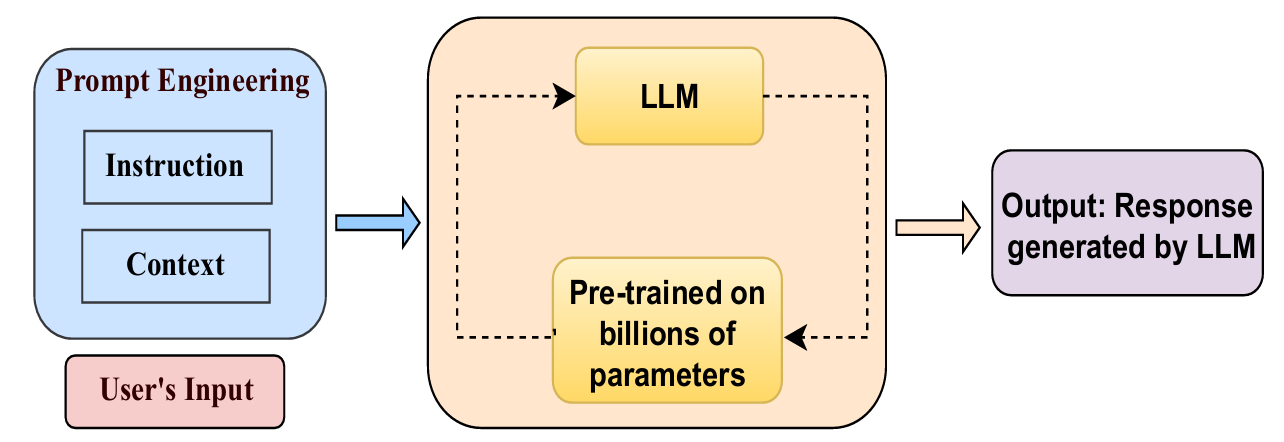
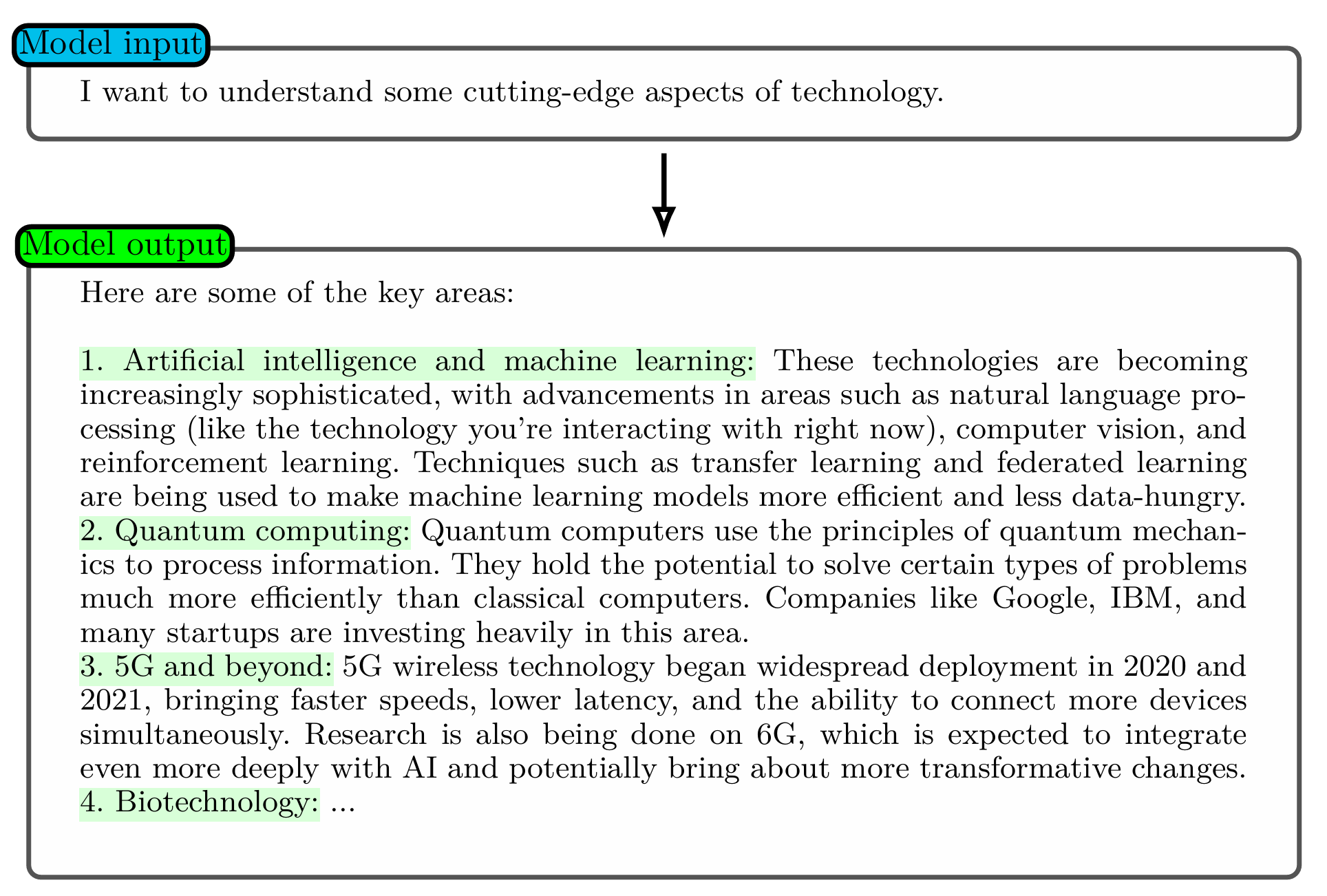
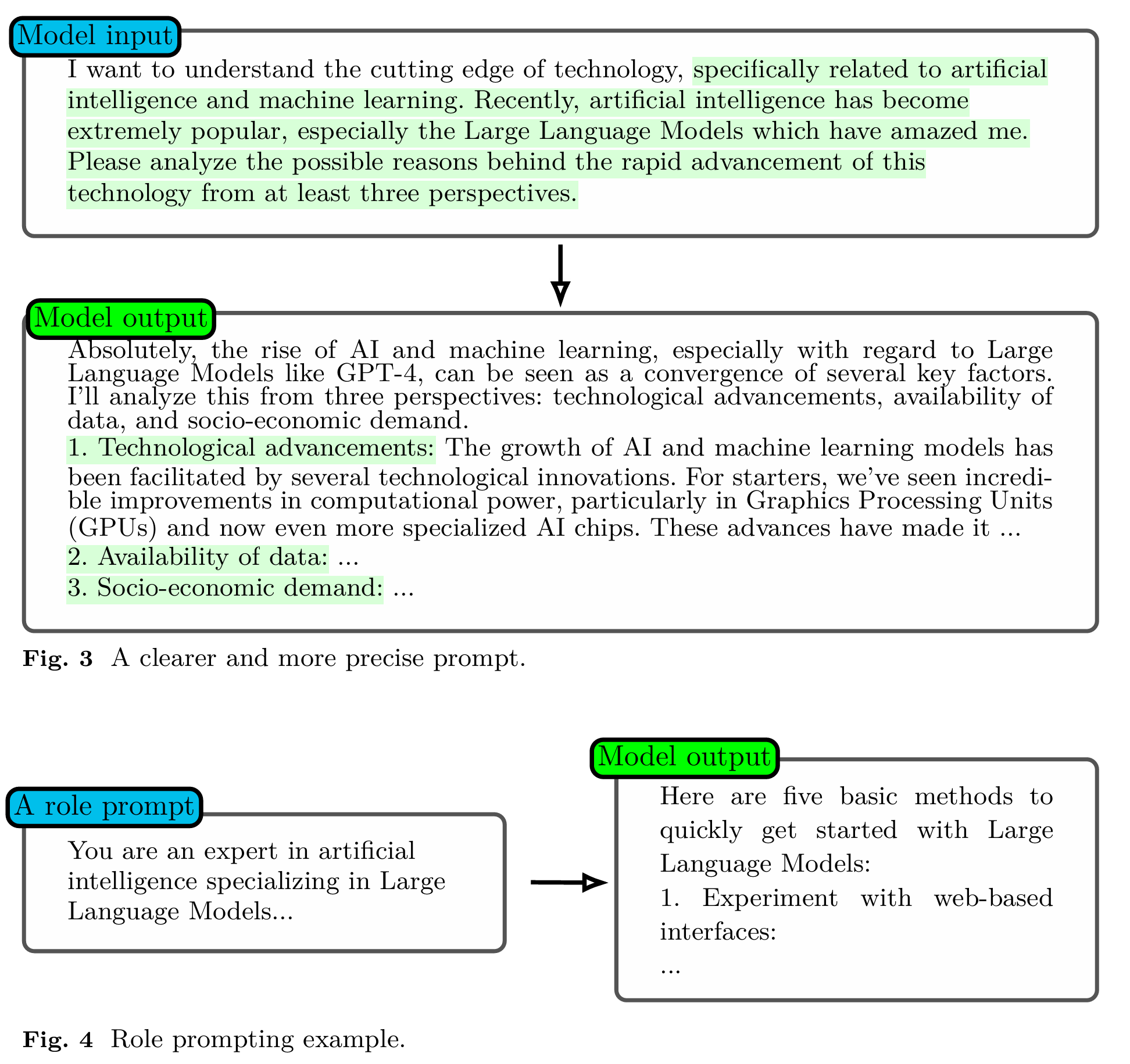
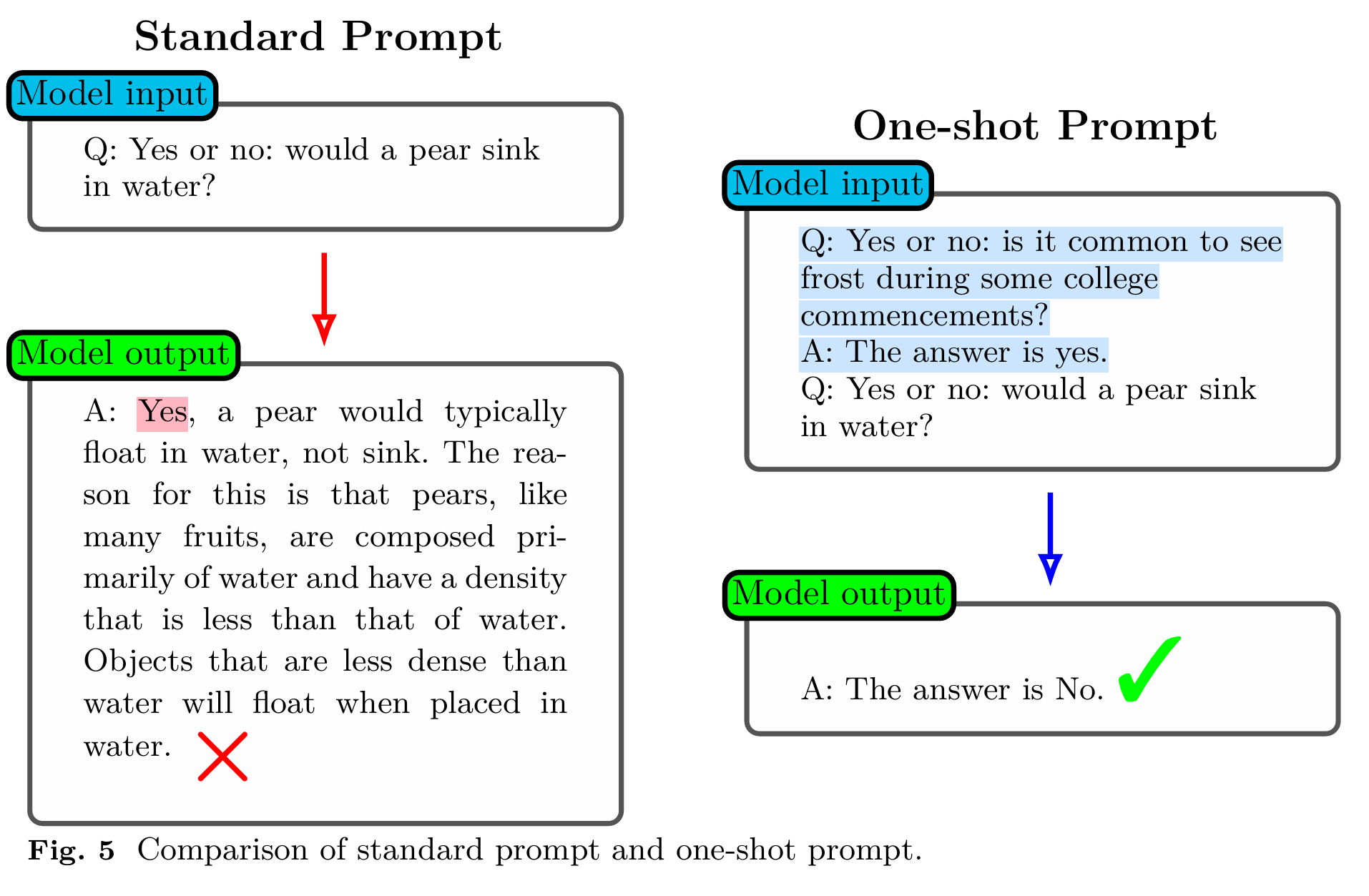
如今的提示词工程的入门也十分简单,直接就可以通过对话的方式与 AI 进行沟通和交流。形如下述格式,用户写一段文本信息或者一句简短的话,模型就可以输出相应的内容。
如果用户觉得上述内容不够完善,有两种常见的方式进行解决。第一种是提供更多的信息(A clearer and more precise prompt),包括上下文的消息、网站最新消息和更加精确的指令,当 AI 接收到这些消息和指令的时候,输出的内容就会更加完善与精确;第二种方法是角色扮演(Role prompting example),就是假设你是一个某某方向的专家,并且在输入的时候告知 AI 模型,AI 模型就会自动承担这个专家的角色并进行内容的输出。
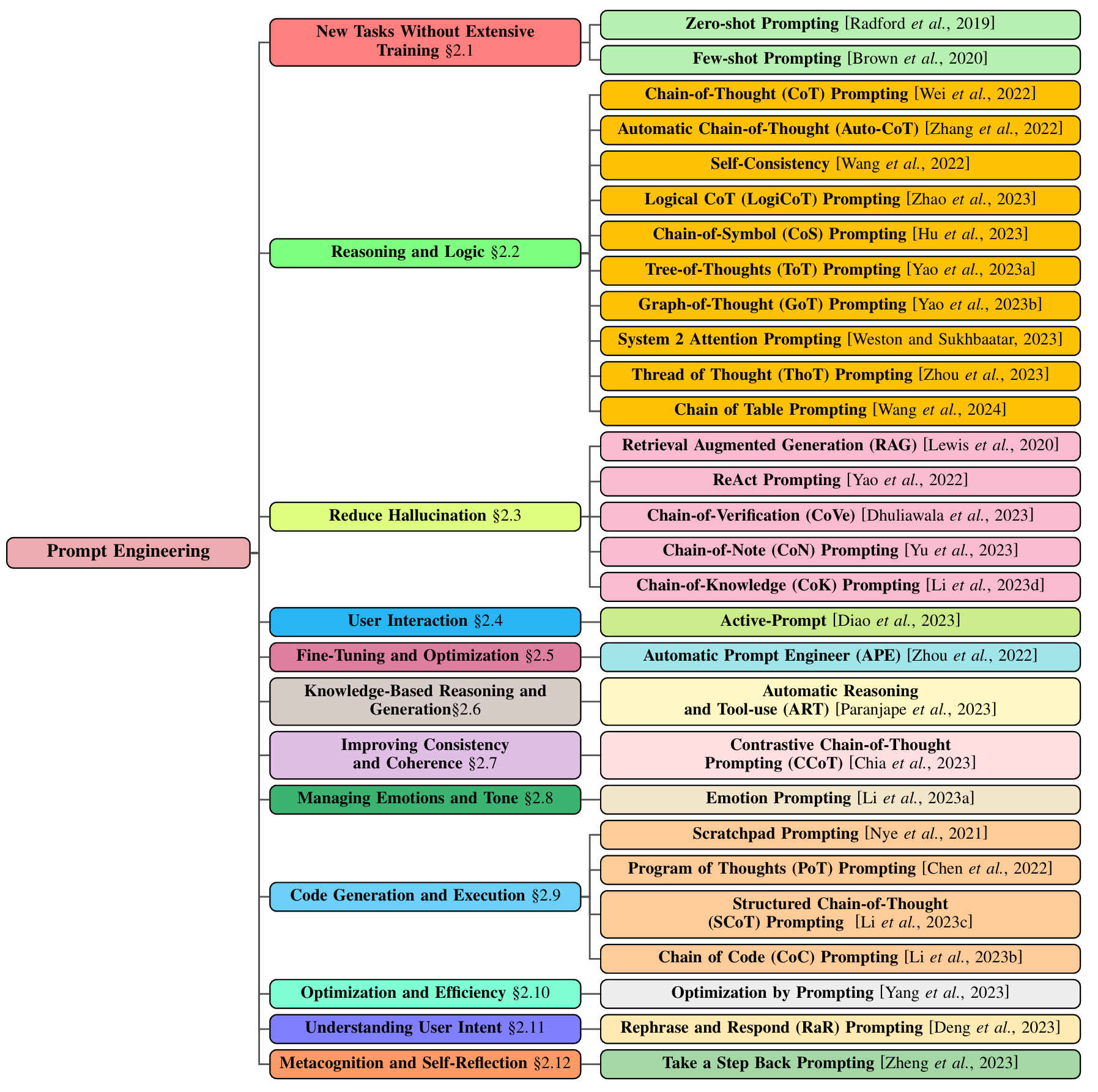
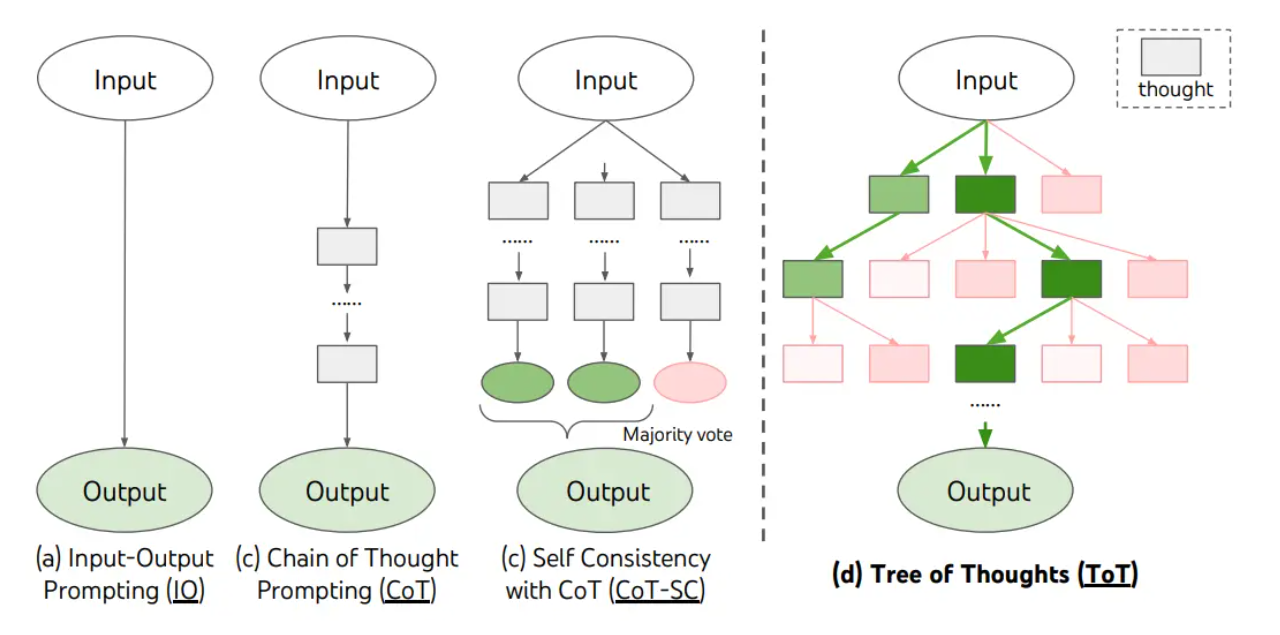
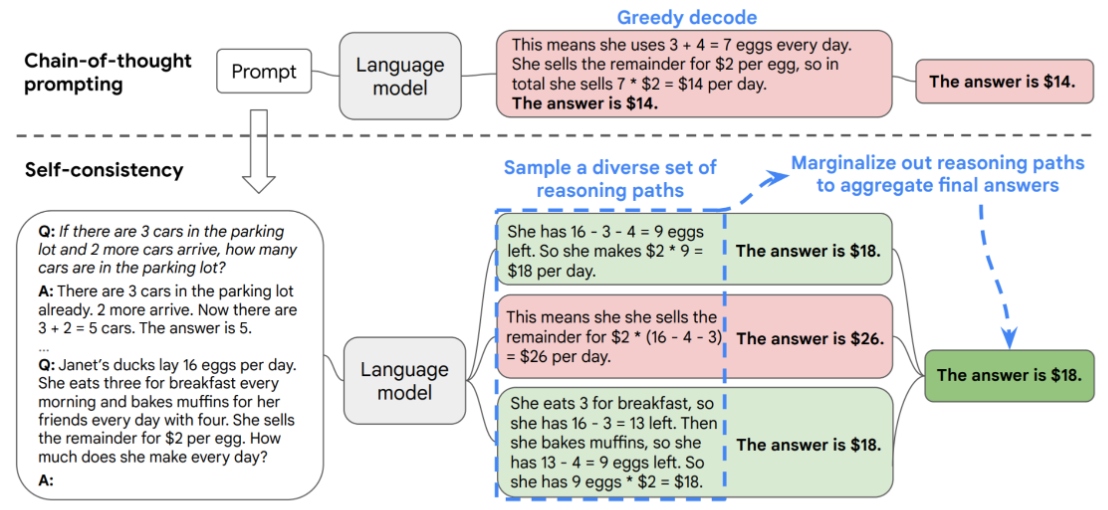
Chain of Thought(思维链) 是一种在人工智能尤其是大语言模型中使用的推理方法,目的是在通过逐步展开的推理过程来帮助模型解决复杂问题,特别是需要逻辑推理或多步骤计算的问题。传统的语言模型通常依赖于直接输入问题,并立即给出回答,但这有时会导致回答不够精确或存在错误。Chain of Thought方法则通过引导模型分步骤思考,逐渐推导出答案,从而提高推理的准确性和透明度。思维链(Chain of Thought)可以理解为逐步推理,它是通过将复杂问题拆解成多个小步骤,让模型逐步生成每个步骤的思考过程,最终得出正确的结论。这个过程类似于人类在解决问题时的思维过程:首先分析问题,考虑各种可能性,然后逐步推理出答案。
2.3.2 思维链的工作原理
问题分解:Chain of Thought方法要求模型将一个复杂问题分解成多个较为简单的子问题或推理步骤。每个步骤都帮助模型理清思路,逐步逼近最终答案。
传统的语言模型可能会直接给出“星期一”的答案,但它的推理过程可能并不清晰。使用Chain of Thought方法时,模型会像这样逐步推理:
第一步:今天是星期三。
第二步:明天是星期四。
第三步:后天是星期五。
第四步:再过两天是星期六。
第五步:再过一天是星期天。
最终,模型得出结论:五天后是星期一。
通过这种逐步推理,模型的思维过程变得更加透明,也更容易让人理解。
下面是一个标准的提示词输入模式:
下面是一个思维链(Chain of Thought)的提示词输入模式,在提示词中明确输入按步骤思考和解决。
2.4 思维树Tree of Thought
2.4.1 思维树的定义
Tree of Thought(思维树) 是一种新的推理方法,它在传统的Chain of Thought(思维链)基础上进一步扩展,旨在帮助大语言模型进行更复杂的推理和决策。与线性逐步推理的Chain of Thought不同,Tree of Thought通过将推理过程分支化,允许模型在多个可能的推理路径中进行探索,并根据不同的分支选择最佳路径,从而得到更加准确和丰富的答案。
Tree of Thought可以理解为一个多分支的推理过程,它在一个问题的解决过程中产生多个并行的推理路径,并通过评估这些路径来选择最优解。这种方法特别适合于复杂的决策问题、长时间推理过程或需要考虑多个可能性的问题。
相比之下,Chain of Thought是一种线性推理方法,每一步推理依赖于前一步的结果。而Tree of Thought通过“树形”结构,在推理过程中创建多个分支,允许模型在不同的路径中进行探索和评估。这种多路径的推理方式更贴近人类解决问题时的思维过程,人类在面对复杂问题时,往往会考虑多个解决方案,并根据实际情况选择最佳的路径。
2.4.2 思维树的工作原理
分支化推理: 在Tree of Thought中,模型会为每个推理步骤生成多个候选答案或路径。例如,在解决一个问题时,模型可能会产生不同的推理路径,每个路径代表着一种不同的推理思路。
在代码生成方面,提示词技术已成为智能编程助手的核心能力之一。开发者可通过自然语言描述需求,模型生成相应的函数、脚本、接口文档甚至是测试用例。例如,“用 Python 实现快速排序”这样的简单提示词,就能引导模型生成完整、可运行的排序程序。这种能力不仅适用于初学者的学习辅助,也在资深开发者的代码补全与重构工作中提供了高效支持,尤其在 API 使用、跨语言翻译和单元测试生成等任务中效果显著。
例如,我们要求LLM输出一段简单的Python代码,就可以得到如下的案例:
def fibonacci(n):
# 生成斐波那契数列
sequence = []
a, b = 0, 1
for _ in range(n):
sequence.append(a)
a, b = b, a + b
return sequence
# 输入要生成的项数
n = int(input("请输入斐波那契数列的项数: "))
result = fibonacci(n)
# 打印结果
print(f"前 {n} 项斐波那契数列:")
print(result)
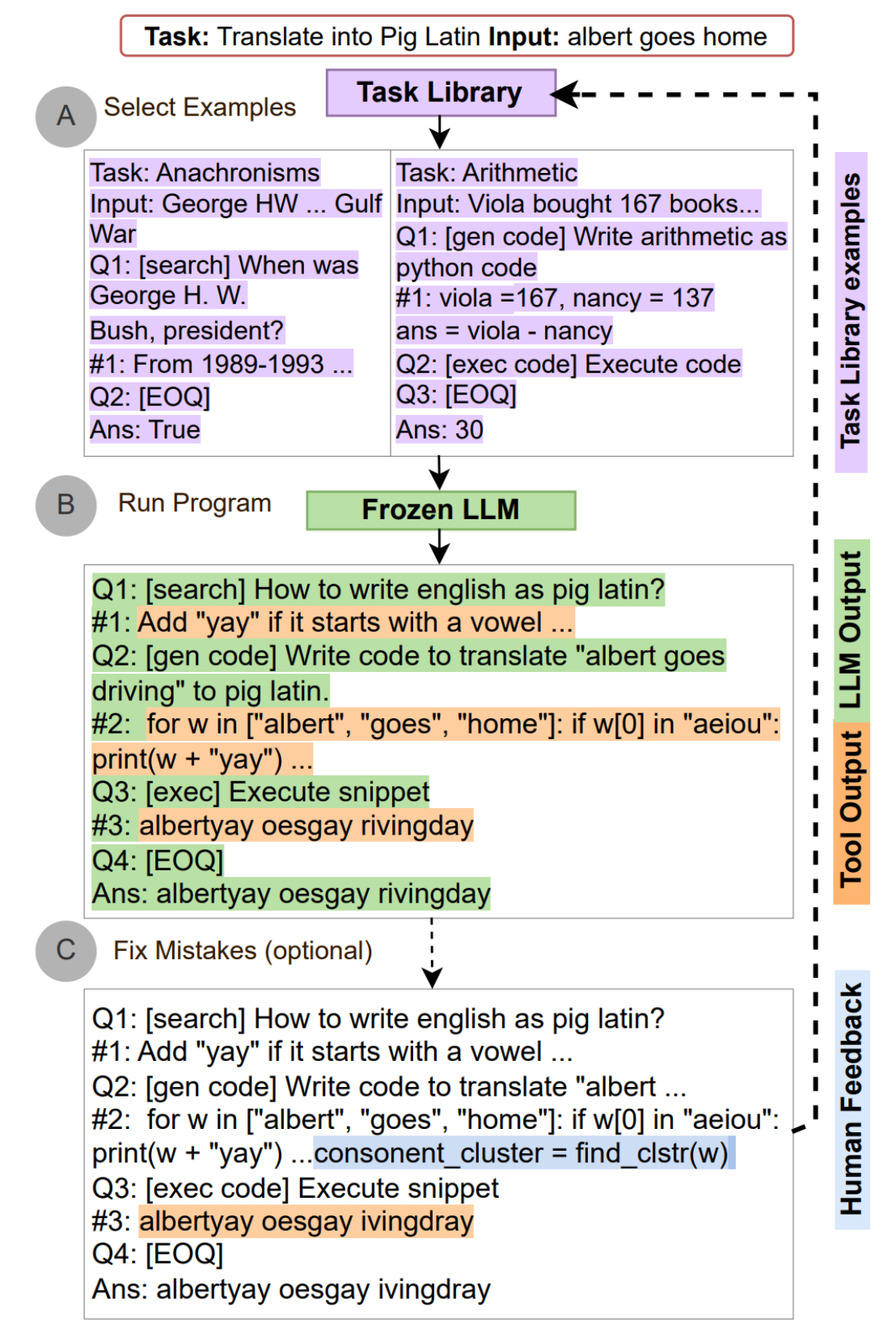
自动推理并使用工具:Paranjape, Bhargavi, et al. “Art: Automatic multi-step reasoning and tool-use for large language models.” arXiv preprint arXiv:2303.09014 (2023).
ReAct:Yao, Shunyu, et al. “React: Synergizing reasoning and acting in language models.” International Conference on Learning Representations (ICLR). 2023.
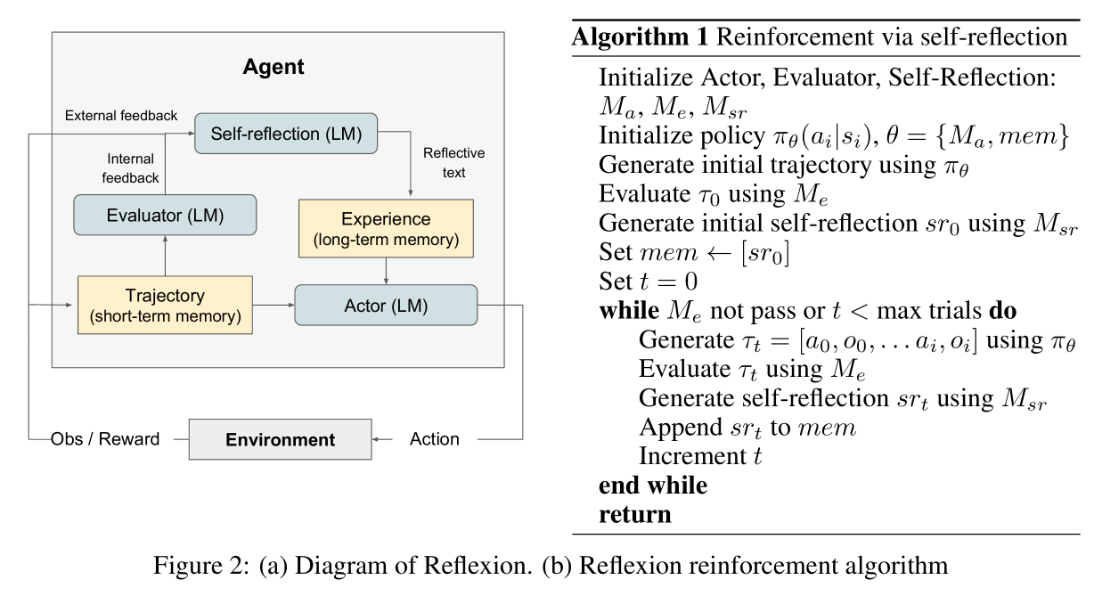
Reflexion:Shinn, Noah, et al. “Reflexion: Language agents with verbal reinforcement learning.” Advances in Neural Information Processing Systems 36 (2023): 8634-8652.
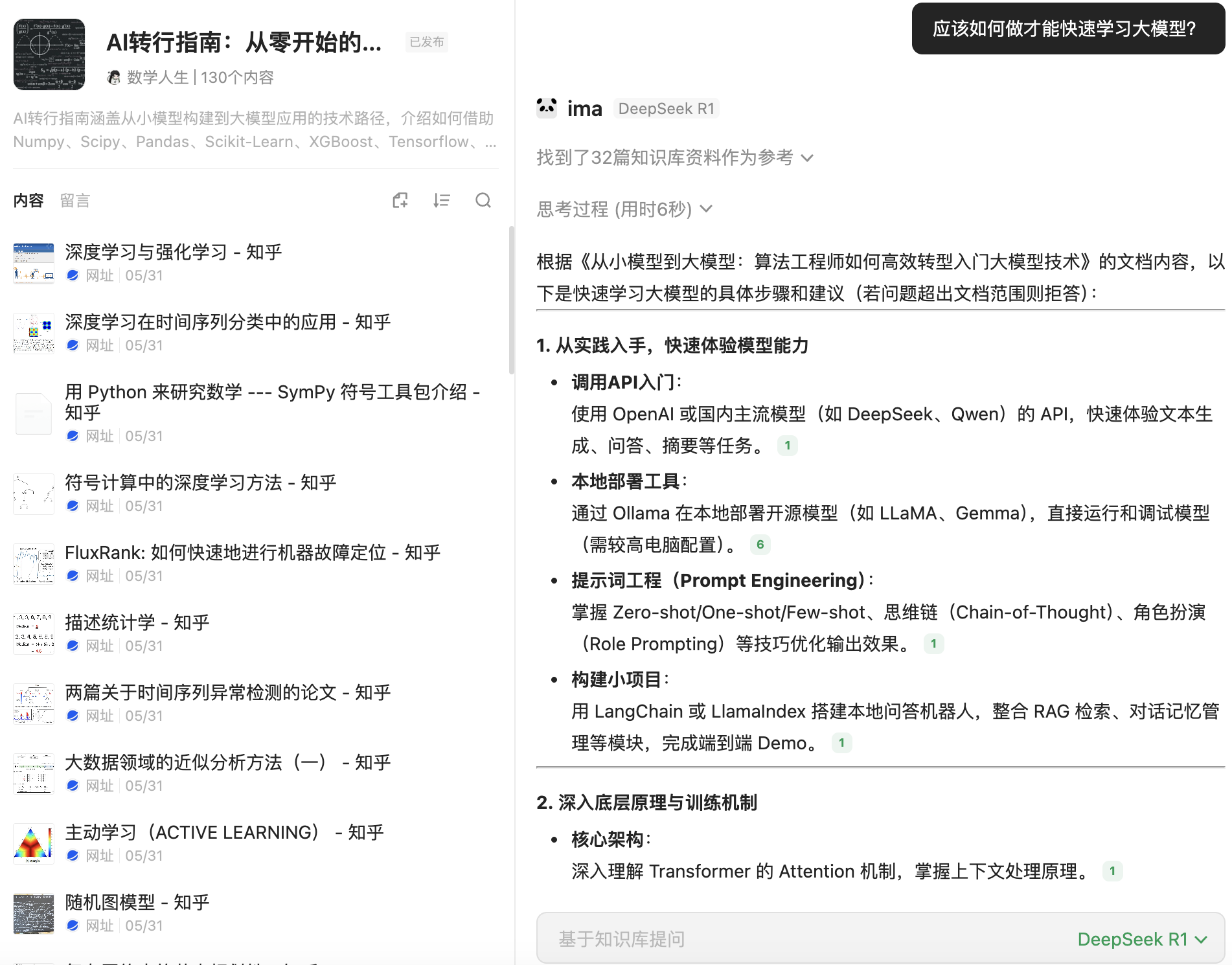
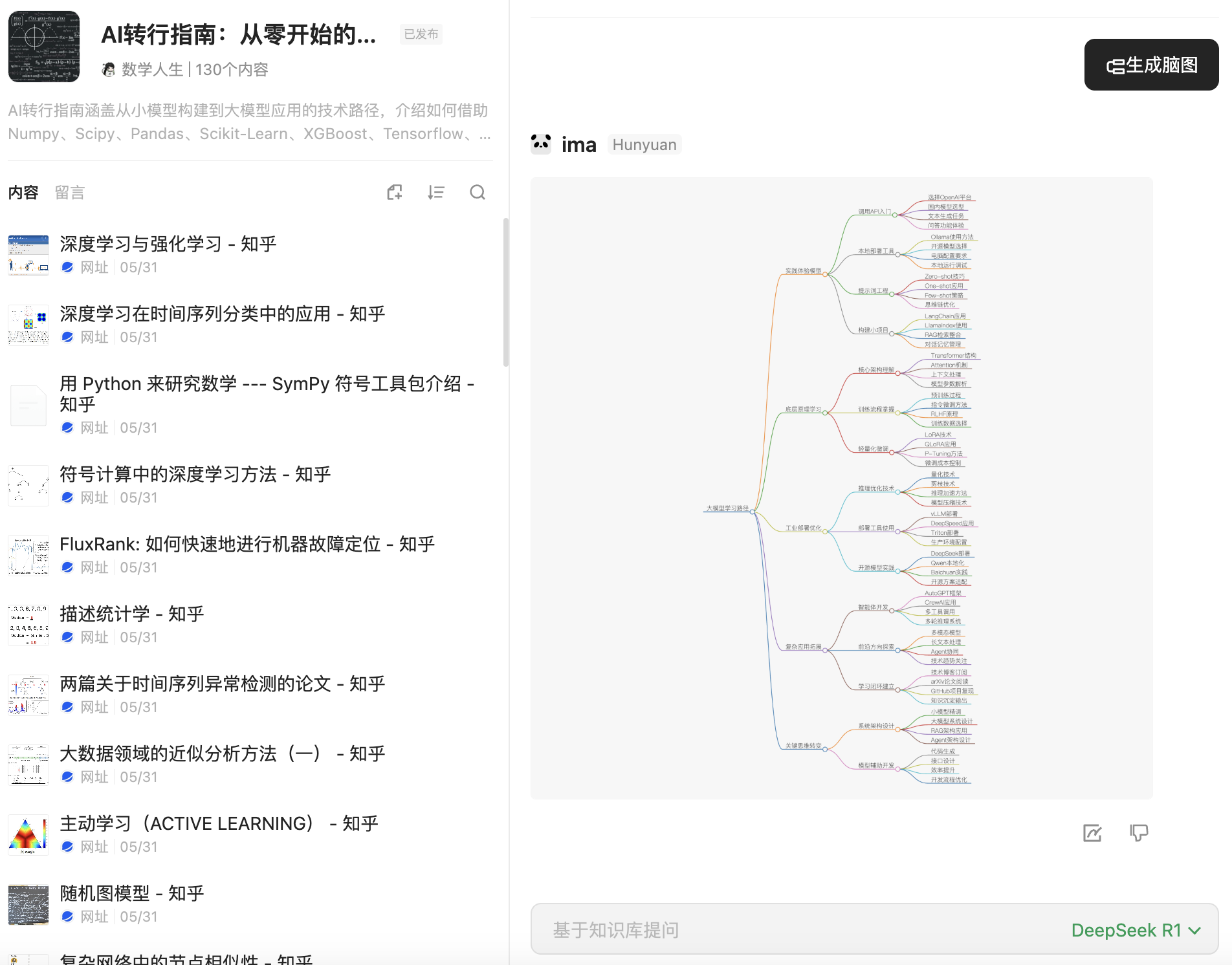
近年来,大语言模型如 GPT、LLaMA、Claude、Gemini、DeepSeek 等在自然语言处理任务中展现出前所未有的能力,已经成为技术界与产业界关注的核心。从算法模型到软件产品,从科研论文到应用落地,大模型不仅改变了人们对人工智能的认知,也正在重塑整个技术生态。在任何行业都面临着这场来自于 AI 的挑战,无论是互联网、新能源汽车还是农业,都有着许多实际的场景等待 AI 的接入。对于有机器学习和深度学习基础,甚至在工业界具备小模型实践经验的算法工程师而言,进入大模型的世界,不仅是一场技术能力的升级,更是一场思维范式的转变,不及时转型大模型的话,可能未来在市场中的就业前景会比较差。
对于有小模型研发经验的工程师来说,大模型并不是从零开始的挑战。你原有的数据处理能力、模型评估习惯、工程部署经验,依然在大模型系统中非常有价值。唯一需要转变的,是工程思维的广度和系统设计的复杂度。在大模型时代,更多的是系统级 AI 架构思维,而不仅是模型本身的精调。与此同时,大模型也能反过来助力你的日常开发,从代码生成到接口设计、测试覆盖,模型本身可以成为你高效工作的伙伴。
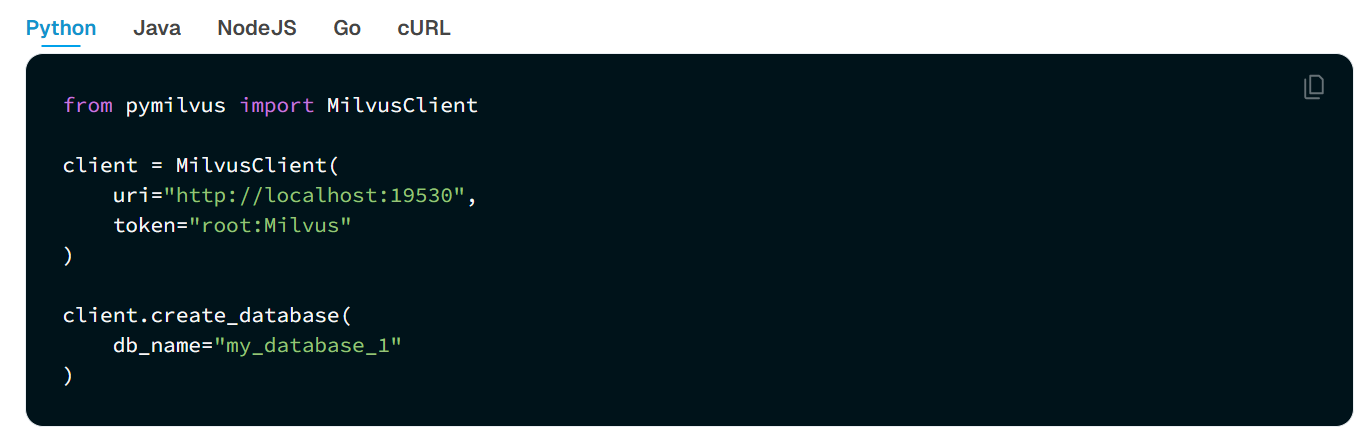
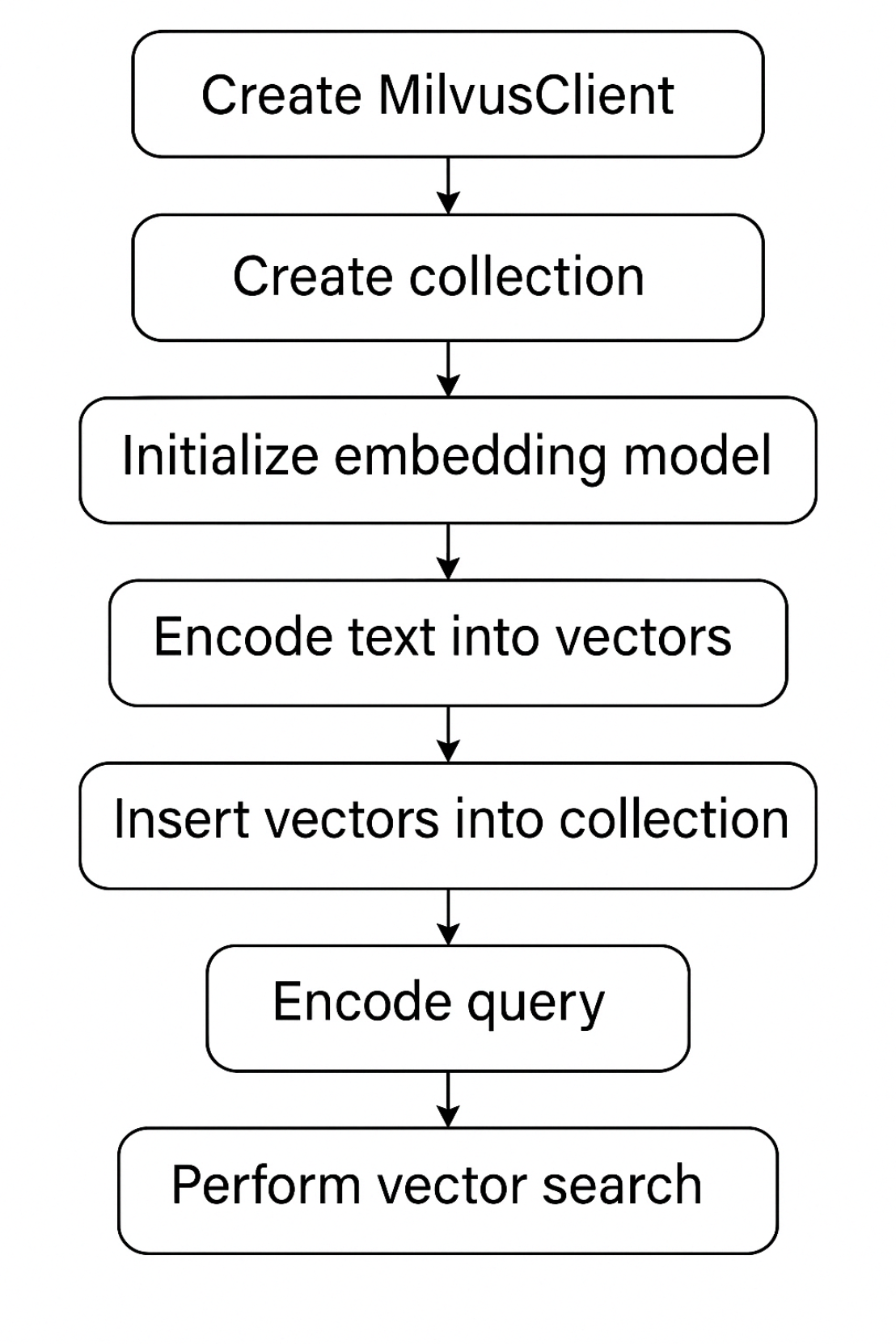
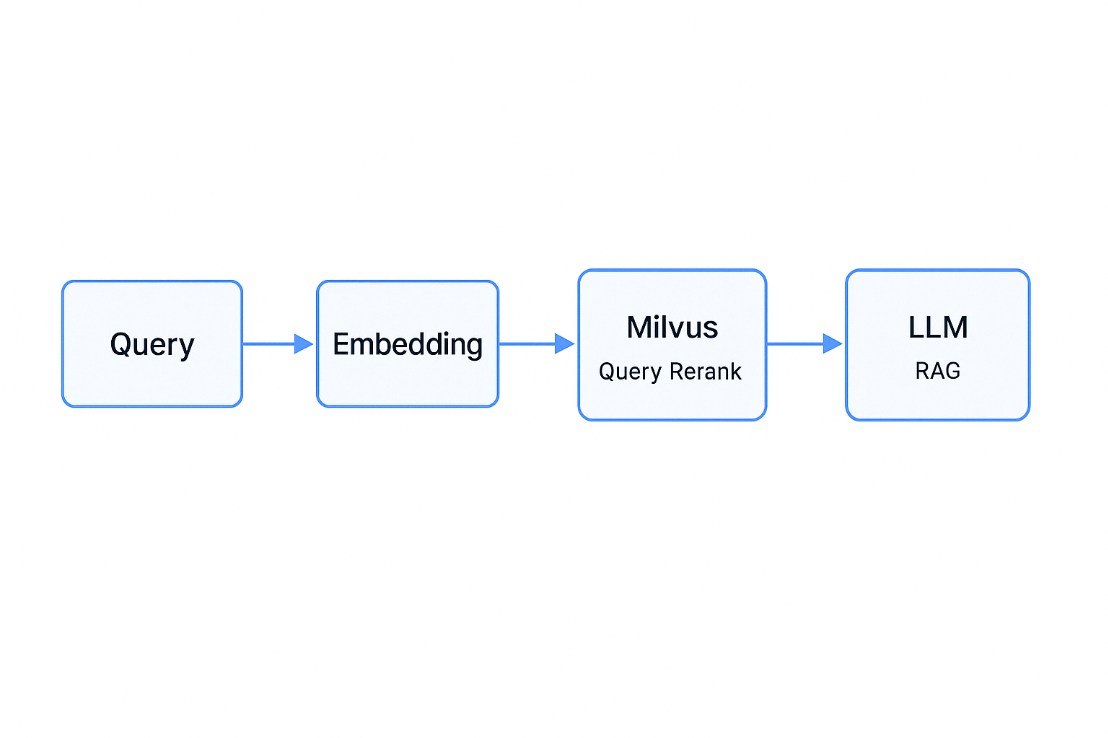
在 Milvus 中,数据库是组织和管理数据的逻辑单元。为了提高数据安全性并实现多租户,你可以创建多个数据库,为不同的应用程序或租户从逻辑上隔离数据。例如,创建一个数据库用于存储用户 A 的数据,另一个数据库用于存储用户 B 的数据。它支持Python、Go、Java、NodeJS等语言去操作数据库。
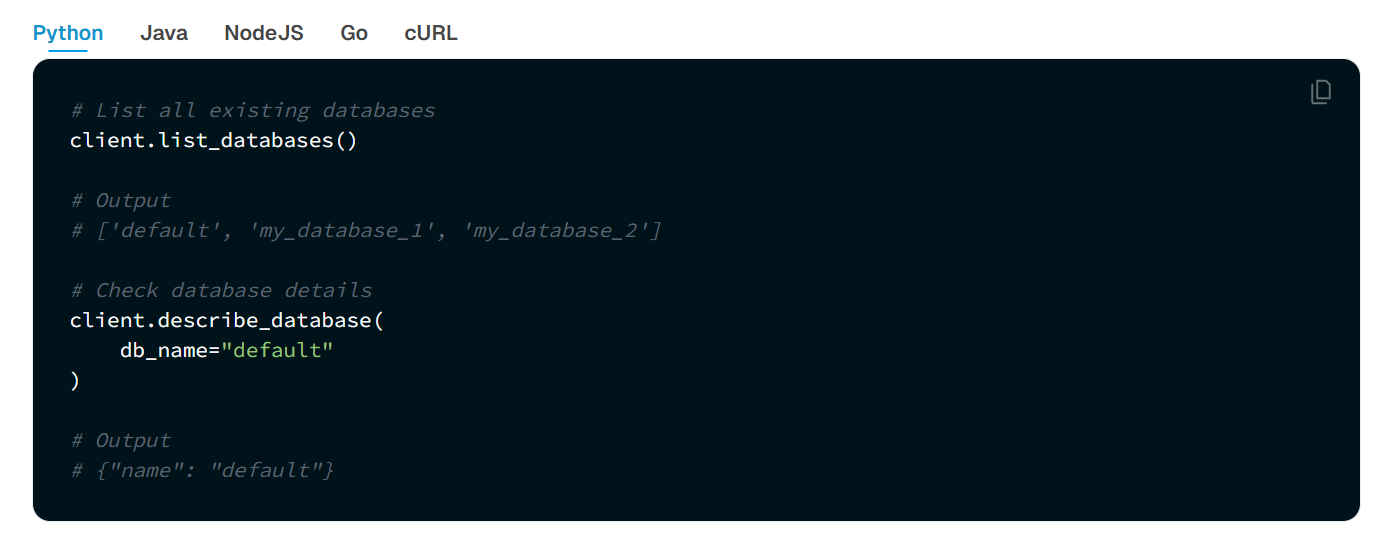
可以使用 Milvus RESTful API 或 SDK 列出所有现有数据库并查看其详细信息。同时,还可以管理数据库的属性,包括更改、删除等操作。
# 从 pymilvus.model.reranker 模块中引入 BGE 重排序模型函数
from pymilvus.model.reranker import BGERerankFunction
# ----------------------------------------------------------
# 初始化 Reranker(重排序器):
# 使用 BAAI(智源研究院)提供的 BGE-Reranker-v2-M3 模型。
# 该模型基于 Cross-Encoder 架构,通过对 query 和文档对进行语义交互建模,
# 输出相关性打分,用于对初始检索结果进行排序提升精度。
# ----------------------------------------------------------
bge_rf = BGERerankFunction(
model_name="BAAI/bge-reranker-v2-m3", # 模型名称,默认即为该模型
device="cpu" # 计算设备,可改为 'cuda:0' 使用 GPU 加速
)
# ----------------------------------------------------------
# 定义一个查询(query),用于检索历史相关信息。
# ----------------------------------------------------------
query = "What event in 1956 marked the official birth of artificial intelligence as a discipline?"
# ----------------------------------------------------------
# 定义候选文档列表(documents):
# 模拟从 Milvus 检索返回的初步候选文本片段(Top-K),
# 接下来将使用 Reranker 进一步对它们进行精排。
# 文档集合里面有四个元素,从0到3编号。
# ----------------------------------------------------------
documents = [
"In 1950, Alan Turing published his seminal paper, 'Computing Machinery and Intelligence,' proposing the Turing Test as a criterion of intelligence, a foundational concept in the philosophy and development of artificial intelligence.",
"The Dartmouth Conference in 1956 is considered the birthplace of artificial intelligence as a field; here, John McCarthy and others coined the term 'artificial intelligence' and laid out its basic goals.",
"In 1951, British mathematician and computer scientist Alan Turing also developed the first program designed to play chess, demonstrating an early example of AI in game strategy.",
"The invention of the Logic Theorist by Allen Newell, Herbert A. Simon, and Cliff Shaw in 1955 marked the creation of the first true AI program, which was capable of solving logic problems, akin to proving mathematical theorems."
]
# ----------------------------------------------------------
# 执行重排序操作:
# 将 query 与每个文档组合进行相关性评分,输出按分值降序排列的 Top-K 文档。
# top_k 参数指定只保留得分最高的前 K 条(这里设为 3)。
# 返回结果为一个包含 RerankResult 对象的列表,每个对象包含:
# - index:原文档在输入列表中的索引位置
# - score:query 与该文档的语义相关性打分(越高越相关)
# - text:文档原文内容
# ----------------------------------------------------------
results = bge_rf(
query=query,
documents=documents,
top_k=3, # 返回得分最高的前 3 条
)
# ----------------------------------------------------------
# 遍历输出精排结果:
# 展示每条候选文档的原始索引、得分(保留 6 位小数)、文本内容。
# 注意结果已按 score 排序,score 越高代表与 query 越匹配。
# ----------------------------------------------------------
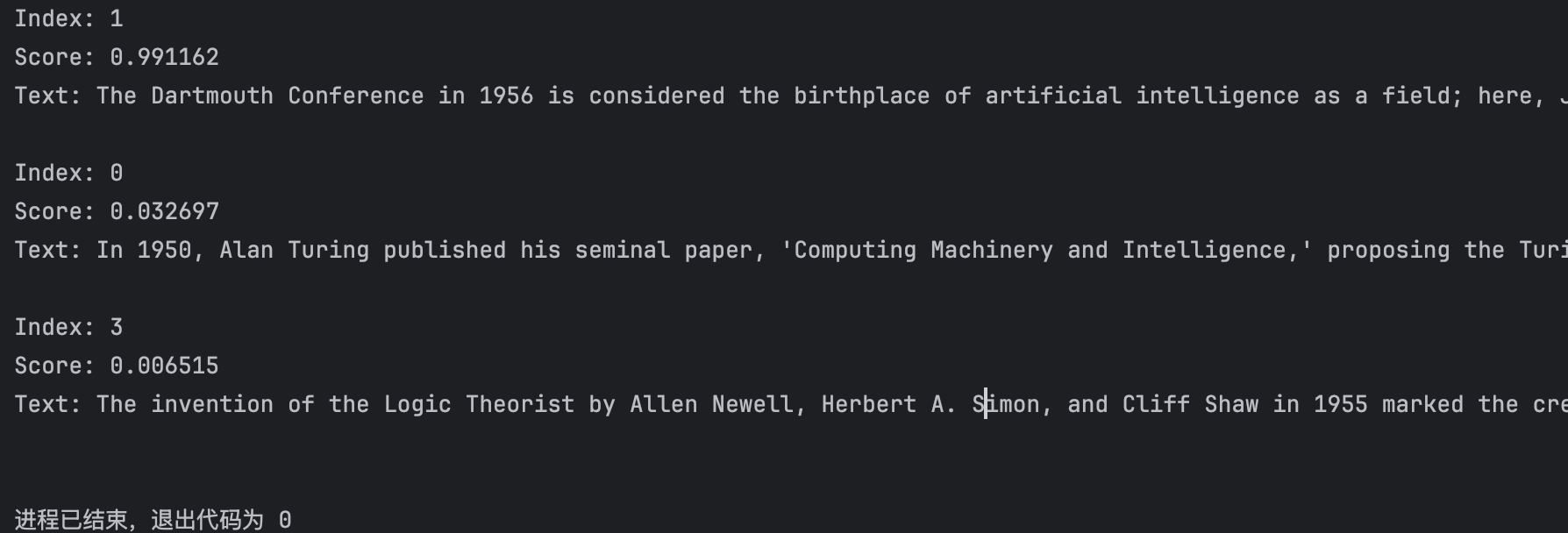
for result in results:
print(f"Index: {result.index}") # 文本在原始 documents 中的位置
print(f"Score: {result.score:.6f}") # 重排序得分
print(f"Text: {result.text}\n") # 文本内容
from sentence_transformers import CrossEncoder
model = CrossEncoder('cross-encoder/ms-marco-MiniLM-L6-v2')
scores = model.predict([
("How many people live in Berlin?", "Berlin had a population of 3,520,031 registered inhabitants in an area of 891.82 square kilometers."),
("How many people live in Berlin?", "Berlin is well known for its museums."),
])
print(scores)
# [ 8.607141 -4.320079]
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import torch
from sentence_transformers import CrossEncoder
# 方法一:
model = CrossEncoder('cross-encoder/ms-marco-MiniLM-L12-v2')
scores = model.predict([
("How many people live in Berlin?", "Berlin had a population of 3,520,031 registered inhabitants in an area of 891.82 square kilometers."),
("How many people live in Berlin?", "Berlin is well known for its museums."),
])
print(scores)
# 方法二:
model = AutoModelForSequenceClassification.from_pretrained('cross-encoder/ms-marco-MiniLM-L12-v2')
tokenizer = AutoTokenizer.from_pretrained('cross-encoder/ms-marco-MiniLM-L12-v2')
features = tokenizer(['How many people live in Berlin?', 'How many people live in Berlin?'], ['Berlin had a population of 3,520,031 registered inhabitants in an area of 891.82 square kilometers.', 'Berlin is well known for its museums.'], padding=True, truncation=True, return_tensors="pt")
model.eval()
with torch.no_grad():
scores = model(**features).logits
print(scores)
如果要进行重排序的话,可以参考下面的文档:
# 从 pymilvus.model.reranker 模块中导入交叉编码器重排序函数
from pymilvus.model.reranker import CrossEncoderRerankFunction
# ✅ 步骤 1:定义交叉编码器(Cross Encoder)重排序函数
# 该函数内部会自动下载 Hugging Face 上的模型并用于 rerank
ce_rf = CrossEncoderRerankFunction(
model_name="cross-encoder/ms-marco-MiniLM-L12-v2", # 使用指定的 cross-encoder 模型(支持语义匹配任务)
device="cpu" # 指定模型运行设备,如 'cpu' 或 'cuda:0'(GPU)
)
# ✅ 步骤 2:定义用户查询(Query)
query = "What event in 1956 marked the official birth of artificial intelligence as a discipline?"
# 中文翻译:1956年哪一事件标志着人工智能作为一门学科的正式诞生?
# ✅ 步骤 3:准备待重排序的候选文档(Documents)
# 每个字符串都是一个候选答案,Cross Encoder 会将它们与 Query 组合成一个个句对进行评分
documents = [
"In 1950, Alan Turing published his seminal paper, 'Computing Machinery and Intelligence,' proposing the Turing Test as a criterion of intelligence, a foundational concept in the philosophy and development of artificial intelligence.",
# 图灵1950年的论文,提出图灵测试,为AI发展奠定哲学基础
"The Dartmouth Conference in 1956 is considered the birthplace of artificial intelligence as a field; here, John McCarthy and others coined the term 'artificial intelligence' and laid out its basic goals.",
# 1956年达特茅斯会议,被广泛认为是AI的诞生标志
"In 1951, British mathematician and computer scientist Alan Turing also developed the first program designed to play chess, demonstrating an early example of AI in game strategy.",
# 图灵在1951年开发了下棋程序,展示早期AI在博弈中的应用
"The invention of the Logic Theorist by Allen Newell, Herbert A. Simon, and Cliff Shaw in 1955 marked the creation of the first true AI program, which was capable of solving logic problems, akin to proving mathematical theorems."
# 1955年“逻辑理论家”程序是首个能解逻辑问题的AI程序
]
# ✅ 步骤 4:调用重排序函数进行语义匹配排序(Reranking)
# Cross Encoder 会对 (query, document) 成对输入进行语义评分,返回得分最高的 top_k 条
results = ce_rf(
query=query,
documents=documents,
top_k=3, # 返回得分最高的前 3 个文档
)
# ✅ 步骤 5:遍历结果,输出每条结果的索引、分数、文本内容
# Cross Encoder 输出的是基于语义匹配的相关性打分,越高越相关
for result in results:
print(f"Index: {result.index}") # 文档在原始列表中的索引
print(f"Score: {result.score:.6f}") # Cross Encoder 计算出的相关性得分
print(f"Text: {result.text}\n") # 对应的文档内容
大模型(Large Language Models,LLMs)的发展经历了从小规模模型到如今大规模、深度学习技术不断突破的过程。最早的语言模型主要依赖规则和手工特征,虽然能够进行一定的语言理解和生成,但缺乏足够的灵活性和准确性。随着深度学习的兴起,尤其是深度神经网络的应用,大规模语言模型开始崭露头角。
从最初的GPT(Generative Pre-trained Transformer)到BERT(Bidirectional Encoder Representations from Transformers)再到如今的GPT-4、DeepSeek-R1等,语言模型的规模和能力迅速提升。大模型通常包含数十亿到数百亿个参数,通过海量数据进行预训练,能够捕捉到语言中的复杂关系和语境信息。大模型的预训练使其具备了强大的迁移学习能力,能够在多个任务上取得优秀的性能,无论是文本生成、问答、翻译还是推理任务。大模型的发展不仅在技术层面突破了许多原有的限制,还在应用上带来了巨大的变革。比如,基于大模型的自然语言处理技术已经广泛应用于智能助手、自动翻译、内容生成等领域,极大地提高了人机交互的效率和质量。从自然语言处理的发展历程来看,LLM已经是近期最热门的研究方向之一。
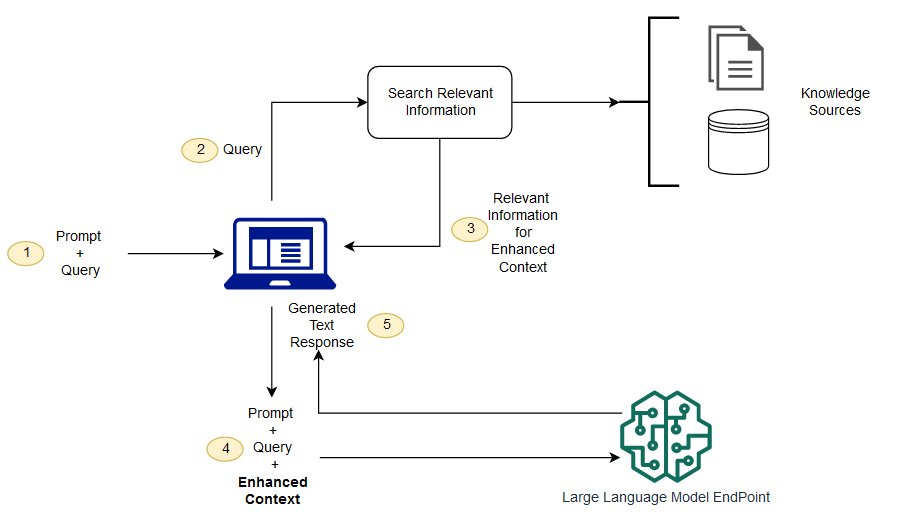
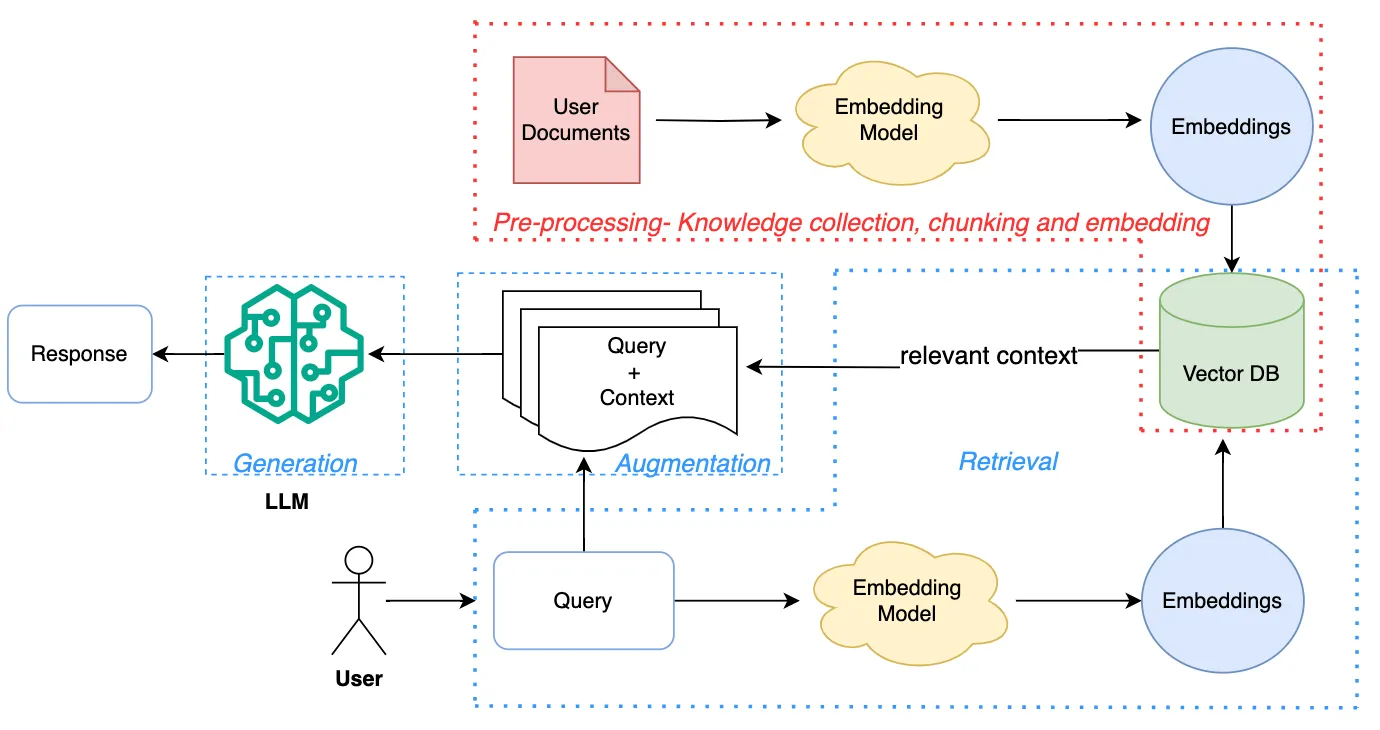
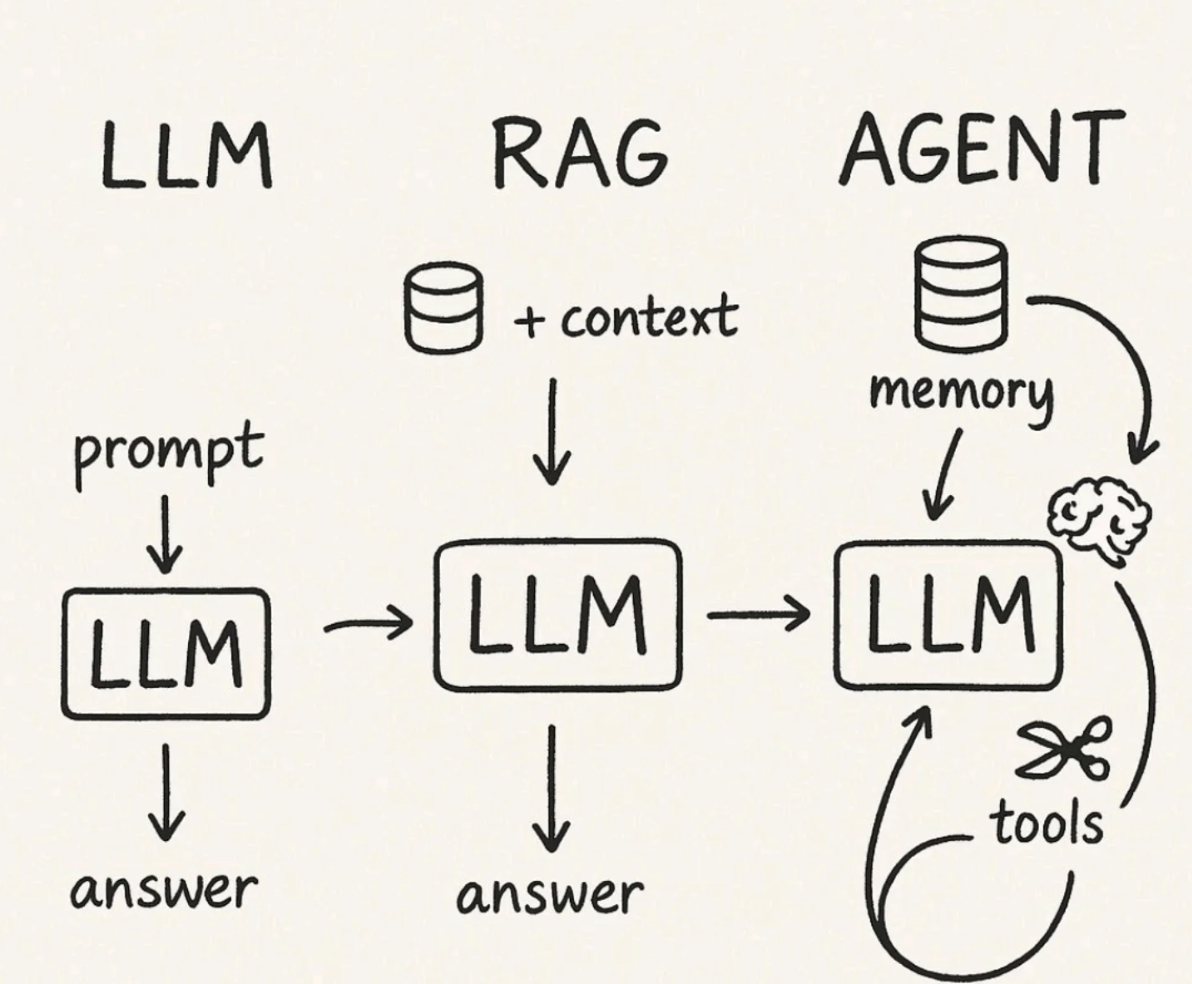
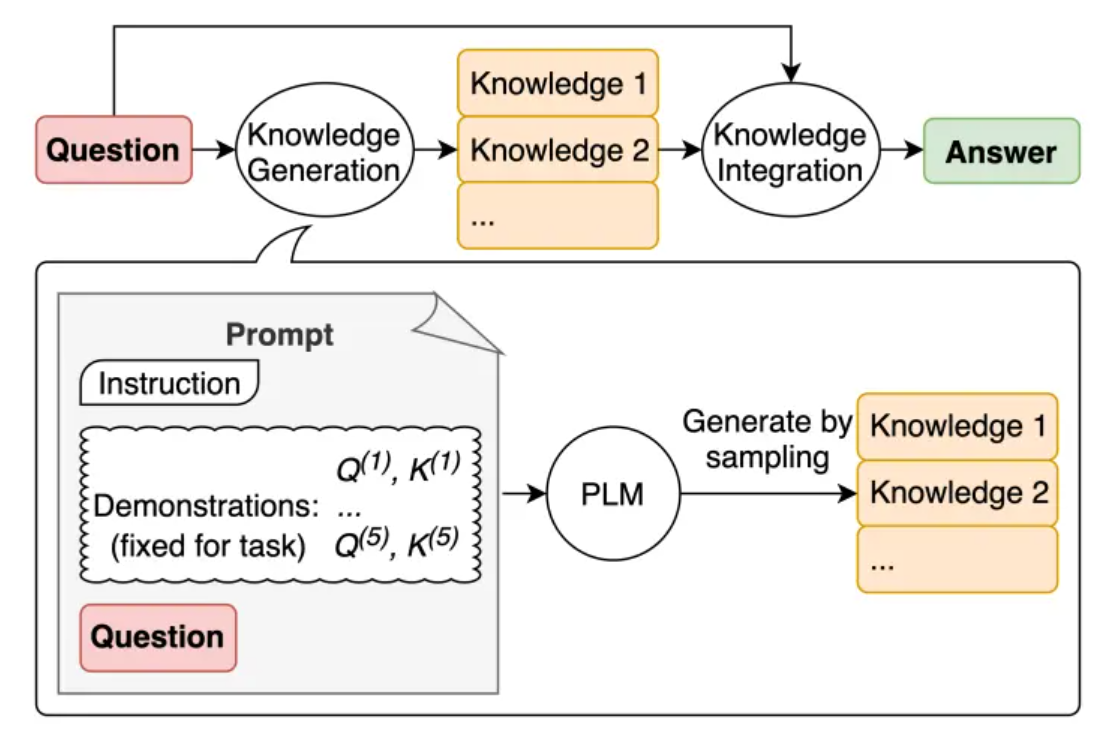
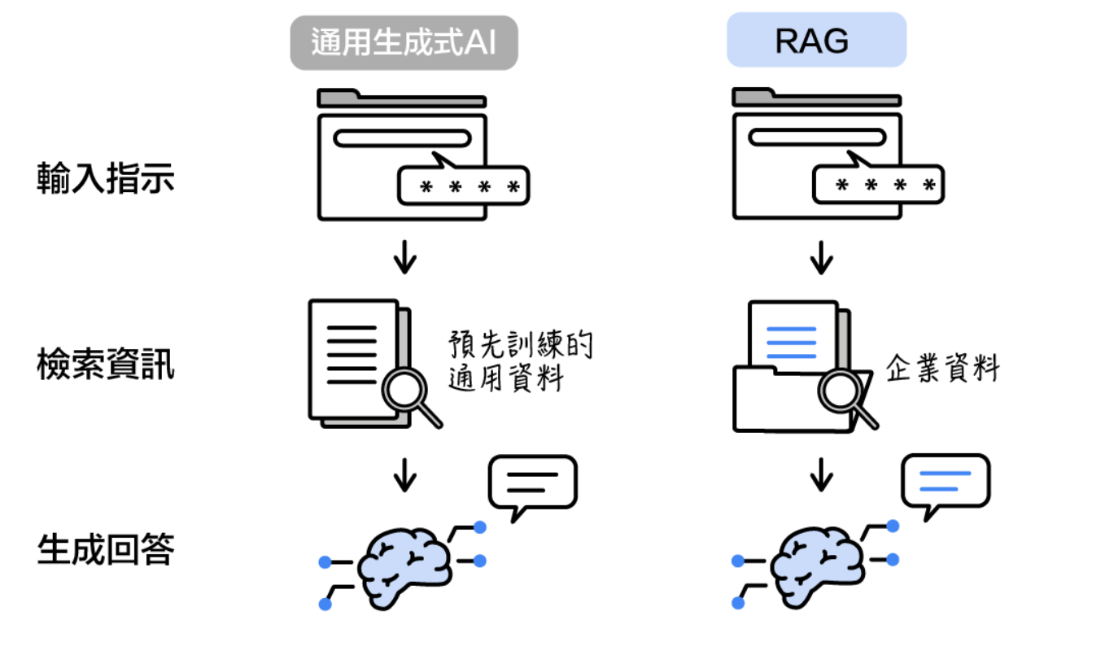
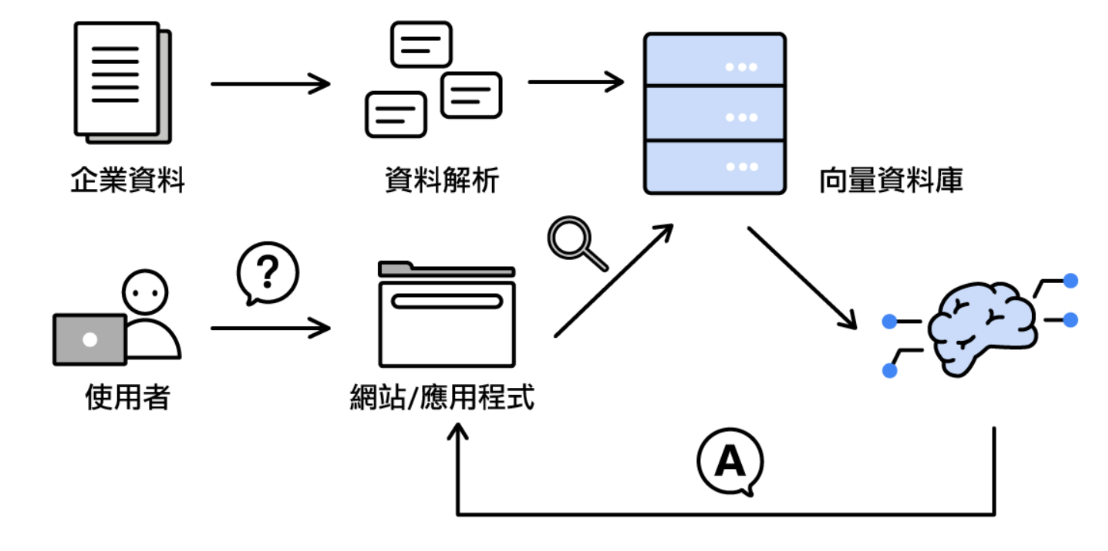
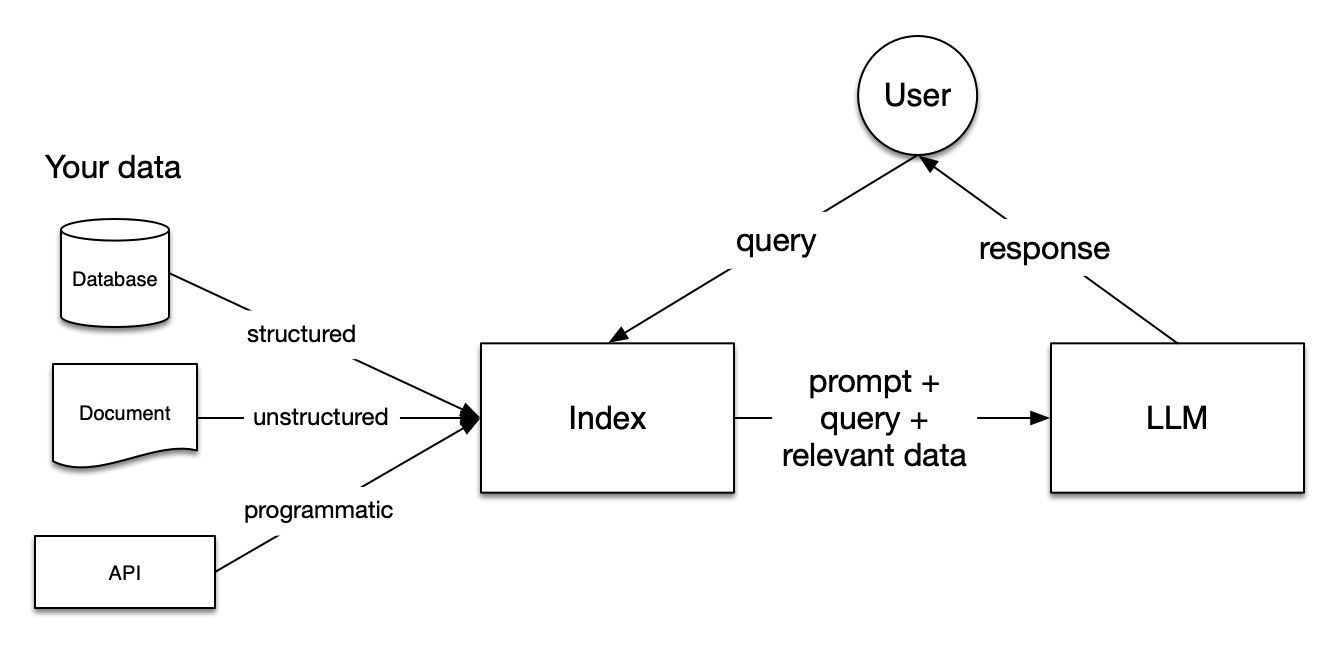
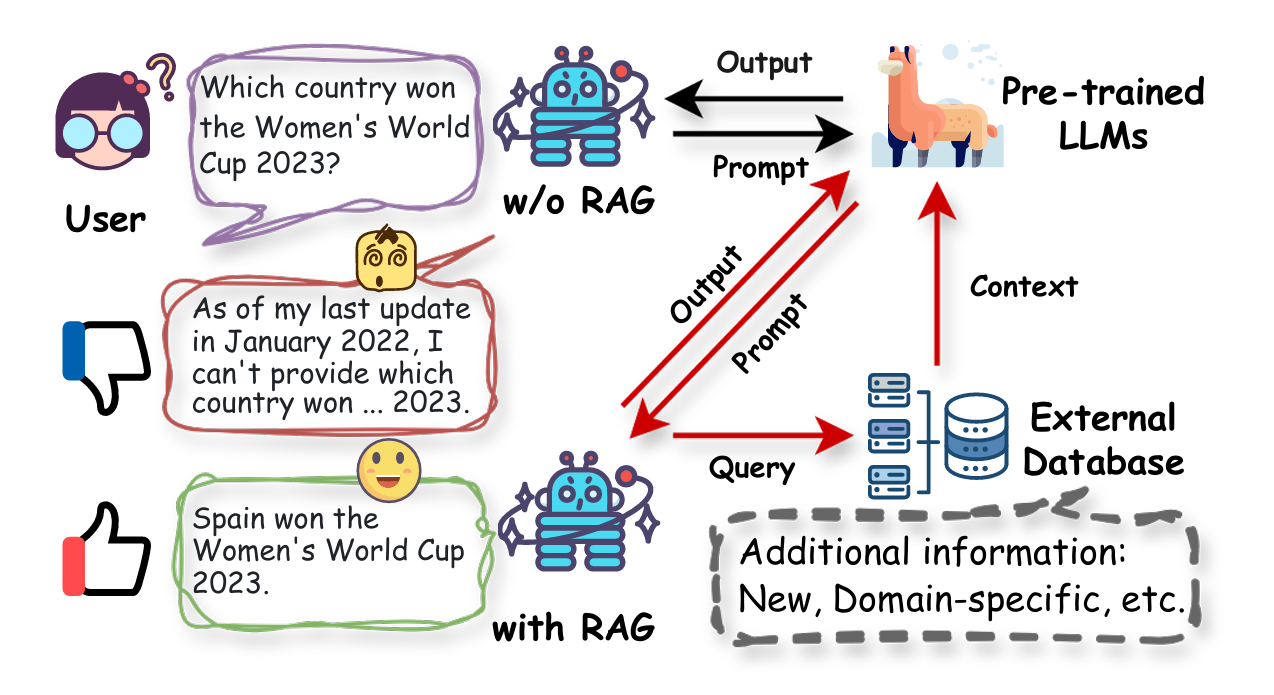
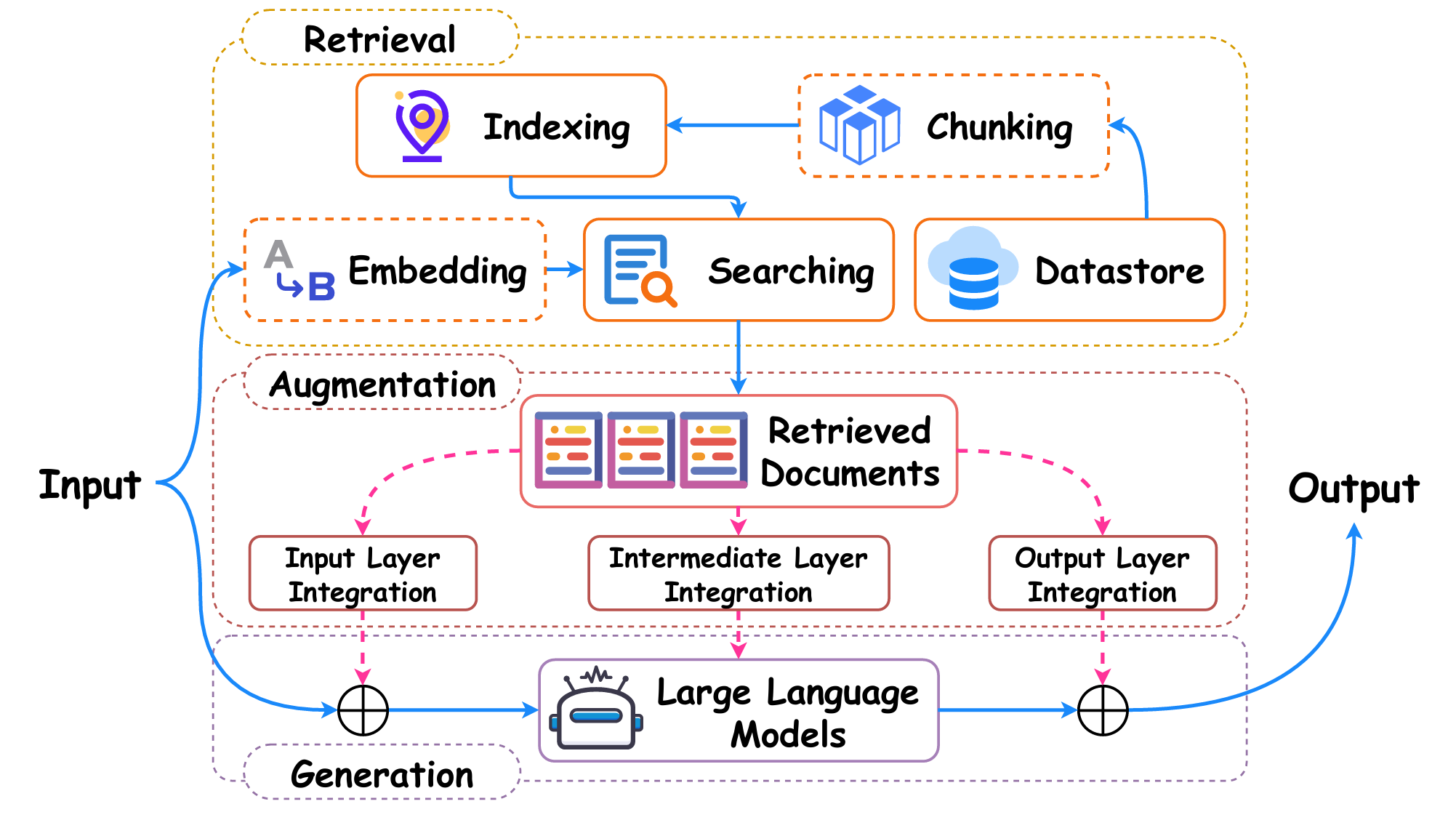
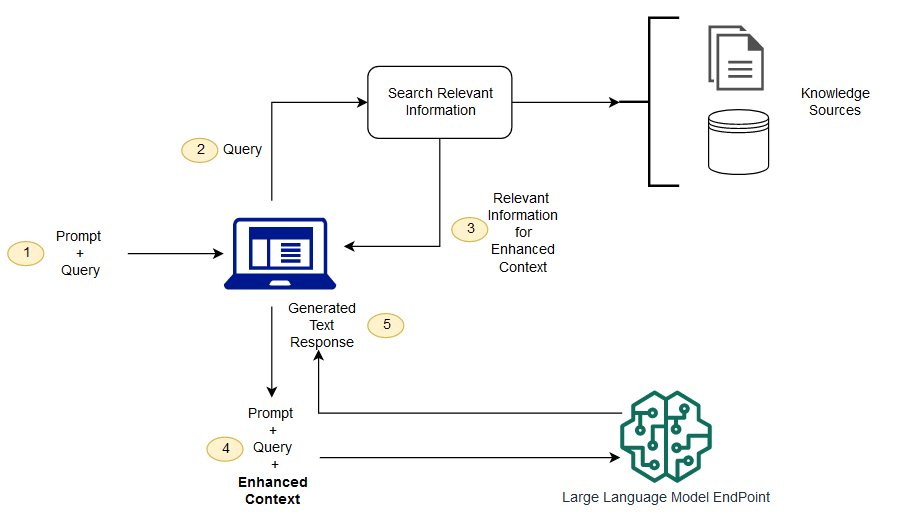
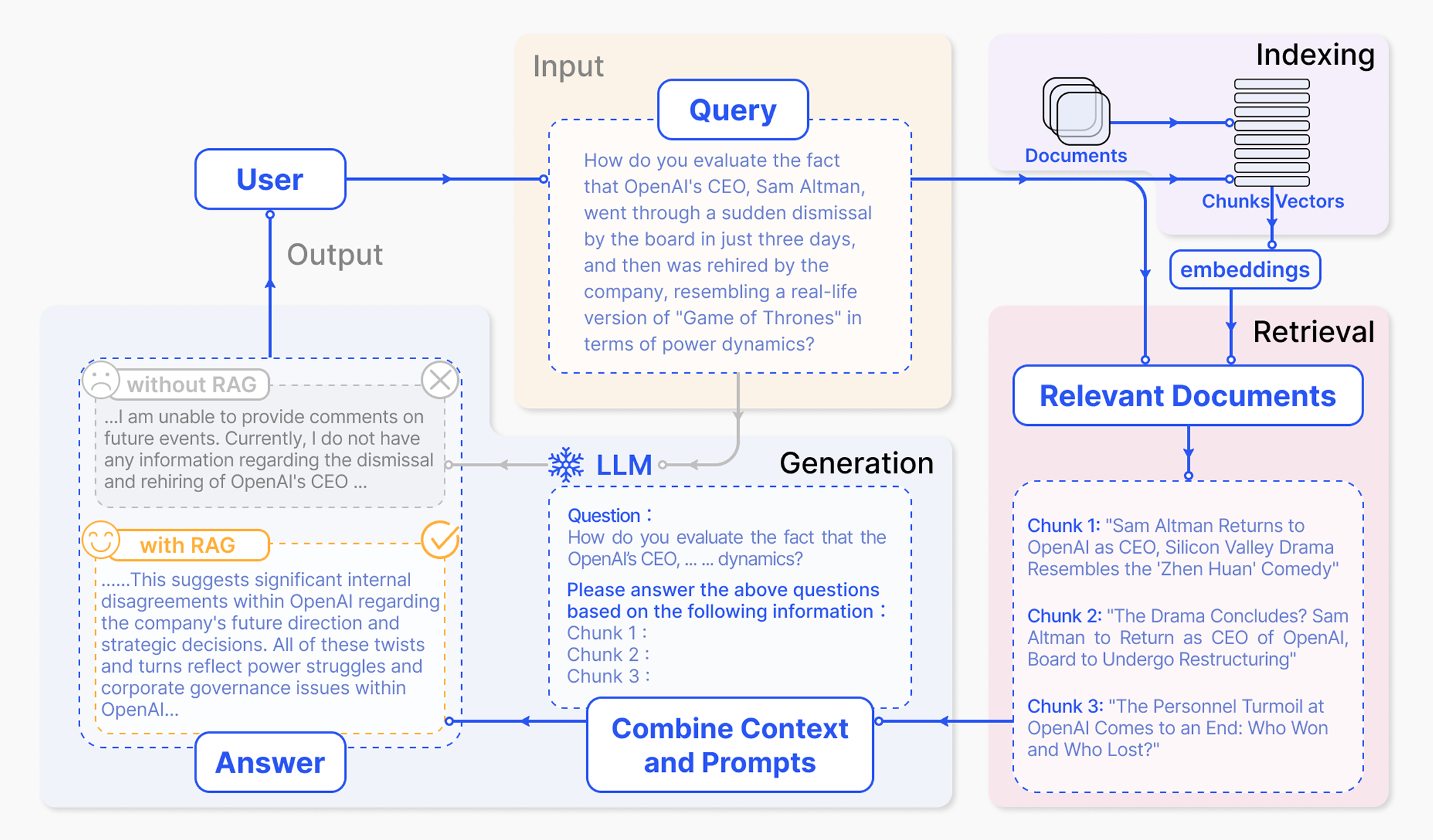
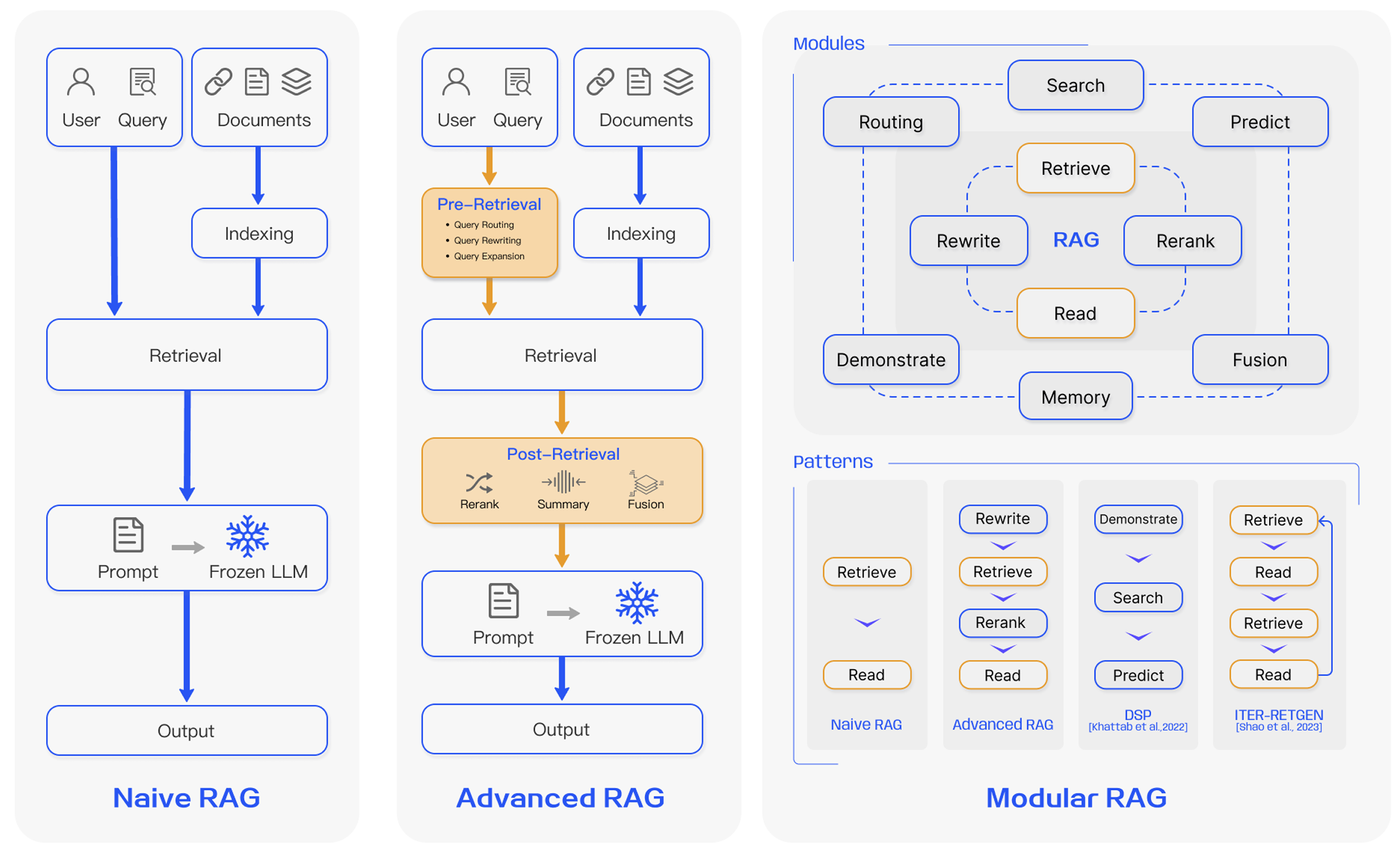
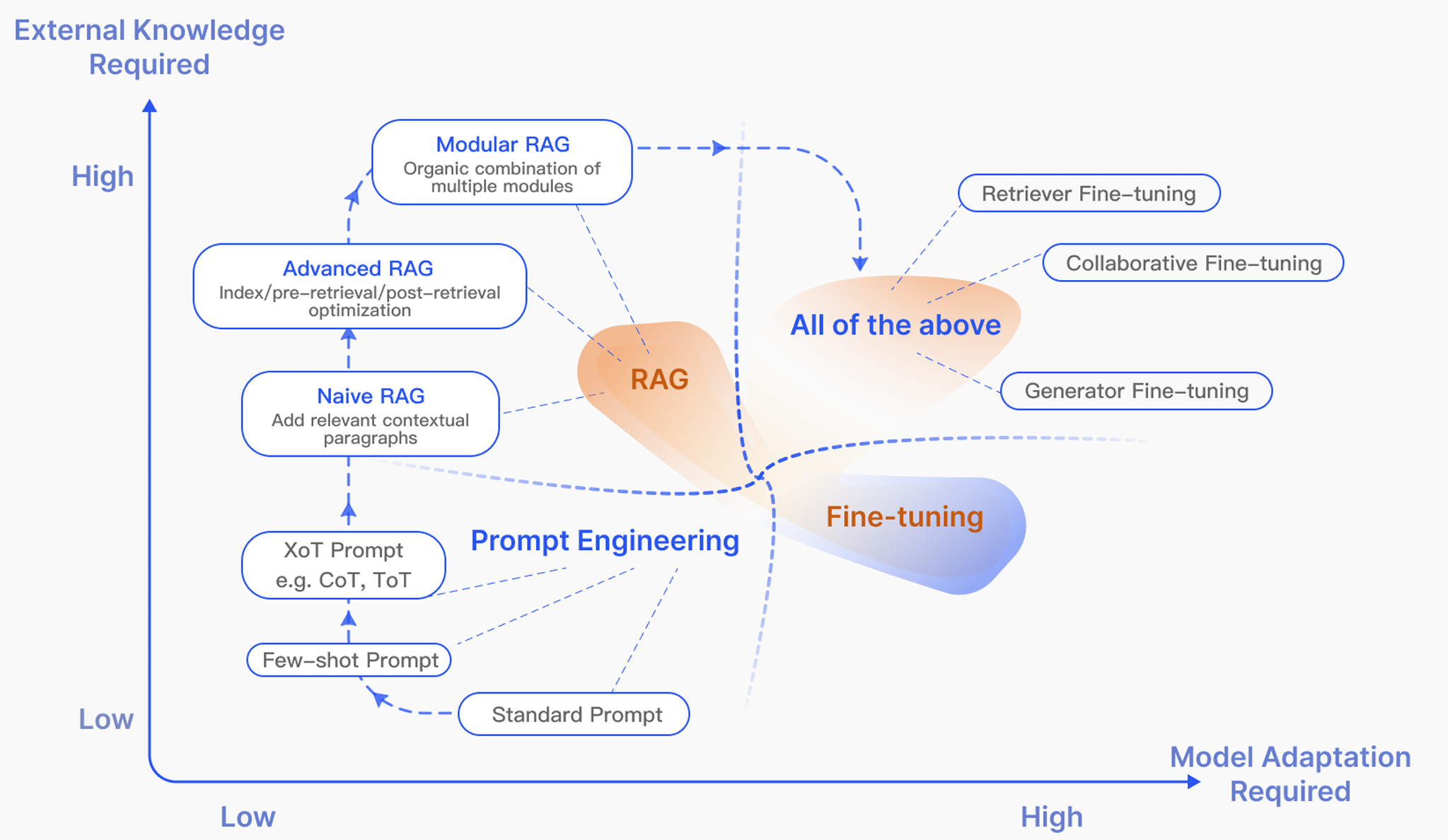
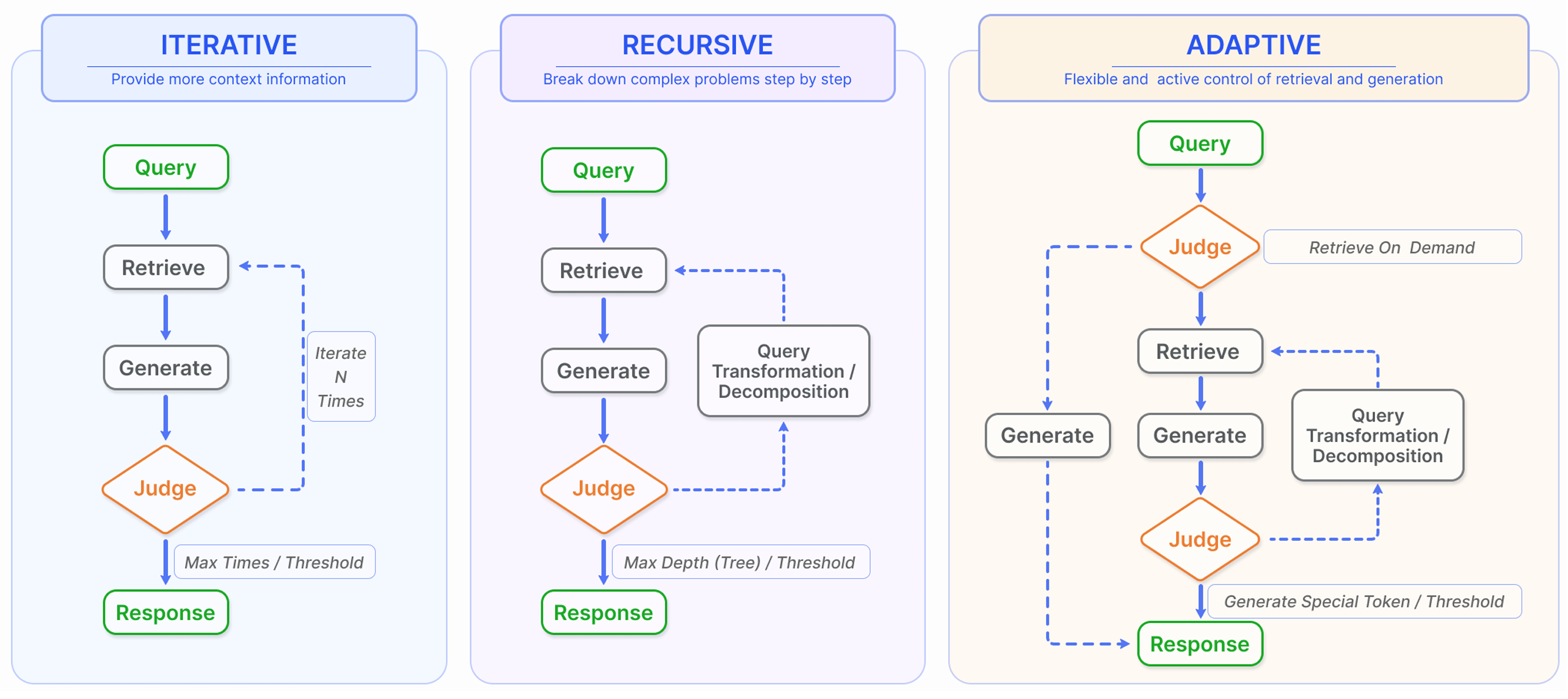
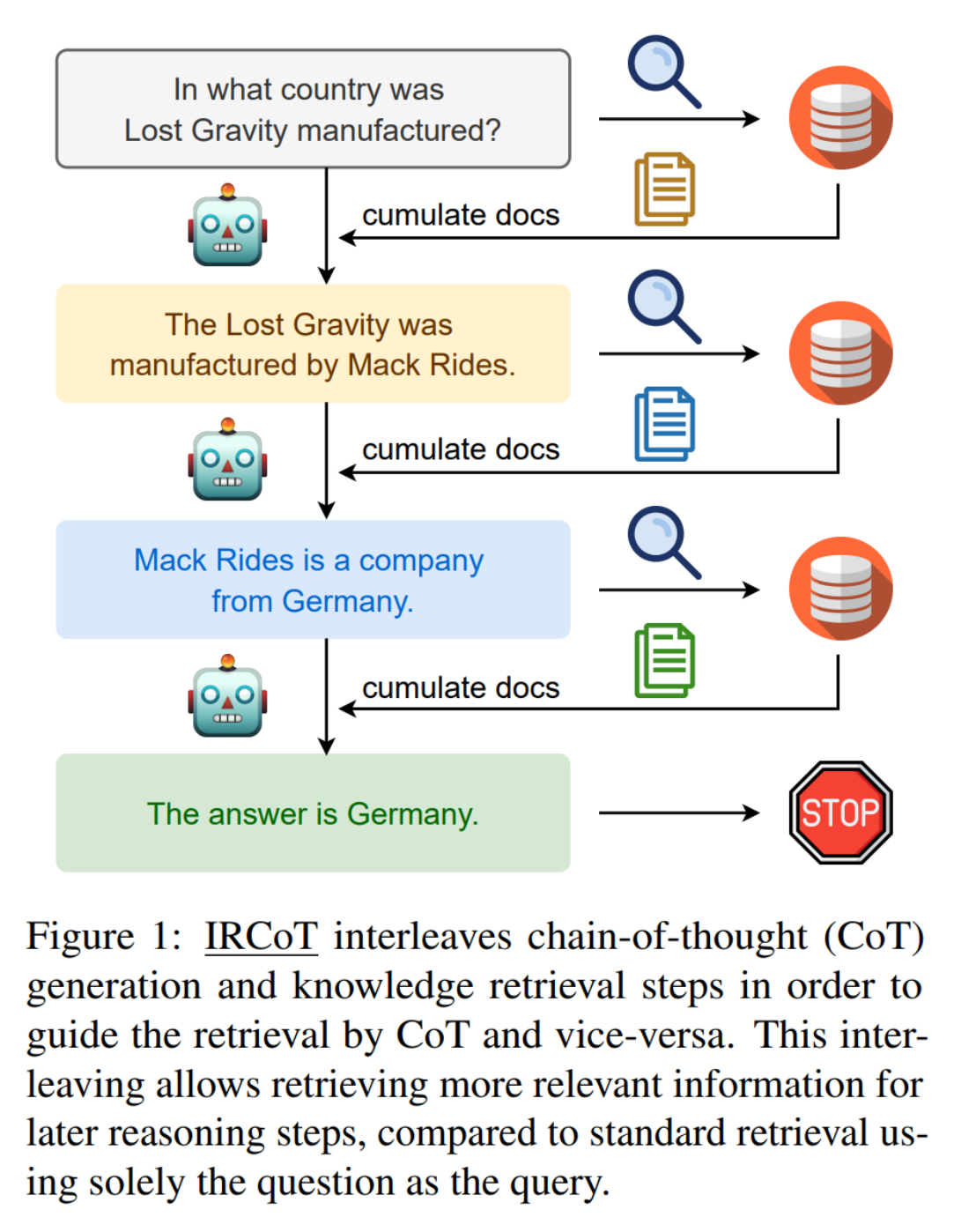
LLM 原始训练数据集之外的新数据称为外部数据。它可以来自多个数据来源,例如 API、数据库或文档存储库。数据可能以各种格式存在,例如文件、数据库记录或长篇文本。另一种称为嵌入语言模型的 AI 技术将数据转换为数字表示形式并将其存储在向量数据库中。这个过程会创建一个生成式人工智能模型可以理解的知识库。
Gao Y, Xiong Y, Gao X, et al. Retrieval-augmented generation for large language models: A survey[J]. arXiv preprint arXiv:2312.10997, 2023, 2.
Gao Y, Xiong Y, Zhong Y, et al. Synergizing RAG and Reasoning: A Systematic Review[J]. arXiv preprint arXiv:2504.15909, 2025.
Li X, Jia P, Xu D, et al. A Survey of Personalization: From RAG to Agent[J]. arXiv preprint arXiv:2504.10147, 2025.
Arslan M, Ghanem H, Munawar S, et al. A Survey on RAG with LLMs[J]. Procedia Computer Science, 2024, 246: 3781-3790.
Fan, Wenqi, et al. “A survey on rag meeting llms: Towards retrieval-augmented large language models.” Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 2024.
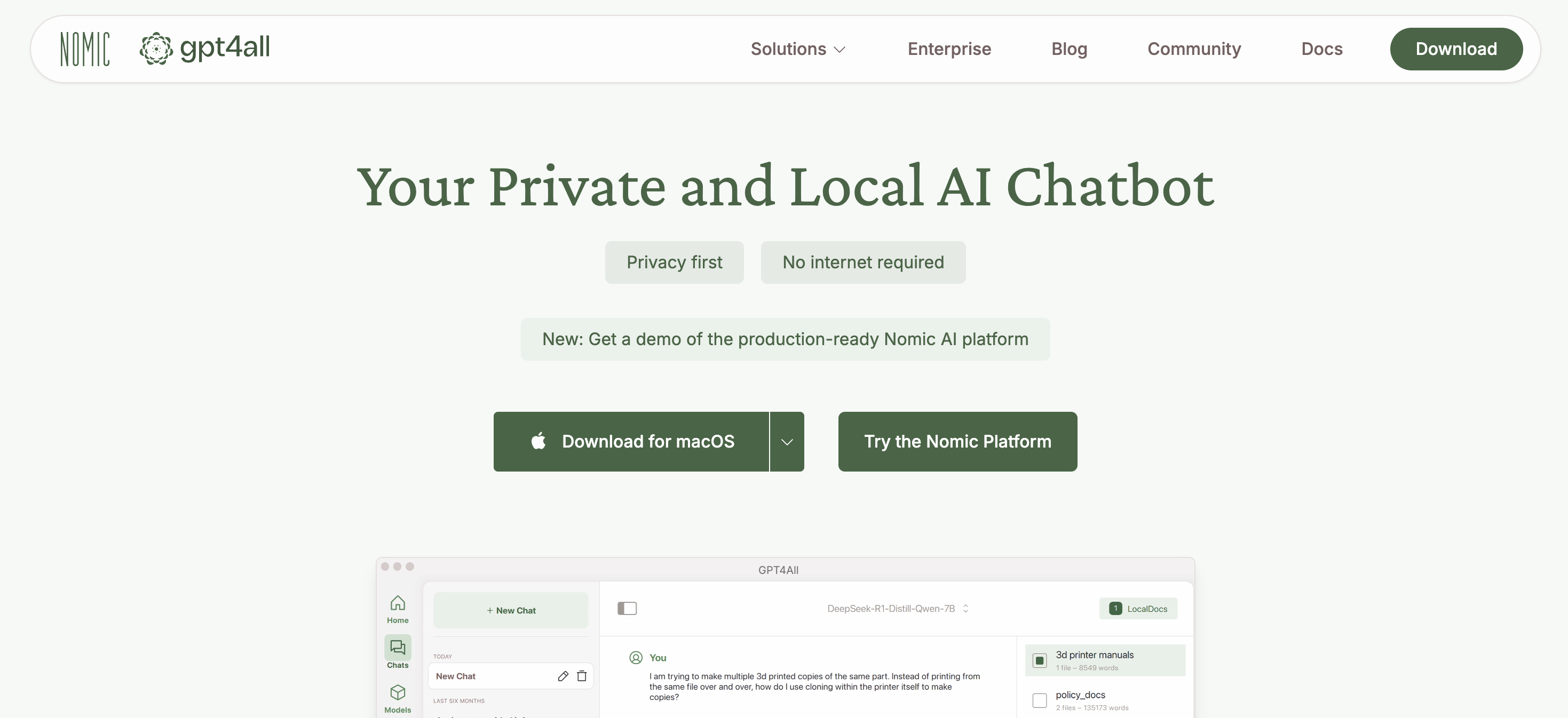
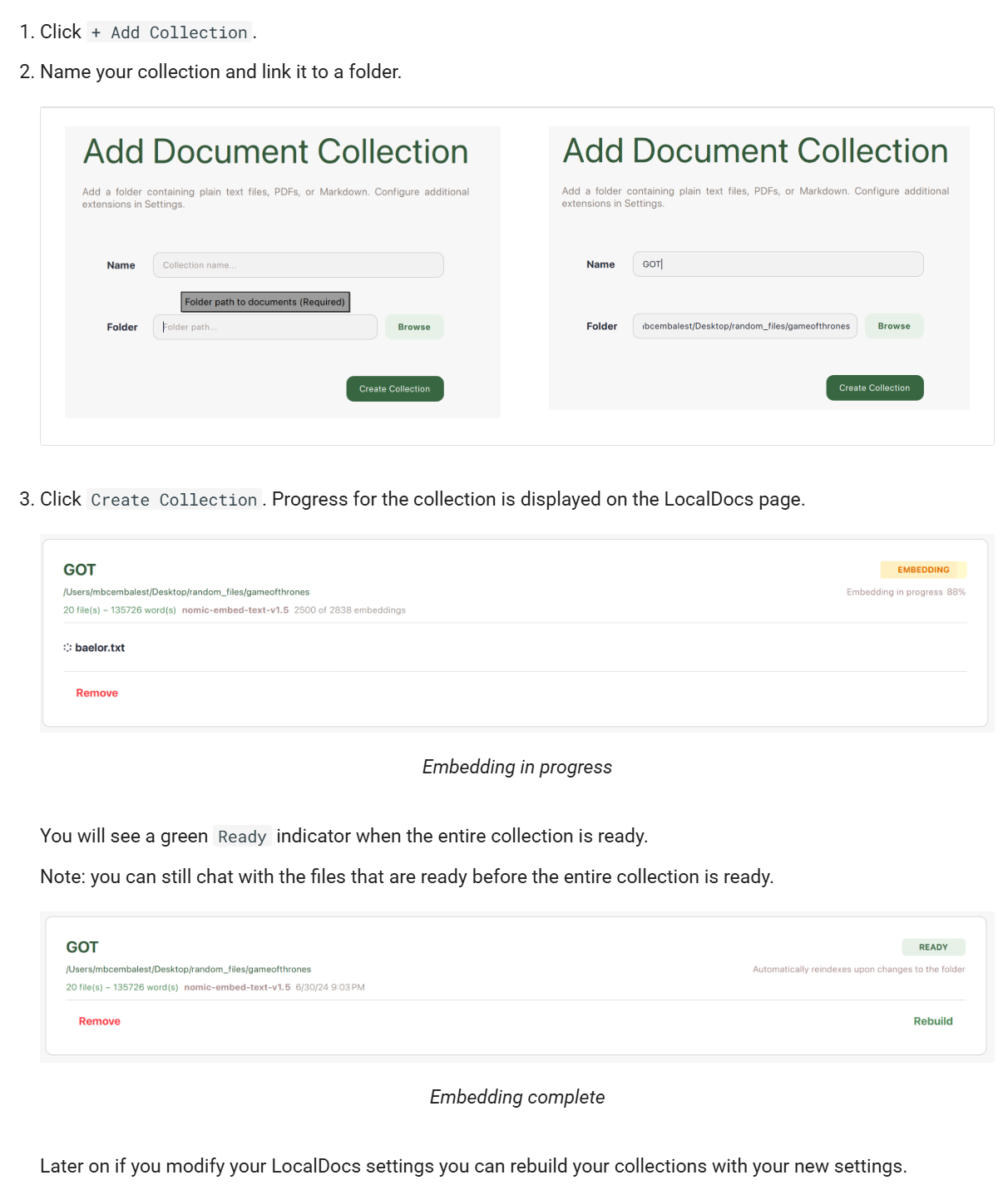
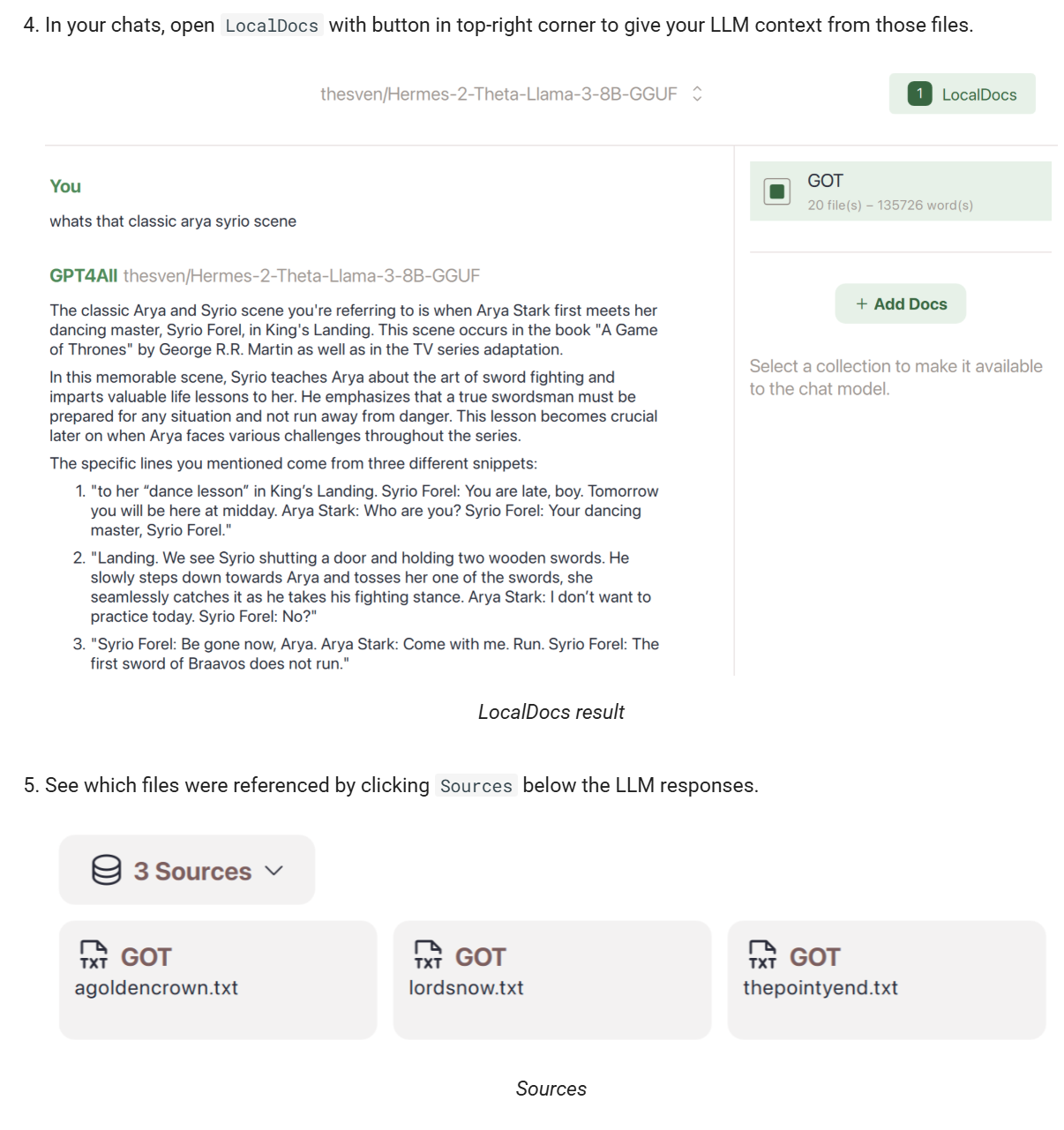
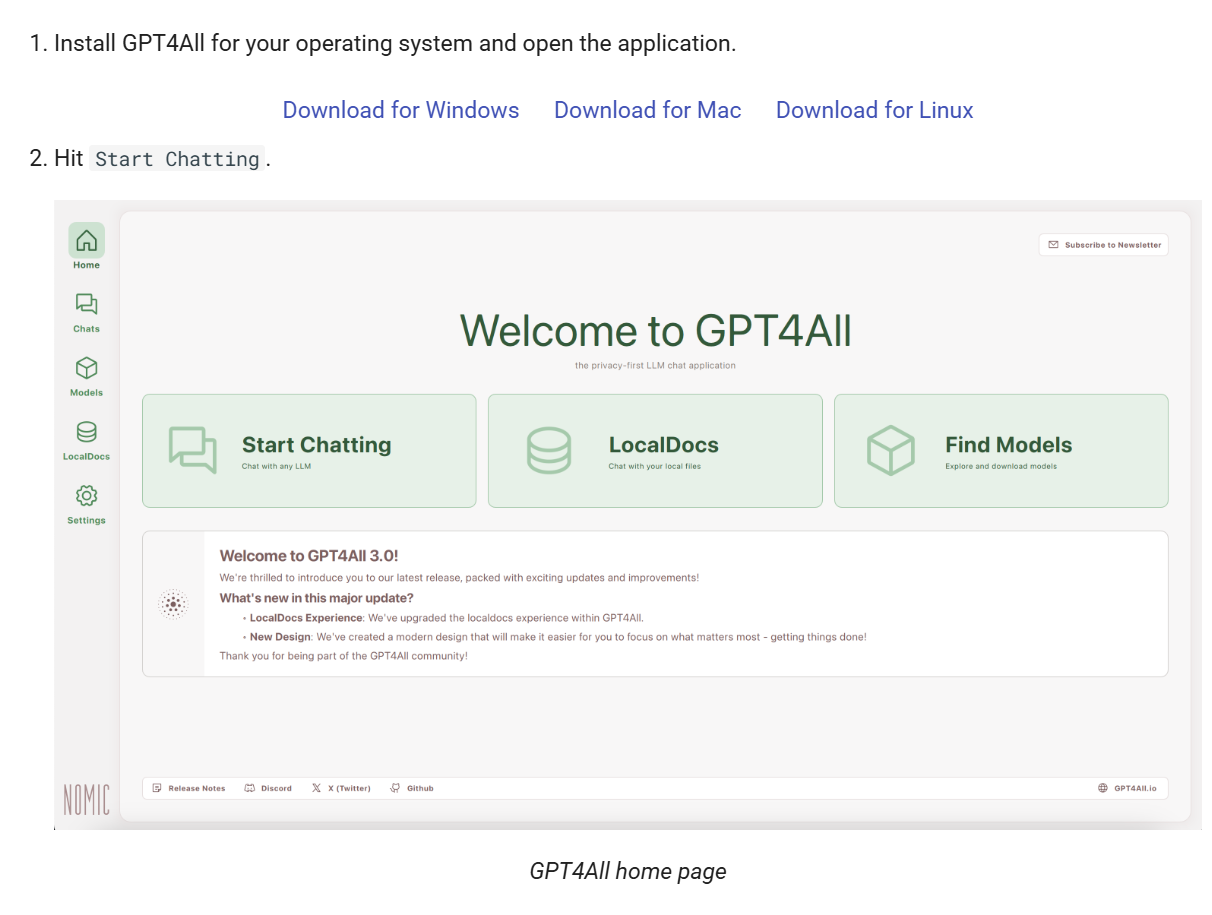
GPT4All 提供 LocalDocs 功能,允许用户将本地文档(如 PDF、TXT、Markdown 等)导入系统,与 AI 进行交互。 这对于处理敏感或私密信息非常有用。
3. 快速上手指南
3.1 下载并安装软件
访问下载适用于您操作系统(Windows、Mac、Linux)的安装包。
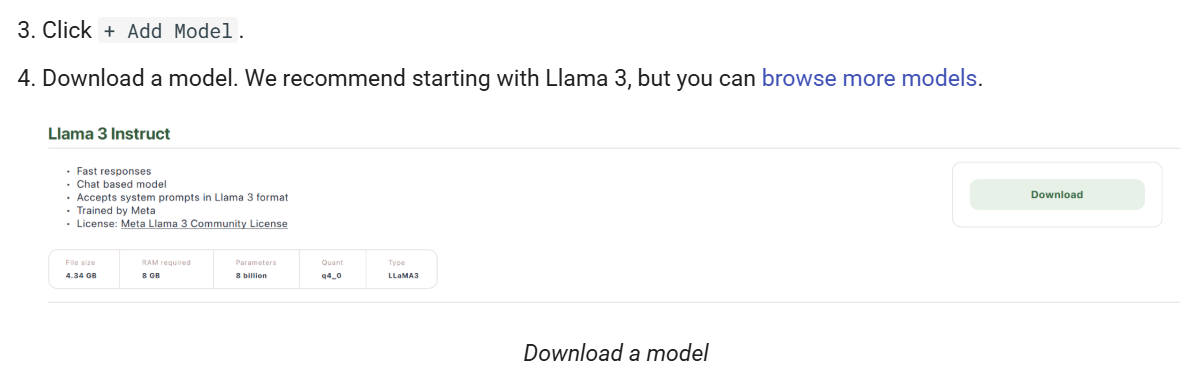
3.2 添加模型
启动应用程序后,点击“+ Add Model”按钮,选择并下载您需要的模型。
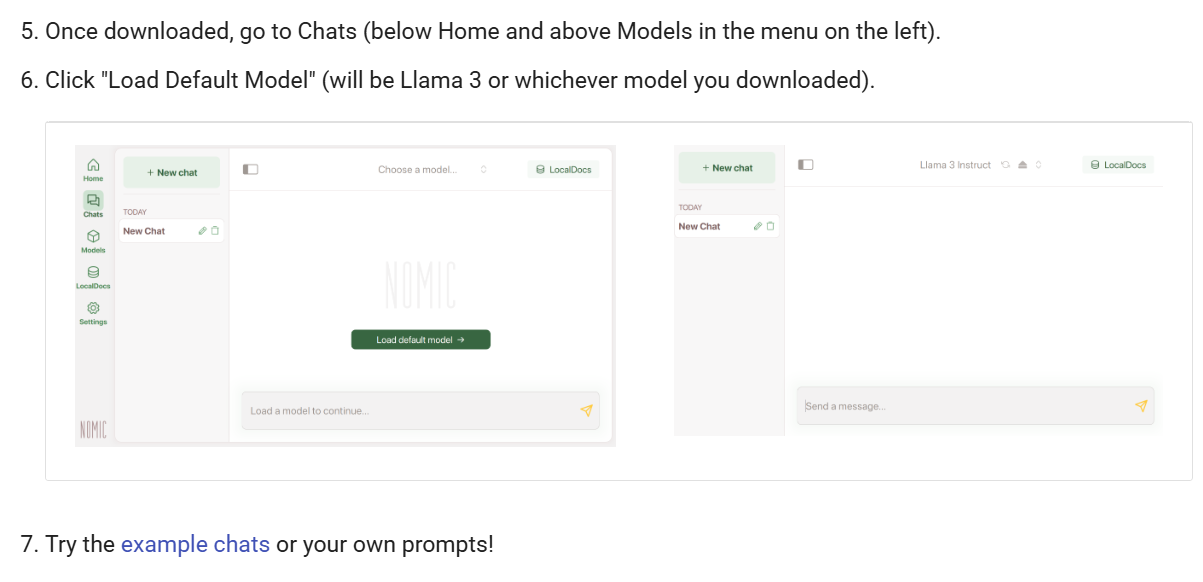
3.3 开始聊天
下载模型后,进入“Chats”界面,选择已加载的模型,开始与 AI 进行对话。并且还提供上传本地文件资料的功能,实现知识库的搜索。
3.4 使用Python的SDK
3.4.1 大语言模型
GPT4All 提供了 Python SDK,方便开发者将其集成到自己的项目中。 此外,项目采用 MIT 开源许可证,允许用户进行自定义和二次开发。
安装方法:
pip install gpt4all
使用方法:
可以按照官方提供的模板进行使用,如果模型没有提前下载的话,在第一次使用的时候,代码会自动下载模型。
from gpt4all import GPT4All
model = GPT4All("Meta-Llama-3-8B-Instruct.Q4_0.gguf") # downloads / loads a 4.66GB LLM
with model.chat_session():
print(model.generate("How can I run LLMs efficiently on my laptop?", max_tokens=1024))
如果想要进行流式输出或者一次性输出,可以使用streaming这个参数进行控制,参考代码:
from gpt4all import GPT4All
def output_with_stream_control(prompt: str, model_name: str = "Meta-Llama-3-8B-Instruct.Q4_0.gguf", max_tokens: int = 1024, streaming: bool = False):
model = GPT4All(model_name) # 加载指定模型
# 创建一个对话会话
with model.chat_session() as session:
response_buffer = ""
if streaming:
# 启用流式输出
for chunk in model.generate(prompt, max_tokens=max_tokens, streaming=streaming):
response_buffer += chunk
print(chunk, end='', flush=True) # 实时输出生成的文本
print("\n\n生成的完整答案:", response_buffer)
else:
# 批量输出(等待完整生成后返回)
response_buffer = model.generate(prompt, max_tokens=max_tokens, streaming=streaming)
print("\n生成的完整答案:", response_buffer)
return response_buffer
if __name__ == "__main__":
prompt = "用中文回答,什么是化学?"
result = output_with_stream_control(prompt, streaming=False)
print('result:', result)
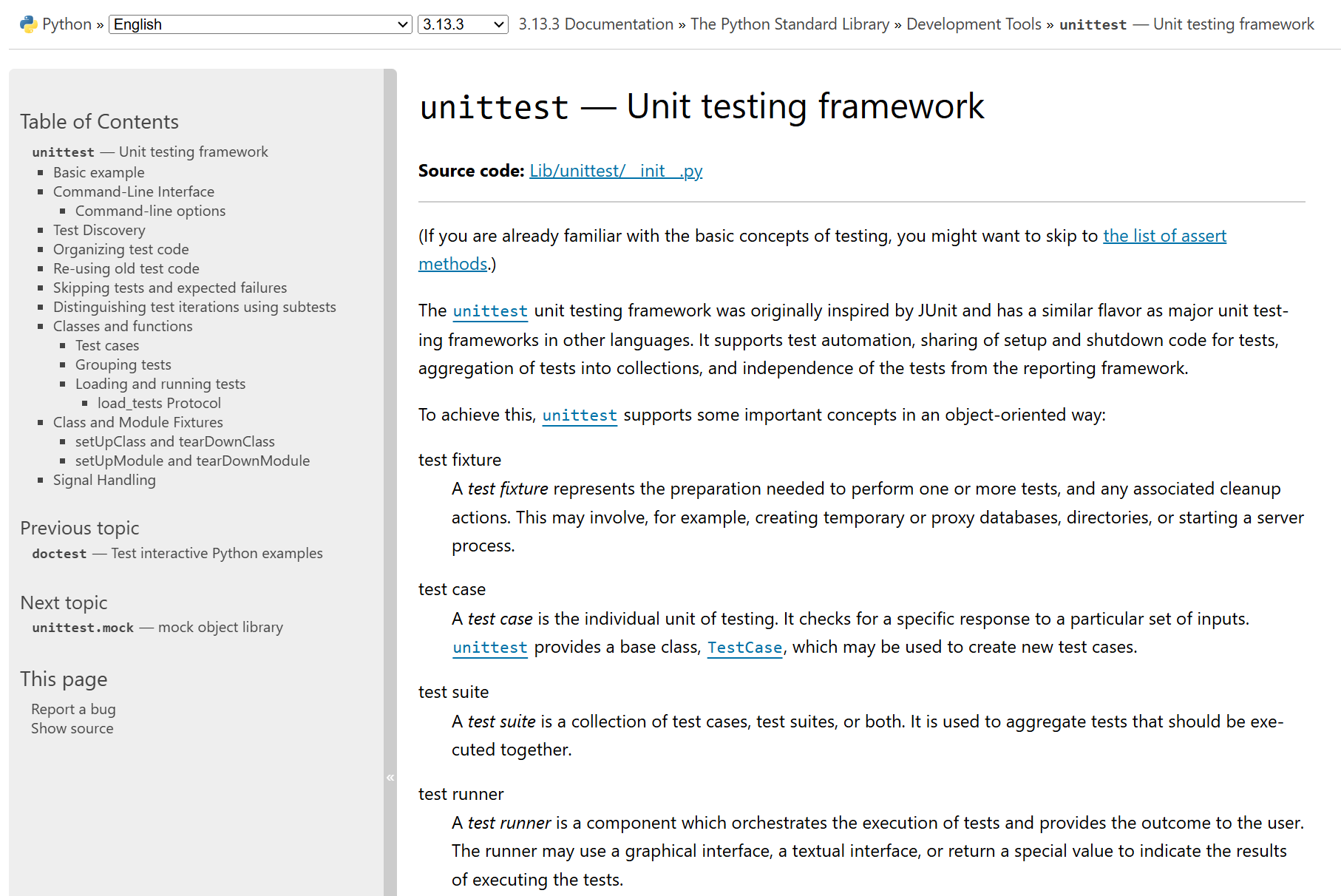
class Calculator:
"""This class performs basic arithmetic operations."""
pass
函数和方法:为每个函数和方法提供文档字符串,描述其作用、参数和返回值。
def add(a, b):
"""
Add two numbers and return the result.
Parameters:
a (int or float): The first number.
b (int or float): The second number.
Returns:
int or float: The sum of a and b.
"""
return a + b
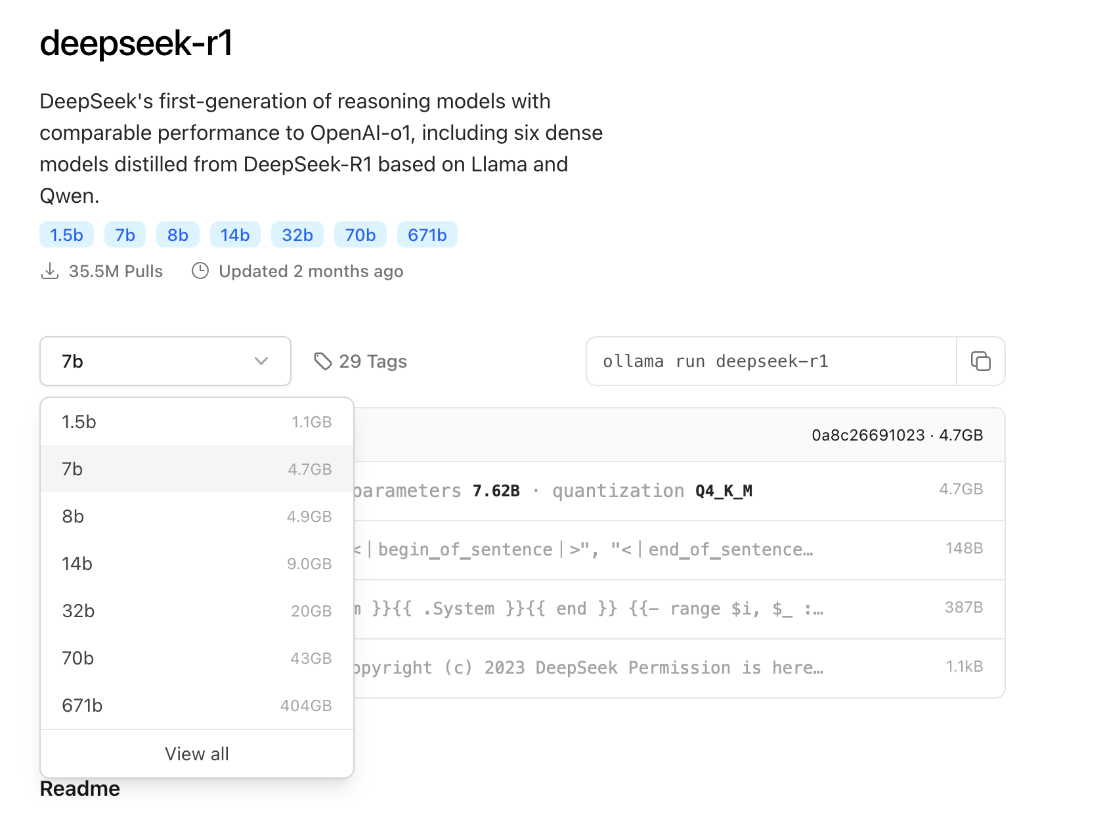
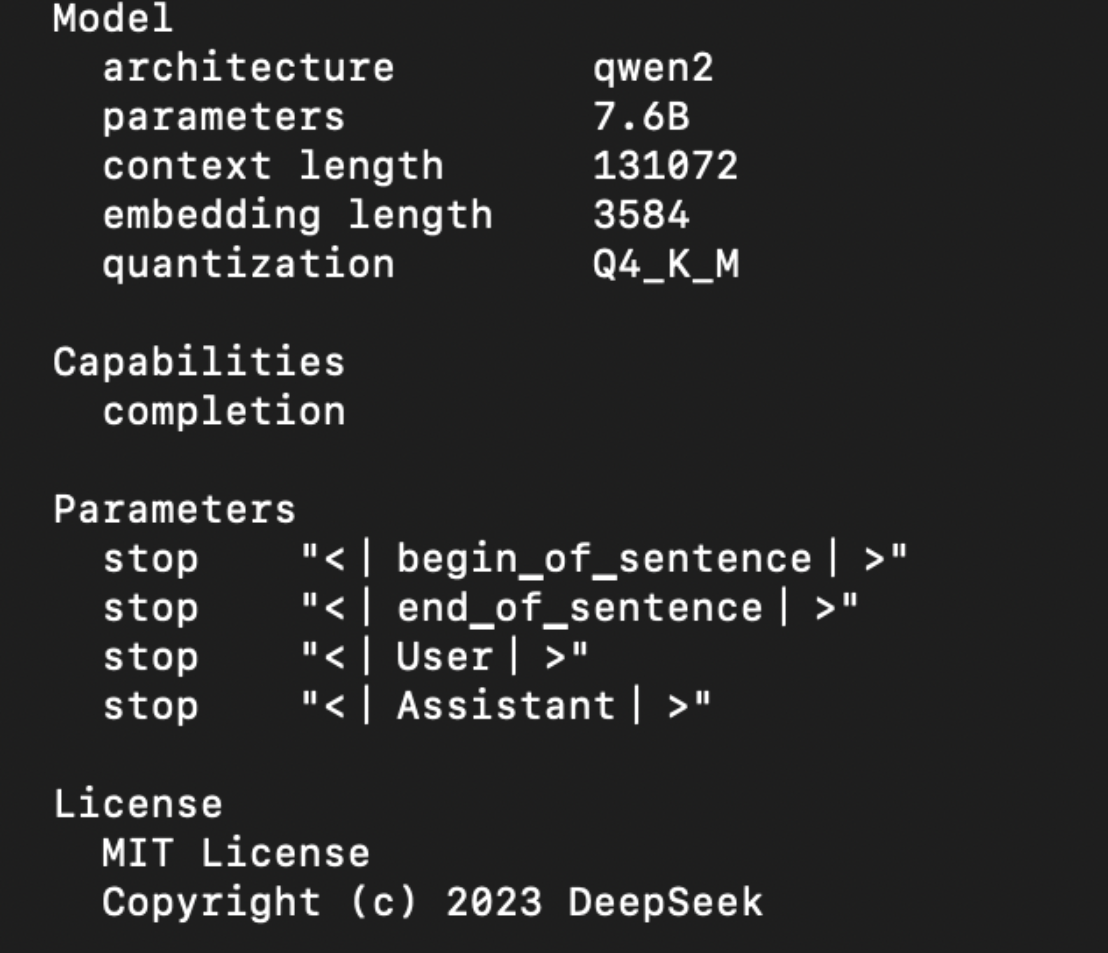
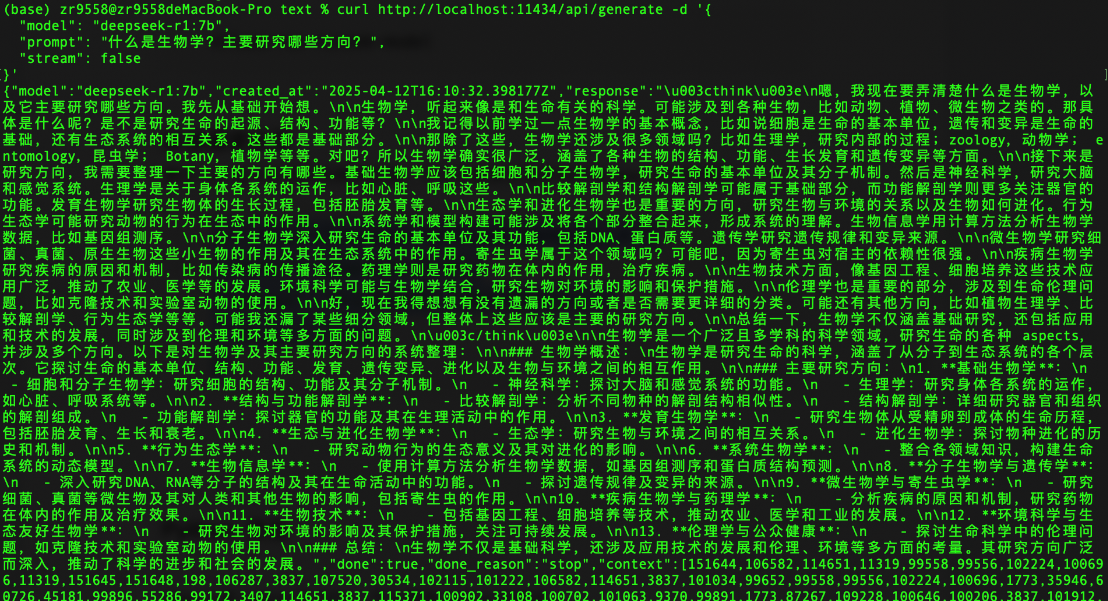
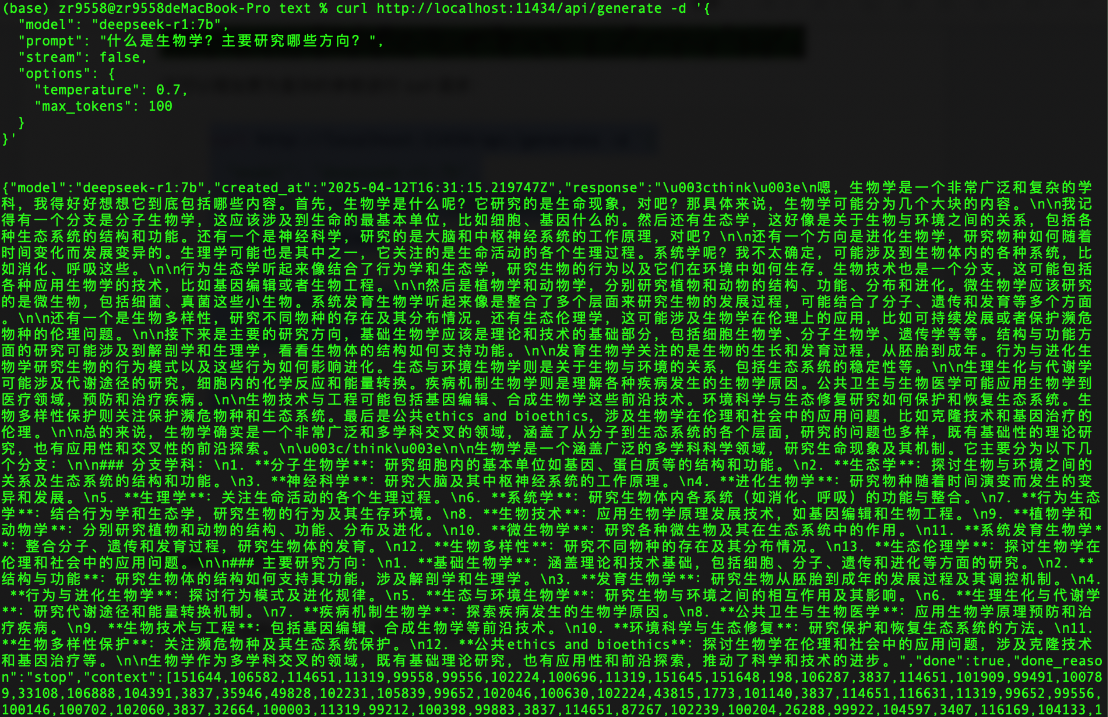
DeepSeek-r1会有不同的模型参数和大小,最少的模型参数是1.5b,最大的模型参数是671b。这些可以在Ollama的官网上找到,并且可以基于本地电脑的配置下载到本地电脑进行运行。在运行模型的时候,请注意mac的内存情况,以及参考Ollama官方提供的建议:You should have at least 8 GB of RAM available to run the 7B models, 16 GB to run the 13B models, and 32 GB to run the 33B models.
import ollama
print(ollama.embed(model='deepseek-r1:32b', input='The sky is blue because of rayleigh scattering'))
print(ollama.embed(model='deepseek-r1:32b', input='The sky is blue because of rayleigh scattering').embeddings)
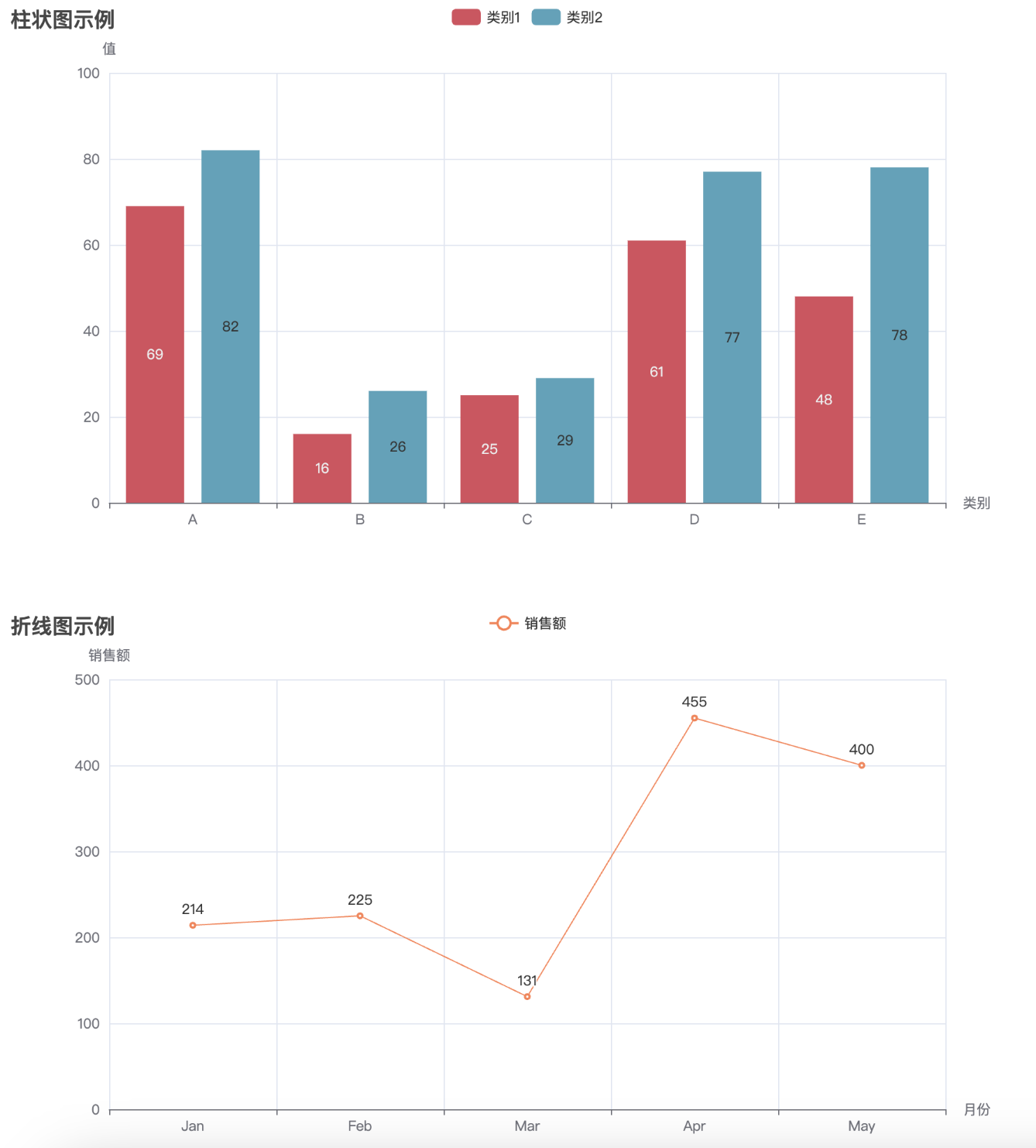
当我们掌握了各种图表的基本使用方法后,接下来一个非常重要的任务就是将这些图表有效地集成到网页中,展示数据的可视化效果。Pyecharts 提供了非常方便的功能,让我们能够将图表生成 HTML 文件,并嵌入到网页中进行展示。通过将图表集成到网页,用户不仅能够与数据进行互动,还能够获得更加直观、动态的展示效果。
在接下来的内容中,我们将详细介绍如何将多个图表(如柱状图、折线图、散点图等)融合到一个网页中,并通过 HTML 和 JavaScript 来增强页面的交互性和用户体验。通过这种方式,你可以将不同类型的图表展示在同一页面上,利用 Pyecharts 提供的丰富配置选项,轻松实现数据可视化的多样性和灵活性。
from pyecharts.charts import Bar, Line, Pie, Scatter, Page
from pyecharts import options as opts
import random
# 创建柱状图
bar = Bar()
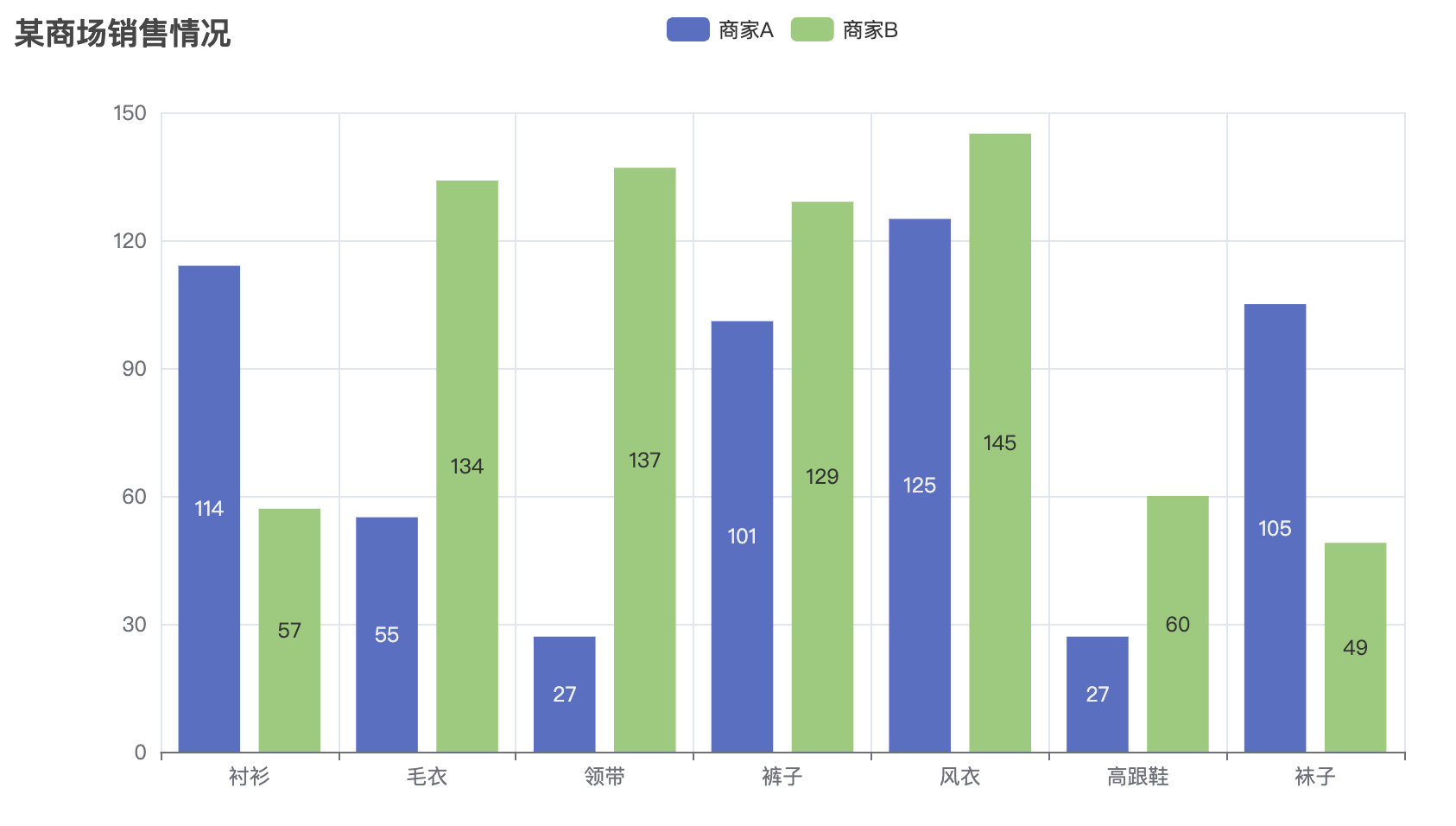
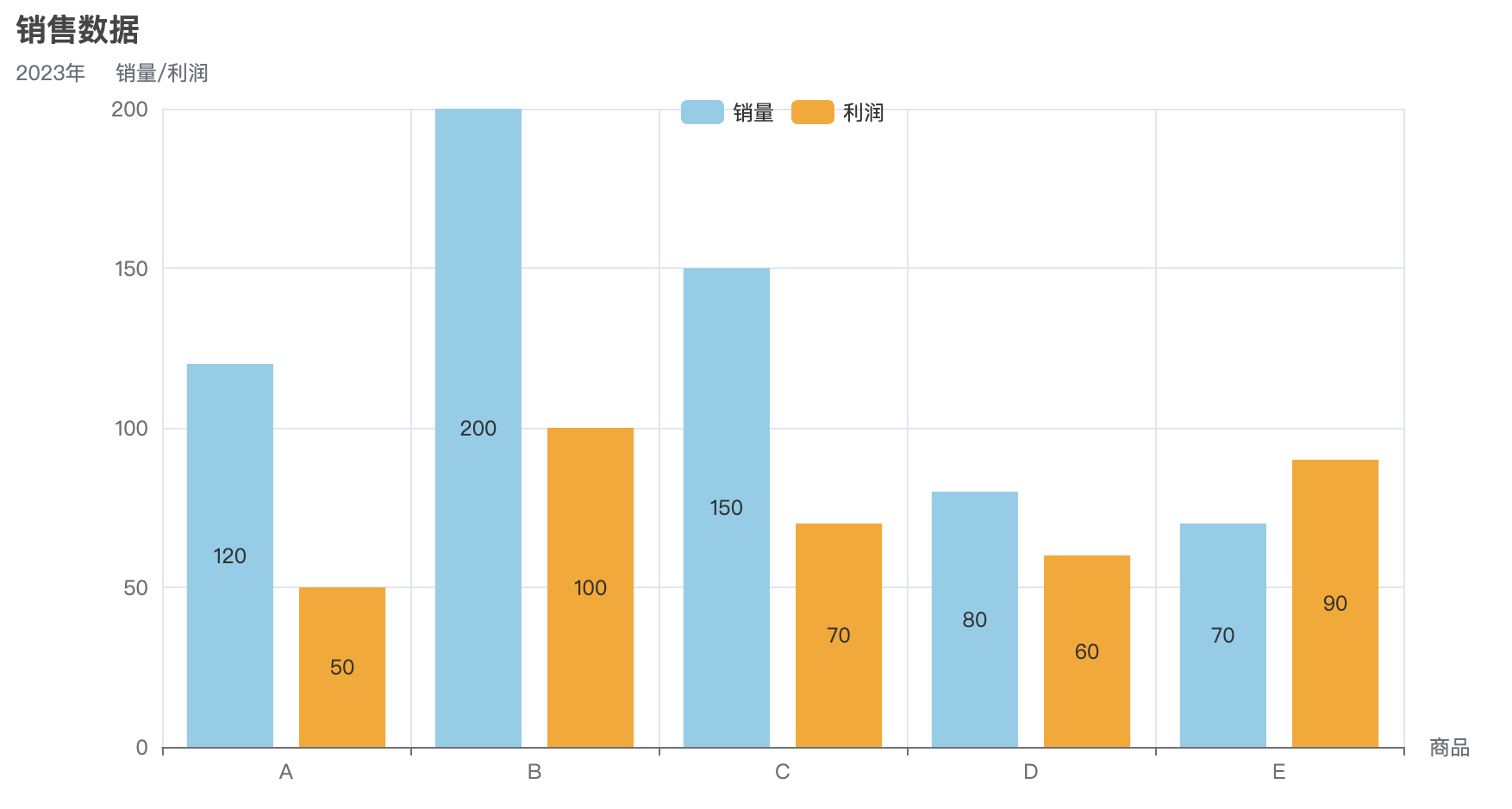
bar.add_xaxis(["A", "B", "C", "D", "E"])
bar.add_yaxis("类别1", [random.randint(10, 100) for _ in range(5)], color="#d94e5d")
bar.add_yaxis("类别2", [random.randint(10, 100) for _ in range(5)], color="#50a3ba")
bar.set_global_opts(
title_opts=opts.TitleOpts(title="柱状图示例"),
xaxis_opts=opts.AxisOpts(name="类别"),
yaxis_opts=opts.AxisOpts(name="值"),
)
# 创建折线图
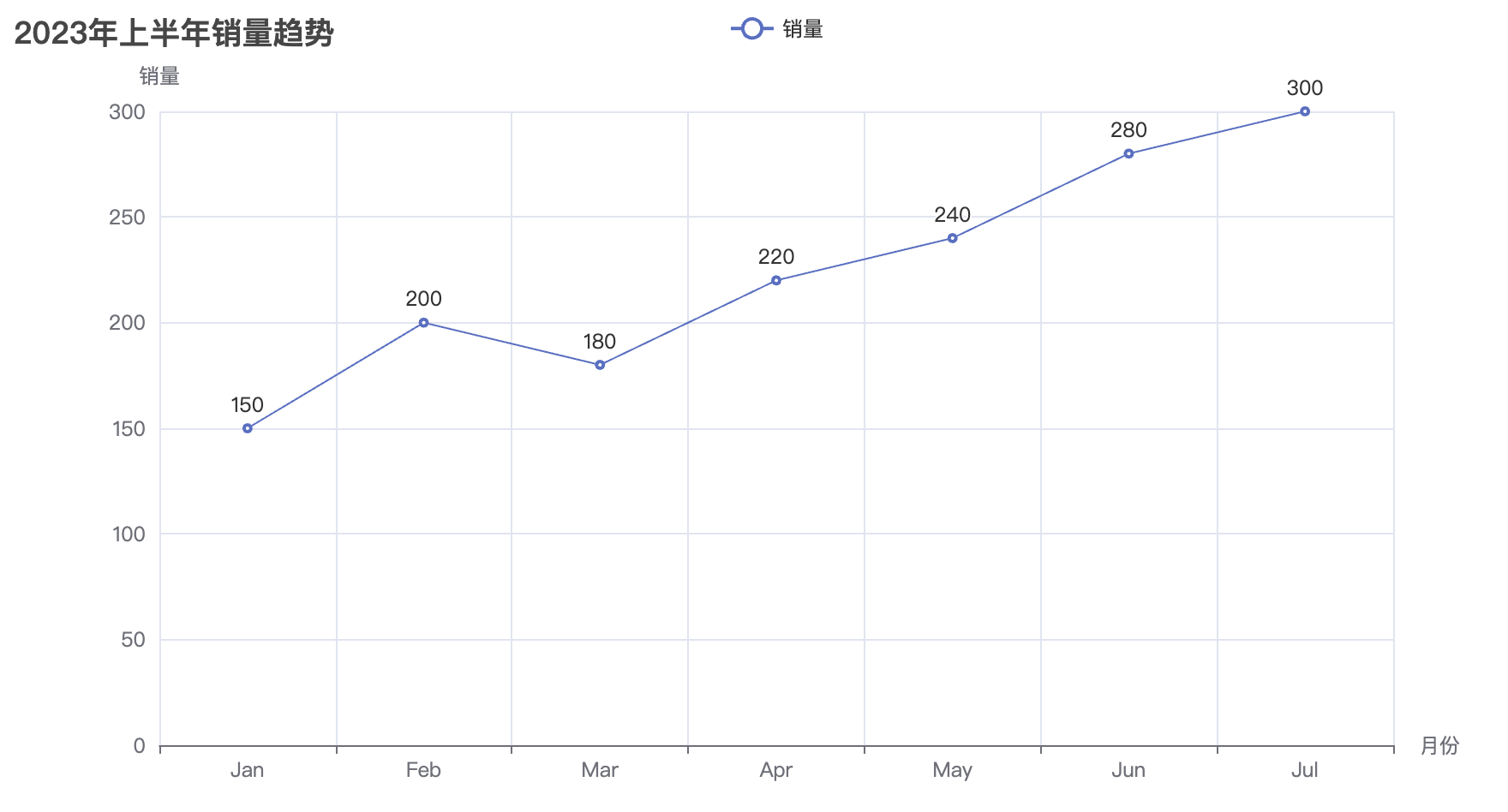
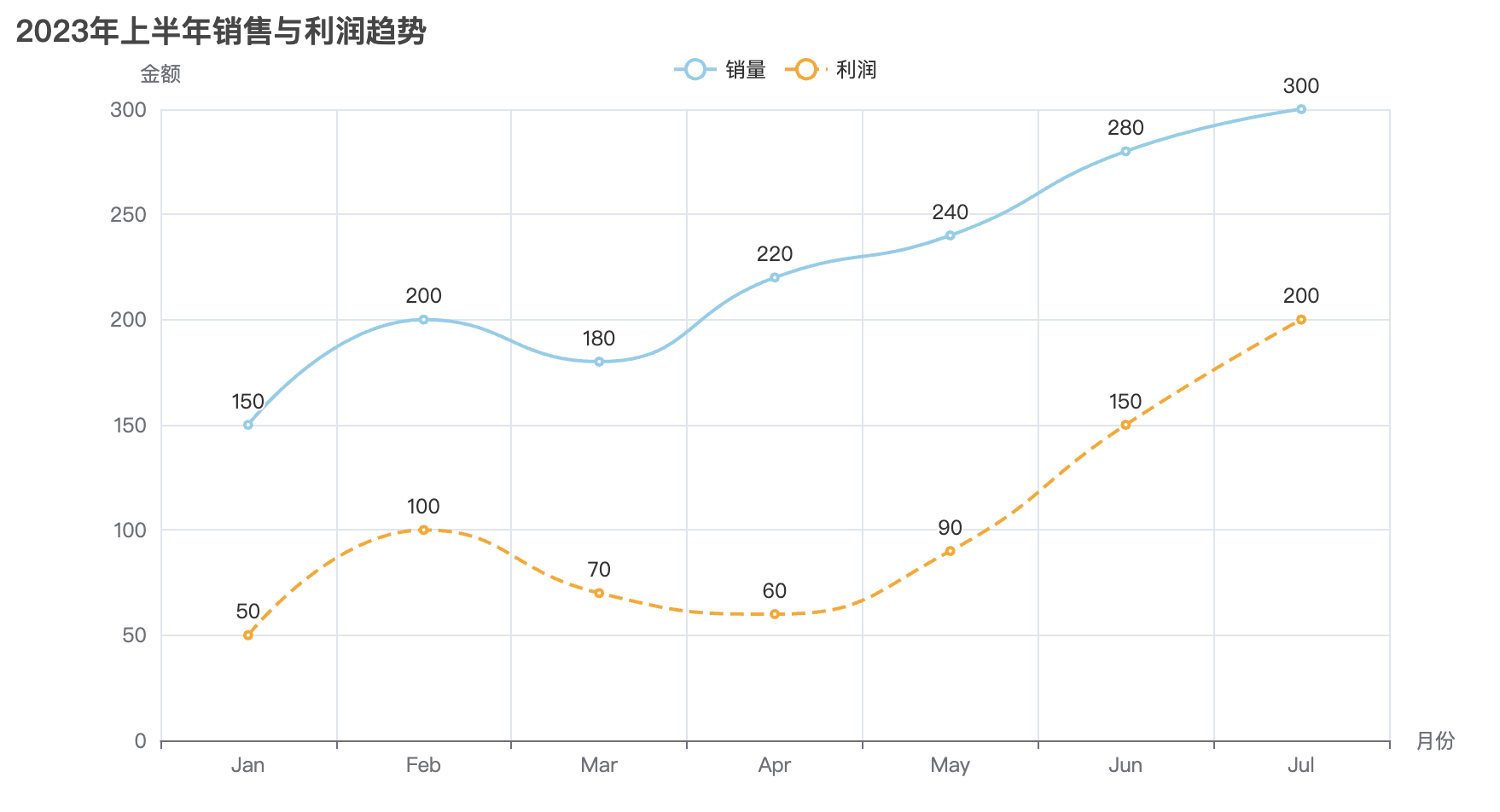
line = Line()
line.add_xaxis(["Jan", "Feb", "Mar", "Apr", "May"])
line.add_yaxis("销售额", [random.randint(100, 500) for _ in range(5)], color="#ff7f50")
line.set_global_opts(
title_opts=opts.TitleOpts(title="折线图示例"),
xaxis_opts=opts.AxisOpts(name="月份"),
yaxis_opts=opts.AxisOpts(name="销售额"),
)
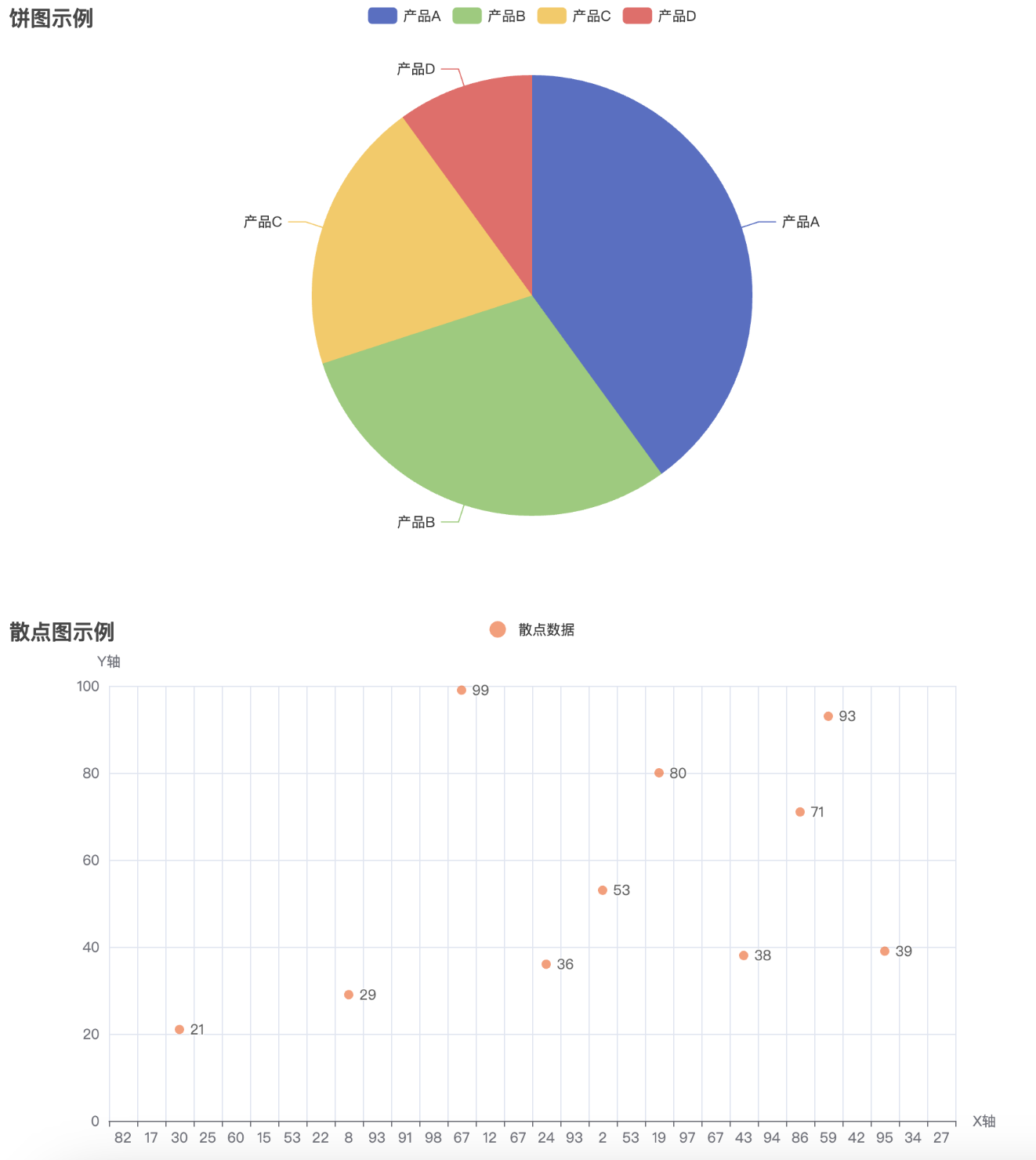
# 创建饼图
pie = Pie()
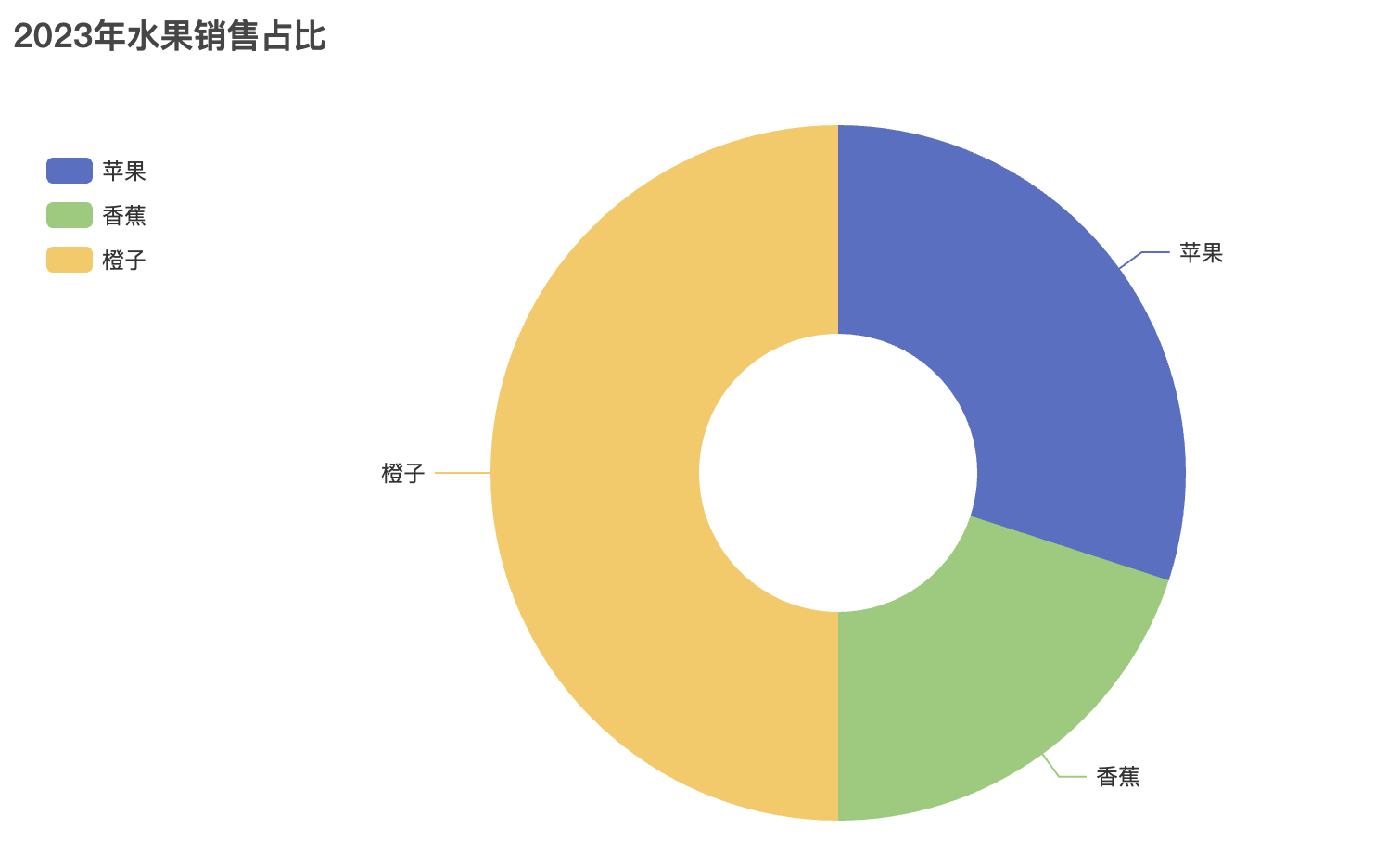
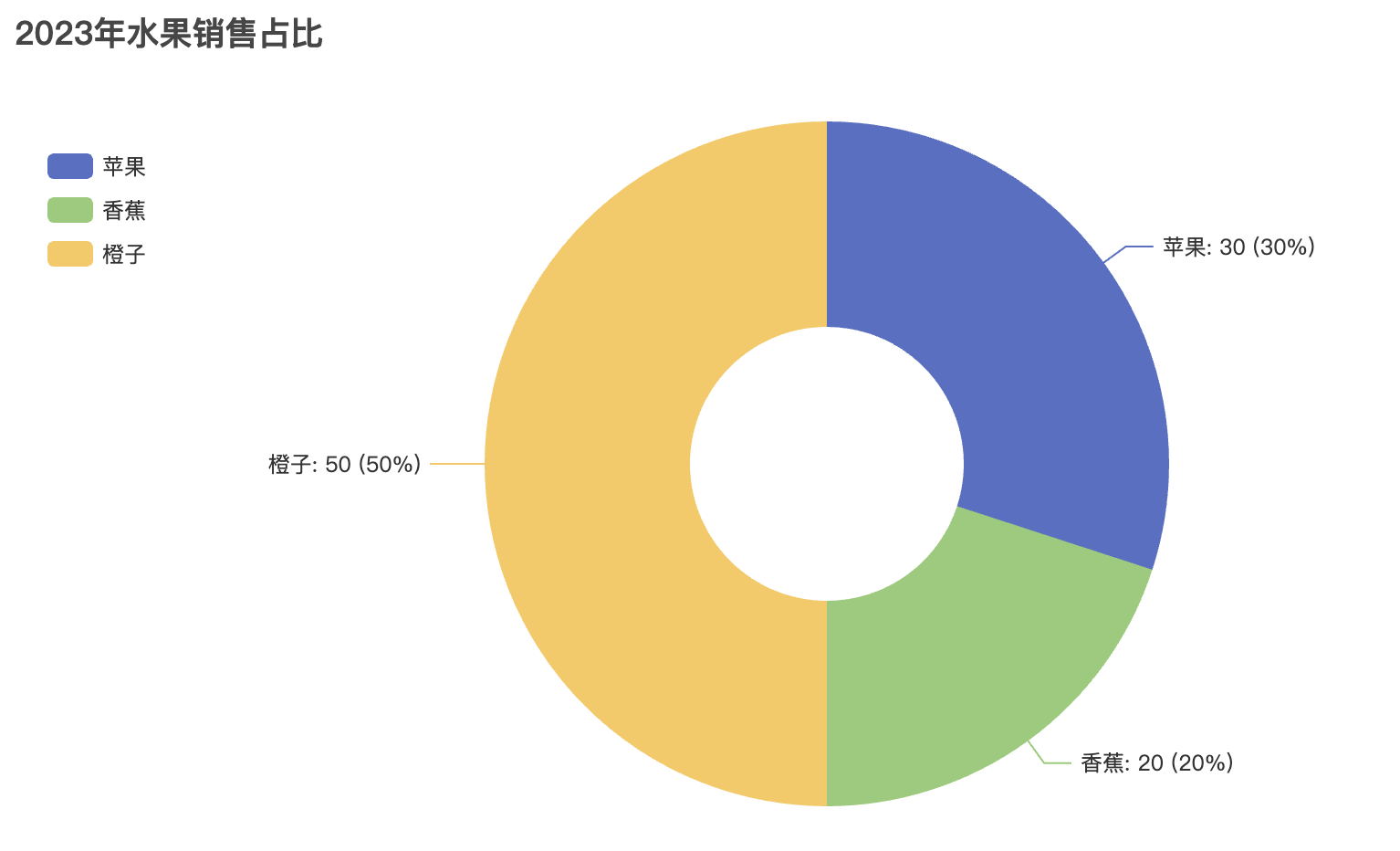
pie.add("产品占比", [("产品A", 40), ("产品B", 30), ("产品C", 20), ("产品D", 10)])
pie.set_global_opts(title_opts=opts.TitleOpts(title="饼图示例"))
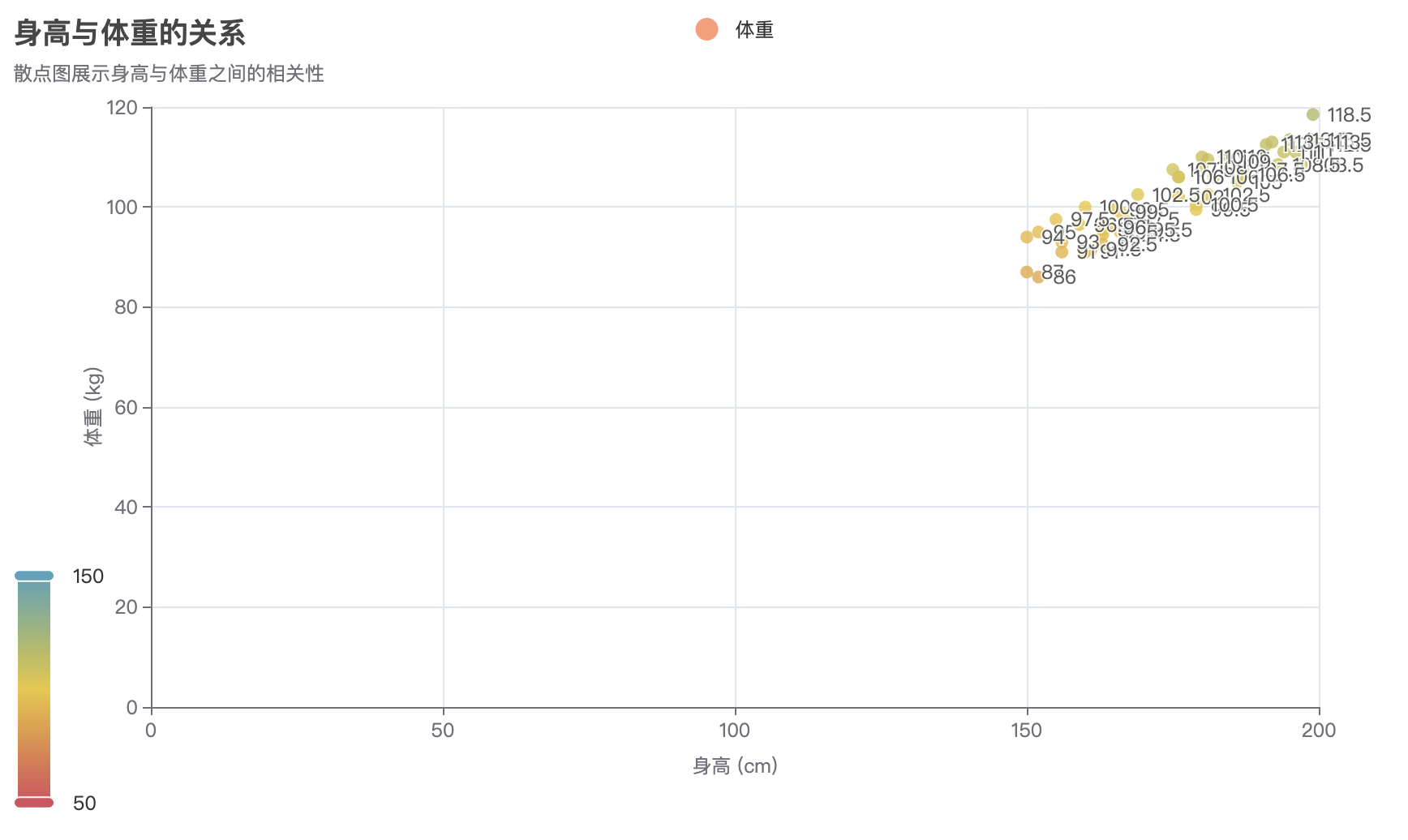
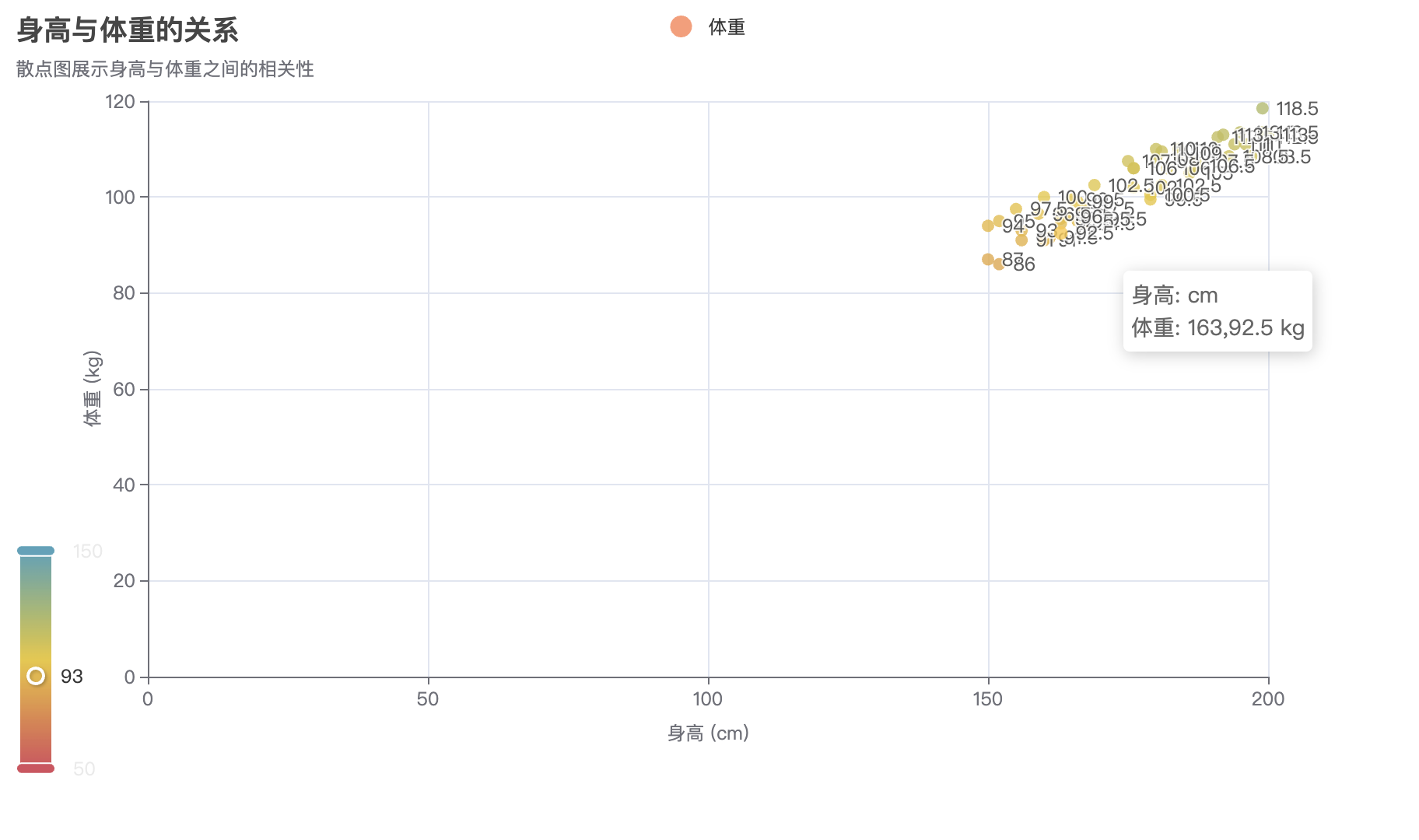
# 创建散点图
scatter = Scatter()
x_data = [random.randint(1, 100) for _ in range(30)]
y_data = [random.randint(1, 100) for _ in range(30)]
scatter.add_xaxis(x_data)
scatter.add_yaxis("散点数据", y_data, symbol_size=8, color="#ff7f50")
scatter.set_global_opts(
title_opts=opts.TitleOpts(title="散点图示例"),
xaxis_opts=opts.AxisOpts(name="X轴"),
yaxis_opts=opts.AxisOpts(name="Y轴"),
)
# 使用 Page 将多个图表放在一个页面中
page = Page()
page.add(bar, line, pie, scatter)
# 渲染页面到 HTML 文件
page.render("combined_chart.html")
print("所有图表已合并到 combined_chart.html 文件中。")
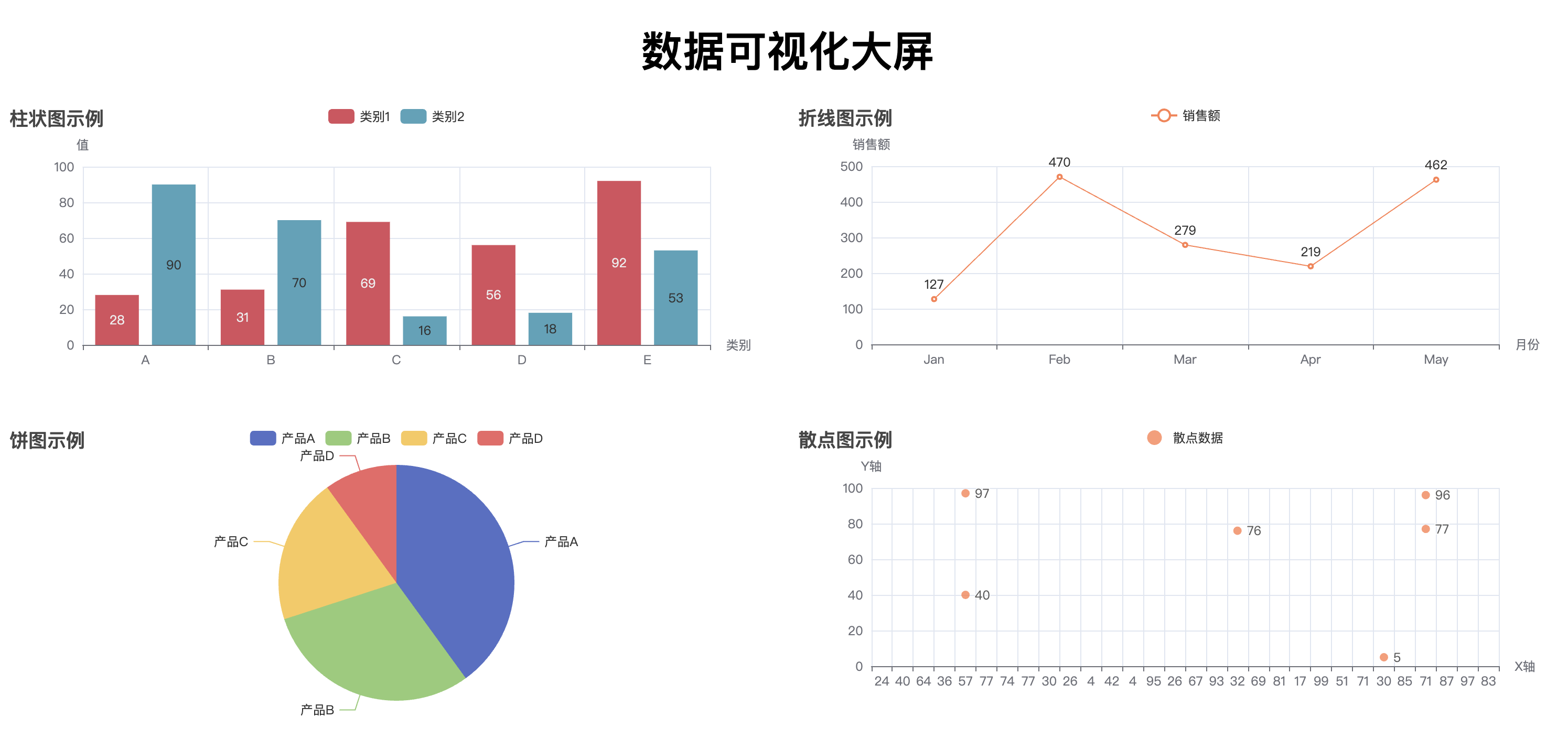
通过执行这段代码,最终会生成一个名为 combined_chart.html 的文件。打开该文件后,你将看到一个网页,包含四个图表(柱状图、折线图、饼图、散点图),它们将呈现在同一个页面中,用户可以浏览并查看不同图表的数据。通过 Pyecharts 提供的 Page 类,我们可以方便地将多个图表集成到一个 HTML 页面中进行展示,提升数据展示的效果和用户体验。
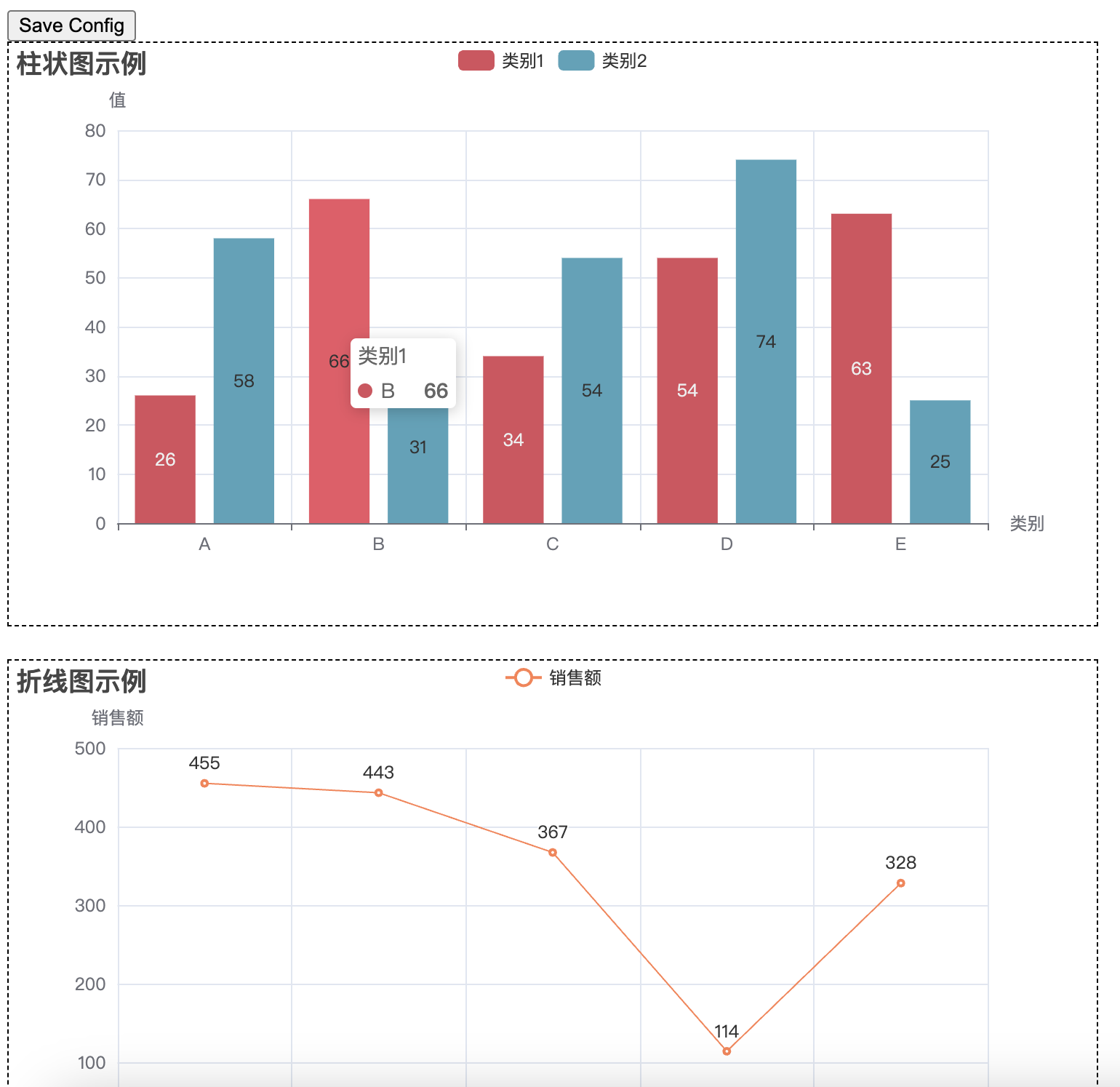
from pyecharts.charts import Bar, Line, Pie, Scatter, Page
from pyecharts import options as opts
import random
# 创建柱状图
bar = Bar(init_opts=opts.InitOpts(width="50%", height="400px"))
bar.add_xaxis(["A", "B", "C", "D", "E"])
bar.add_yaxis("类别1", [random.randint(10, 100) for _ in range(5)], color="#d94e5d")
bar.add_yaxis("类别2", [random.randint(10, 100) for _ in range(5)], color="#50a3ba")
bar.set_global_opts(
title_opts=opts.TitleOpts(title="柱状图示例"),
xaxis_opts=opts.AxisOpts(name="类别"),
yaxis_opts=opts.AxisOpts(name="值"),
)
# 创建折线图
line = Line(init_opts=opts.InitOpts(width="50%", height="400px"))
line.add_xaxis(["Jan", "Feb", "Mar", "Apr", "May"])
line.add_yaxis("销售额", [random.randint(100, 500) for _ in range(5)], color="#ff7f50")
line.set_global_opts(
title_opts=opts.TitleOpts(title="折线图示例"),
xaxis_opts=opts.AxisOpts(name="月份"),
yaxis_opts=opts.AxisOpts(name="销售额"),
)
# 创建饼图
pie = Pie(init_opts=opts.InitOpts(width="50%", height="400px"))
pie.add("产品占比", [("产品A", 40), ("产品B", 30), ("产品C", 20), ("产品D", 10)])
pie.set_global_opts(title_opts=opts.TitleOpts(title="饼图示例"))
# 创建散点图
scatter = Scatter(init_opts=opts.InitOpts(width="50%", height="400px"))
x_data = [random.randint(1, 100) for _ in range(30)]
y_data = [random.randint(1, 100) for _ in range(30)]
scatter.add_xaxis(x_data)
scatter.add_yaxis("散点数据", y_data, symbol_size=8, color="#ff7f50")
scatter.set_global_opts(
title_opts=opts.TitleOpts(title="散点图示例"),
xaxis_opts=opts.AxisOpts(name="X轴"),
yaxis_opts=opts.AxisOpts(name="Y轴"),
)
# 使用 Page 将多个图表放在一个页面中,调整为左右布局
page = Page(layout=Page.DraggablePageLayout, page_title="综合数据展示")
page.add(bar, line, pie, scatter)
# 渲染页面到 HTML 文件
page.render("combined_chart.html")
print("所有图表已合并到 combined_chart.html 文件中。")
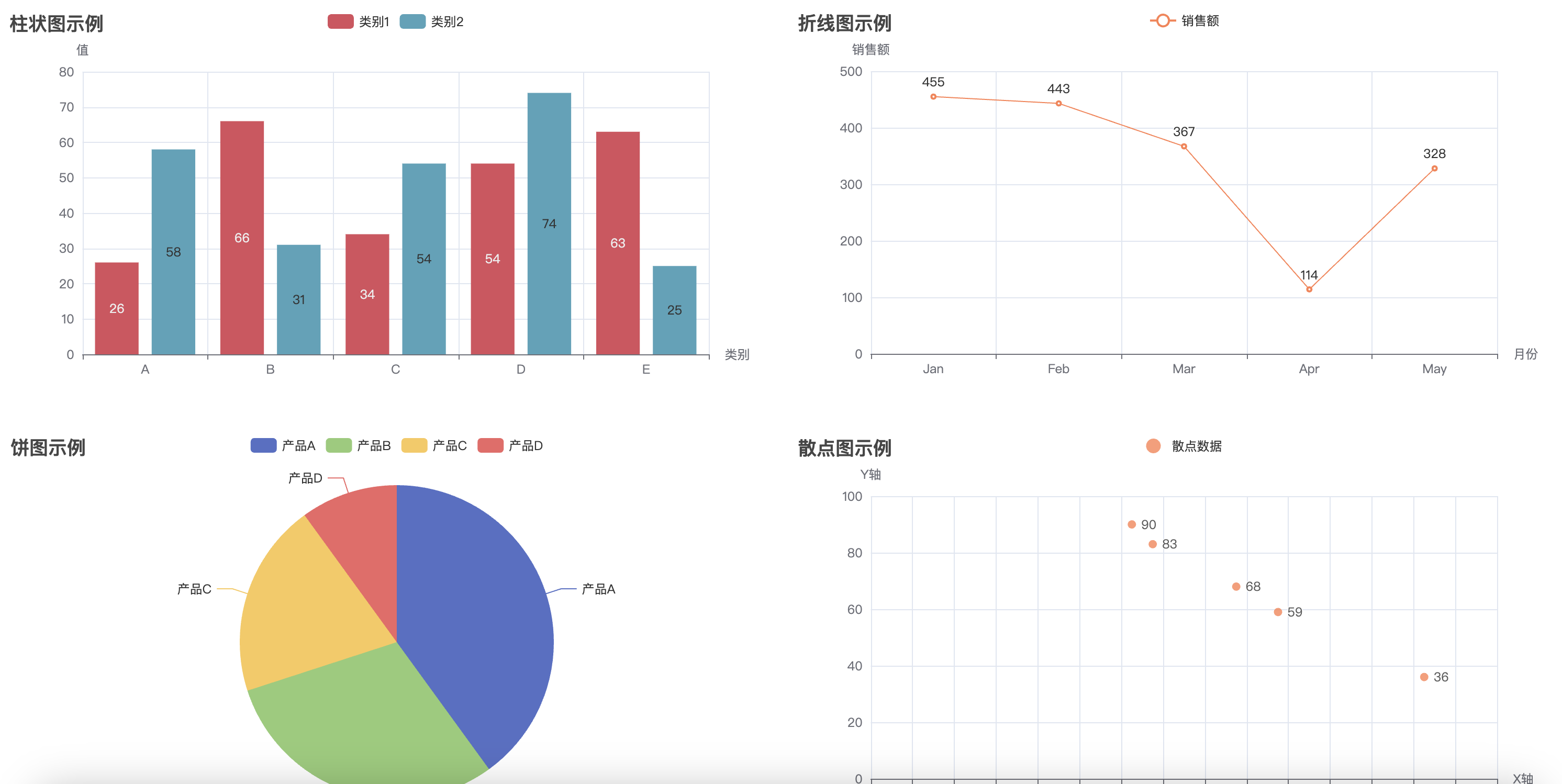
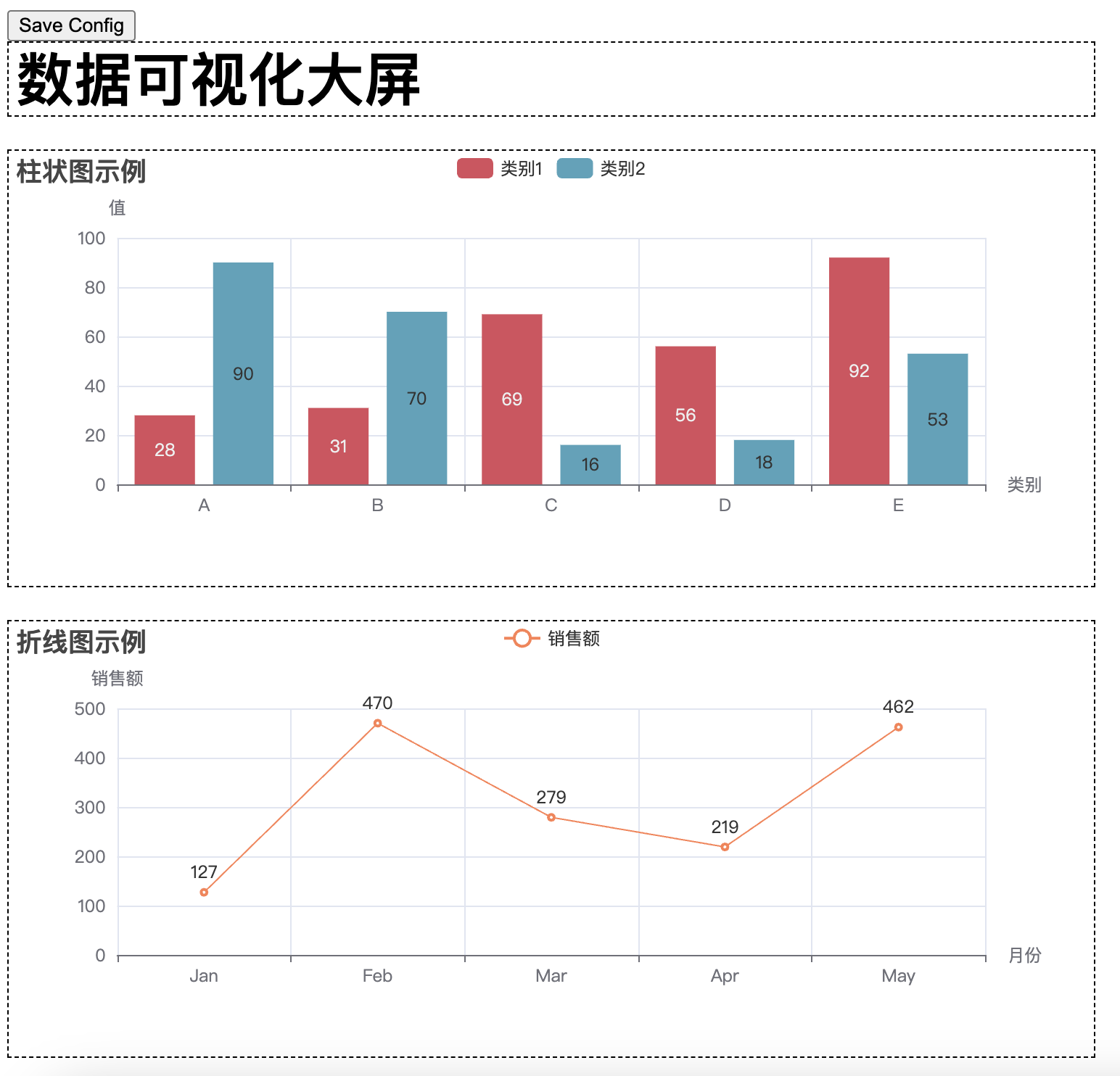
这样会形成一个可以拖拽式的网页,拖拽完成之后点击左上角的 Save Config 按钮,可以得到一个 chart_config.json 文件。然后写一个新的脚本,运行下面的代码,即可将原有的 html 文件(’combined_chart.html’)和 chart_config.json 文件一起生成新的 html 文件(’combined_chart_resize.html’)并且符合拖拽后的样式。
WARNING: This is a development server. Do not use it in a production deployment. Use a production WSGI server instead. Running on http://127.0.0.1:5000
在现代 Web 应用中,人工智能(AI)和机器学习(ML)算法的应用越来越广泛。将 AI 模型部署到 Web 服务中,可以让其他应用或用户通过 API 调用模型进行预测、分类、回归等任务。Flask 是一个轻量级的 Web 框架,非常适合将机器学习模型和 AI 算法封装成 API 服务。PyTorch 是一个流行的深度学习框架,广泛用于开发和训练神经网络。Flask 与 PyTorch 结合 可以实现将训练好的深度学习模型部署成 Web API,供外部应用调用。
当 AI 模型训练完成后,可以通过 Flask 构建 REST API,使得其他应用或前端可以轻松调用模型进行推理。Flask 作为一个轻量级的框架,能够快速构建 API 并且支持与 PyTorch 深度学习框架无缝对接。使用 Flask 和 Gunicorn 部署的 AI 模型,可以通过不同的方式进行扩展,如增加多台服务器、与其他微服务结合等。
构建 Flask API 服务与 PyTorch 模型结合
假设我们已经有了一个训练好的 PyTorch 模型,接下来将其部署为一个 Web 服务。以下是详细步骤:
Flask 使得将机器学习模型部署为 API 变得非常简单,适合快速开发和部署 AI 应用。PyTorch 是一个强大的深度学习框架,可以方便地加载训练好的模型进行推理,并与 Flask 紧密集成,提供 REST API 接口供其他系统或前端调用。通过结合使用 Flask 和 Gunicorn,可以让 AI 模型在生产环境中高效稳定地运行,满足高并发请求的需求。这种 Flask 与 PyTorch 的结合应用非常适合用于构建机器学习服务、推荐系统、图像处理、自然语言处理等领域的 Web 应用。
强化学习是人工智能领域一个非常重要的分支,在游戏 AI 领域的应用是无处不在的,包括大家耳熟能详的 AlphaGo 和王者荣耀,其背后都使用了大量的强化学习方法。随着人工智能技术在互联网公司的日渐普及,人们对人工智能的期待也越来越高,也期待着人工智能未来能够做更多的事情。除了各种门禁系统,人脸识别系统在各个公司的应用之外,在游戏领域,强化学习也扮演着举足轻重的作用。
当前的强化学习技术除了使用在游戏 AI 领域之外,也在机器人控制,推荐系统等领域有着很多应用,也取得了不少商业价值。但强化学习的学习还是存在一定的门槛,除了一些在线的 tutorial 和零零散散的资料之外,其实还是需要一本相对完整和优秀的教材来辅助高校的老师和学生,只有这样,强化学习才能够成为一门课进入高校课堂。