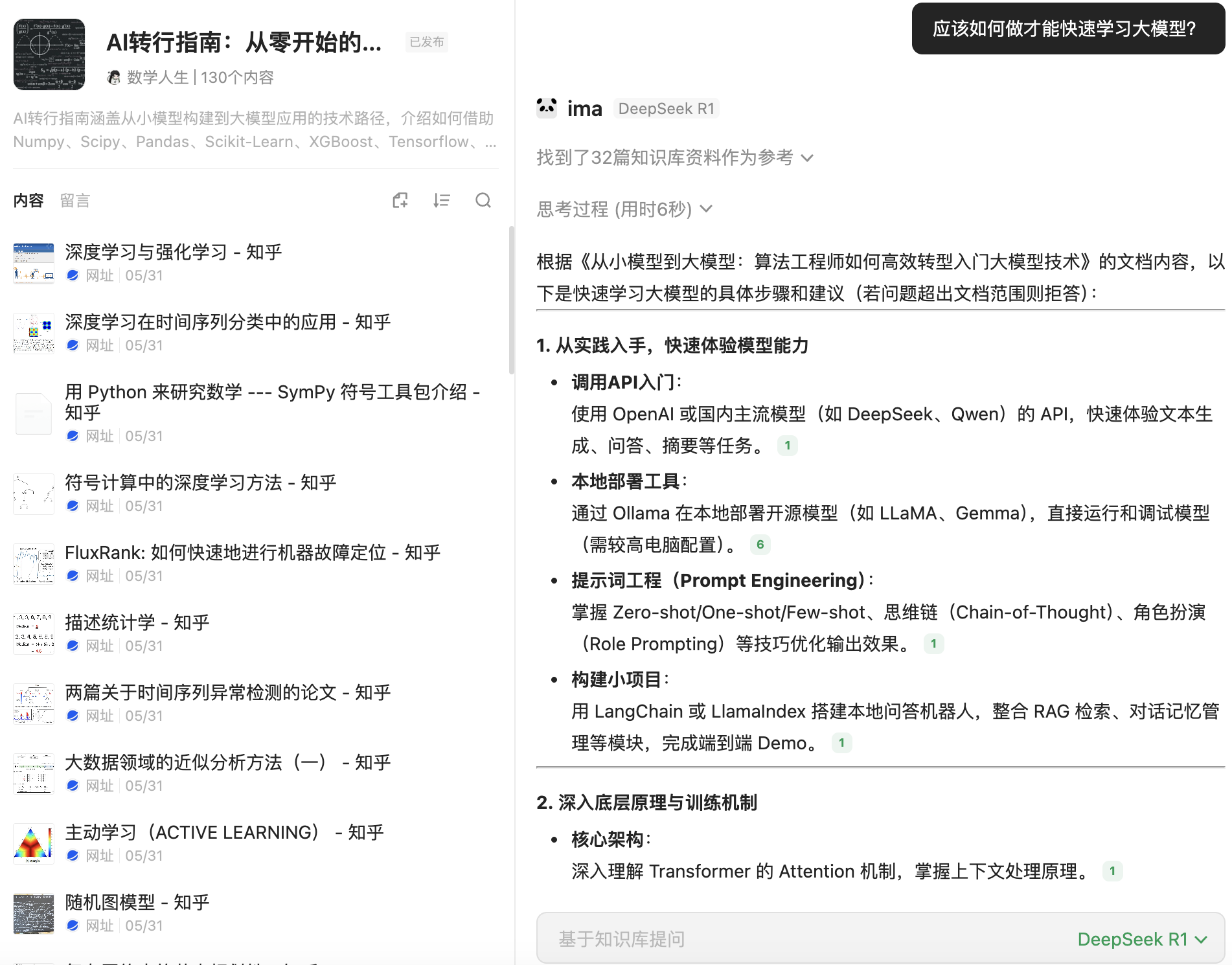
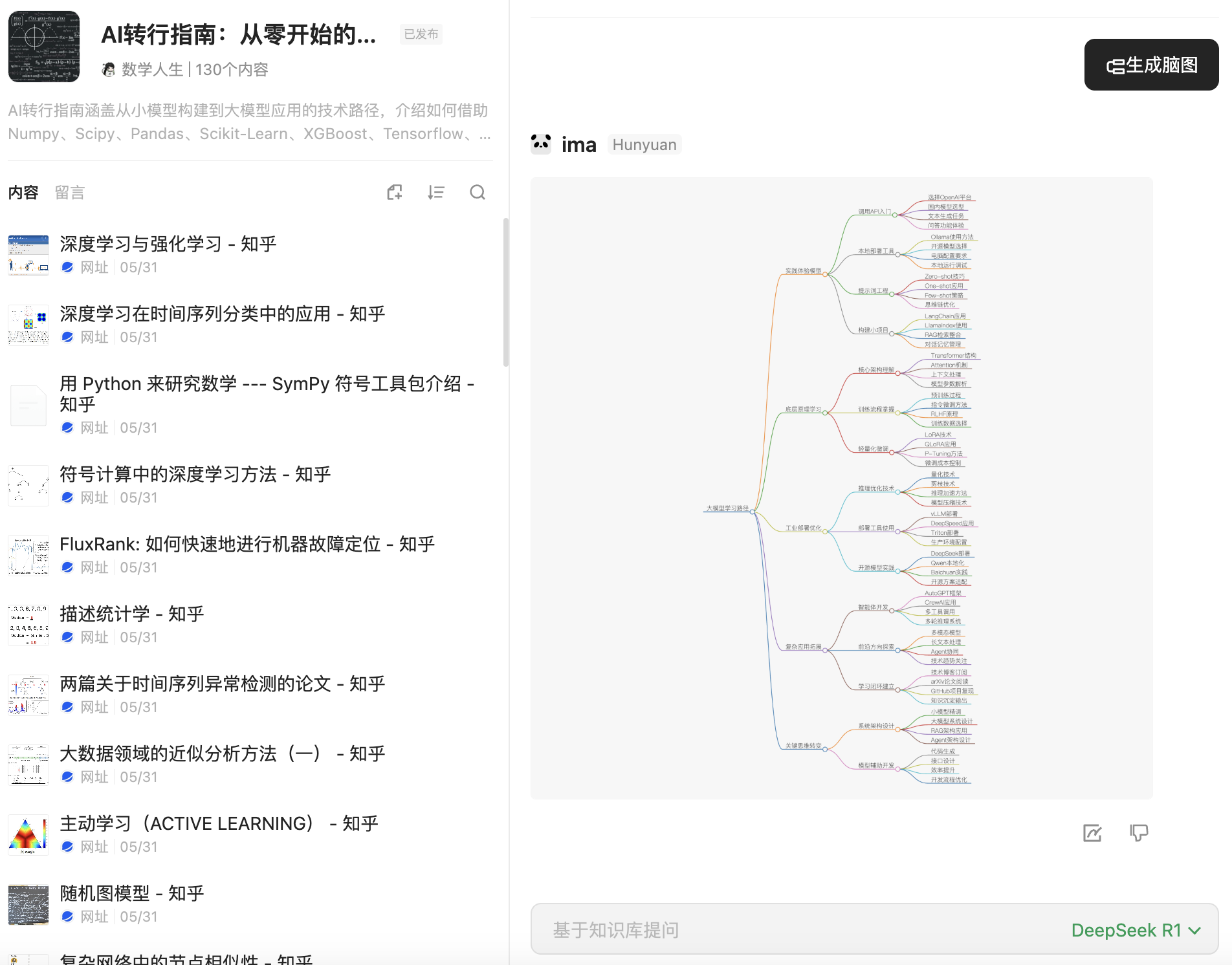
在Python的测试生态中,pytest无疑是一颗耀眼的明星。它以简洁、灵活和强大的功能深受开发者喜爱。无论是小型项目的单元测试,还是大型系统的集成测试,pytest 都能提供良好的支持。本文将从多个方面介绍pytest的特性,并总结其优势与常见用法。
1. 为什么选择 pytest?
在 Python 标准库中,unittest提供了基本的单元测试功能,符合 xUnit 测试架构风格。然而,随着项目复杂度的提升和测试需求的增长,开发者往往希望有一个更加轻量、直观并易于扩展的测试工具。pytest 正是在这种背景下应运而生,它以其更简洁的语法、更人性化的断言机制和强大的插件支持,逐渐成为 Python 测试的主流选择。
相比 Python 自带的 unittest 模块,pytest 提供了更简洁的语法、更丰富的断言能力以及强大的插件系统。例如,使用 pytest 可以直接编写函数式测试,不必将测试代码包装成类。其断言语句也更加直观,不需要调用 assertEqual、assertTrue 等繁琐方法,直接使用 assert 语句即可自动生成详细的错误报告。
1.1 语法简洁,测试函数式写法更直观
假设现在使用的脚本的名称叫做 learn_pytest_1.py。在 unittest 中,编写测试必须继承 unittest.TestCase 并将测试方法命名为 test_ 开头,形式如下:
# 使用 unittest 的写法
import unittest
def add(x, y):
return x + y
class TestAdd(unittest.TestCase):
def test_add(self):
self.assertEqual(add(1, 2), 3)
self.assertEqual(add(-1, 1), 0)
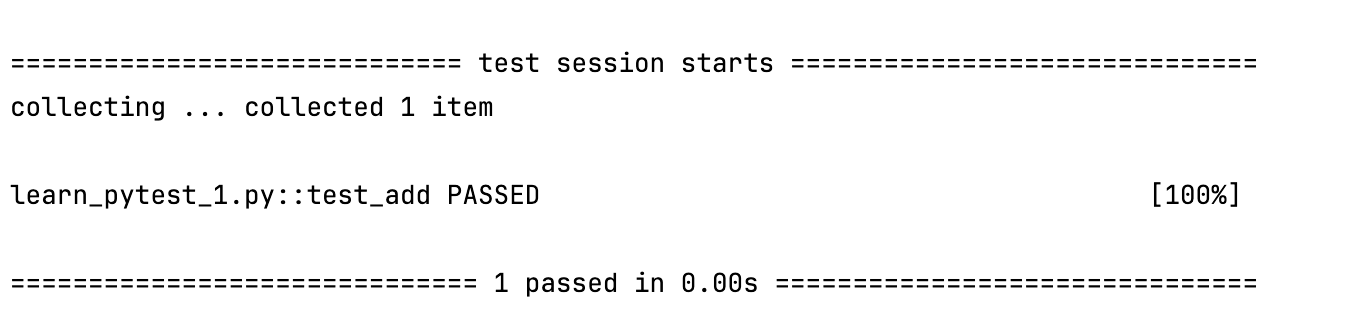
这段代码在 PyCharm 中的运行结果就是:
而在 pytest 中,可以直接写函数式的测试,不需要类结构,语法更加自然:
# 使用 pytest 的写法
def add(x, y):
return x + y
def test_add():
assert add(1, 2) == 3
assert add(-1, 1) == 0
这种简化不仅减少了模板代码,也更贴近 Python 的编程风格,其结果展示如下:
1.2 断言机制更强大
在 unittest 中,必须使用专门的断言方法,如 assertEqual、assertTrue 等,每种判断场景都需要一个对应的方法:
self.assertIn(item, container)
self.assertIsInstance(obj, SomeClass)
self.assertAlmostEqual(a, b, places=2)
而 pytest 只需要使用 Python 原生的 assert 语句。最关键的是,pytest 会在断言失败时自动分析表达式内容,生成详细的错误信息。例如:
def test_example():
a = 5
b = 3
assert a + b == 10
如果失败,pytest 输出类似如下信息:
> assert a + b == 10
E assert 8 == 10
E + where 8 = (5 + 3)
而 unittest 仅提示 AssertionError: 8 != 10,缺乏上下文,调试成本更高。
1.3 测试发现机制更灵活
unittest 通常需要手动添加测试套件或使用 python -m unittest discover 来运行,而 pytest 则具有自动发现功能,只需执行 pytest 命令即可自动查找所有以 test_ 开头的函数或方法,并运行之。无需配置即可开箱即用。
2. 安装与基本用法
2.1 安装 pytest
pytest 支持 Python 3.7 及以上版本,可以通过 pip 一键安装:
如果你希望安装测试覆盖率工具等附加功能,可以使用组合命令:
pip install pytest pytest-cov
建议在虚拟环境中安装以避免依赖冲突。创建虚拟环境的方法如下:
python -m venv venvsource venv/bin/activate # Windows 下为 venv\Scripts\activatepip install pytest
2.2 测试文件与函数命名规范
为了让 pytest 自动发现测试文件和函数,需遵循以下命名规则:
测试文件名:以 test_ 开头或 _test.py 结尾,如:
测试函数名:以 test_ 开头,如:
示例代码:
# 文件名:test_sample.py
def multiply(x, y):
return x * y
def test_multiply():
assert multiply(2, 3) == 6
assert multiply(-1, 5) == -5
运行的结果如下所示:
2.3 运行测试
只需在包含测试文件的目录下执行 pytest 命令,pytest 会递归扫描所有子目录中的符合规范的测试文件并运行。
运行后,你会看到类似以下输出。
============================= test session starts ==============================
collected 2 items
test_sample.py .. [100%]
============================== 2 passed in 0.01s ===============================
其中,. 表示有一个测试通过,.. 表示有两个测试通过。
2.4 常用命令选项
pytest 提供了丰富的命令行参数,可以灵活控制测试行为:
运行指定文件或目录:
pytest tests/ # 运行 tests 目录下所有测试pytest test_math.py # 运行指定文件
运行指定测试函数:
pytest test_math.py::test_add
显示更详细的输出信息:
只运行上次失败的测试:
生成覆盖率报告(需要安装 pytest-cov):
pytest --cov=my_package tests/
停止在第一个失败的测试:
2.5 测试结构推荐(项目组织)
对于中小型项目,可以采用以下结构:
my_project/
├── src/
│ └── my_module.py
├── tests/
│ ├── __init__.py
│ └── test_my_module.py
└── requirements.txt
可以在 tests/ 目录中编写所有测试脚本,通过 pytest tests/ 来集中运行。
2.6 测试失败时的调试
pytest 提供了失败断点和调试钩子,可以在测试失败时立即进入调试模式:
或者,在测试代码中显式加入 import pdb; pdb.set_trace() 进行调试。
3. 进阶功能
3.1 Fixtures:高效的测试准备与清理
在实际的测试中,往往需要对某些资源(如数据库连接、文件操作、网络请求等)进行初始化,并在测试完成后清理这些资源。pytest 提供了 Fixtures 来帮助我们管理这些过程,尤其在多次运行的测试中,可以有效避免重复代码。
3.1.1 基本用法
使用 @pytest.fixture 装饰器可以创建一个 Fixture。Fixture 通常返回一个资源或对象,供测试函数使用。
import pytest
# 定义一个 fixture,提供测试用的字典
@pytest.fixture
def sample_data():
return {"name": "Alice", "age": 30}
# 测试函数通过参数使用 fixture
def test_user_name(sample_data):
assert sample_data["name"] == "Alice"
def test_user_age(sample_data):
assert sample_data["age"] == 30
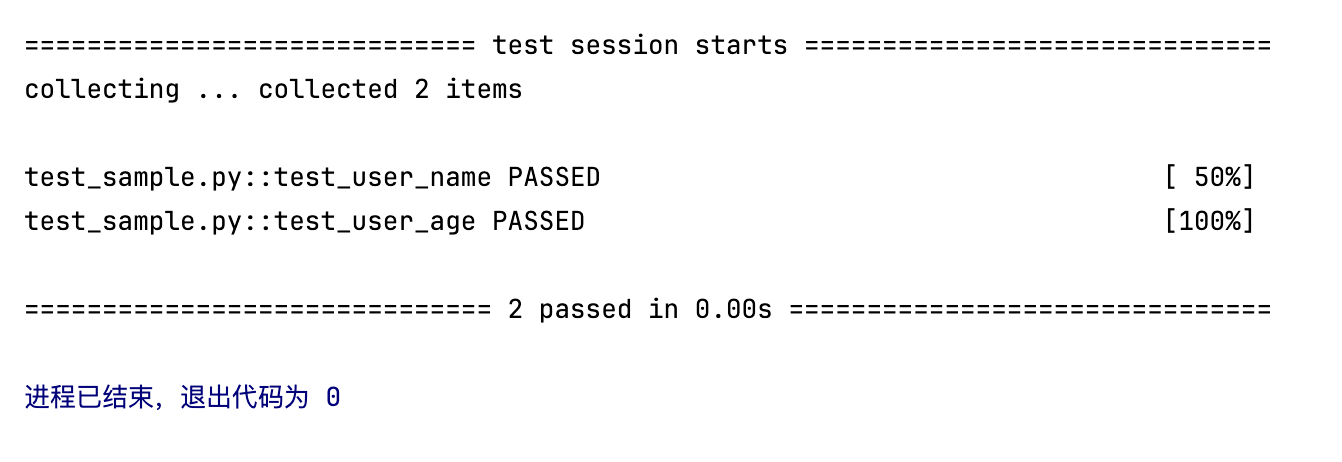
在这个例子中,sample_data 是一个 Fixture,它提供一个字典对象,供测试函数 test_user_name 和 test_user_age 使用。pytest 会自动将 sample_data 传递给测试函数。
3.1.2 Fixture 作用域
Fixture 支持不同的作用域,这意味着可以控制 fixture 生命周期的长短,具体有四种作用域:
- function:函数级,每个测试函数都会调用一次该 fixture(默认值)。
- class:类级别,每个测试类调用一次该 fixture。
- module:模块级别,每个测试模块调用一次该 fixture。
- session:会话级别,整个测试会话只调用一次该 fixture。
import pytest
@pytest.fixture(scope="module")
def db_connection():
print("\nSetting up database connection")
conn = create_db_connection()
yield conn
print("\nTearing down database connection")
conn.close()
在这个示例中,db_connection fixture 会在模块级别共享,且只会在整个模块执行前后各调用一次。这对于需要在多个测试函数间共享的资源非常有用。
3.1.3 自动化 Fixture
如果不想显式地在每个测试函数中传入 fixture,可以通过 pytest 的自动化机制来实现。例如,可以通过 autouse=True 参数让 pytest 自动注入 fixture,而无需在测试函数中显式引用:
import pytest
@pytest.fixture(autouse=True)
def setup_env():
print("\nSetting up test environment")
yield
print("\nTearing down test environment")
3.2 参数化测试:一行代码跑遍所有情况
pytest 提供了强大的参数化功能,使得我们可以一次性测试多个输入组合,从而避免编写大量重复的测试代码。
3.2.1 基本用法:@pytest.mark.parametrize
使用 @pytest.mark.parametrize 装饰器,我们可以在一个测试函数中传入多个不同的参数组合,pytest 会为每一组数据运行一次测试。
import pytest
@pytest.mark.parametrize("a,b,expected", [
(1, 2, 3),
(2, 3, 5),
(10, 20, 30)
])
def test_add(a, b, expected):
assert a + b == expected
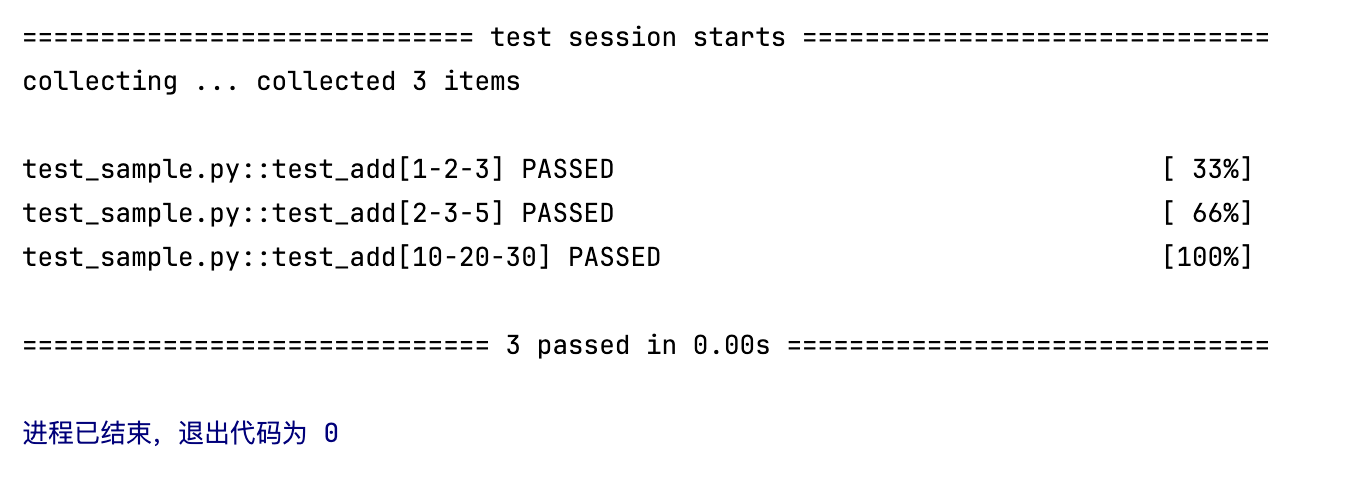
在这个例子中,test_add 会被执行三次,分别使用 (1, 2, 3)、(2, 3, 5) 和 (10, 20, 30) 这三组参数来验证加法操作。
3.2.2 参数化与 Fixtures 结合
你还可以将 pytest.mark.parametrize 与 Fixtures 结合,进行更加灵活的测试设计。例如,你可以使用一个 fixture 来准备数据,再对不同数据组合进行测试:
import pytest
@pytest.fixture
def input_data():
return [1, 2, 3]
@pytest.mark.parametrize("x, y", [(1, 2), (2, 3), (3, 4)])
def test_add(input_data, x, y):
assert x + y in input_data
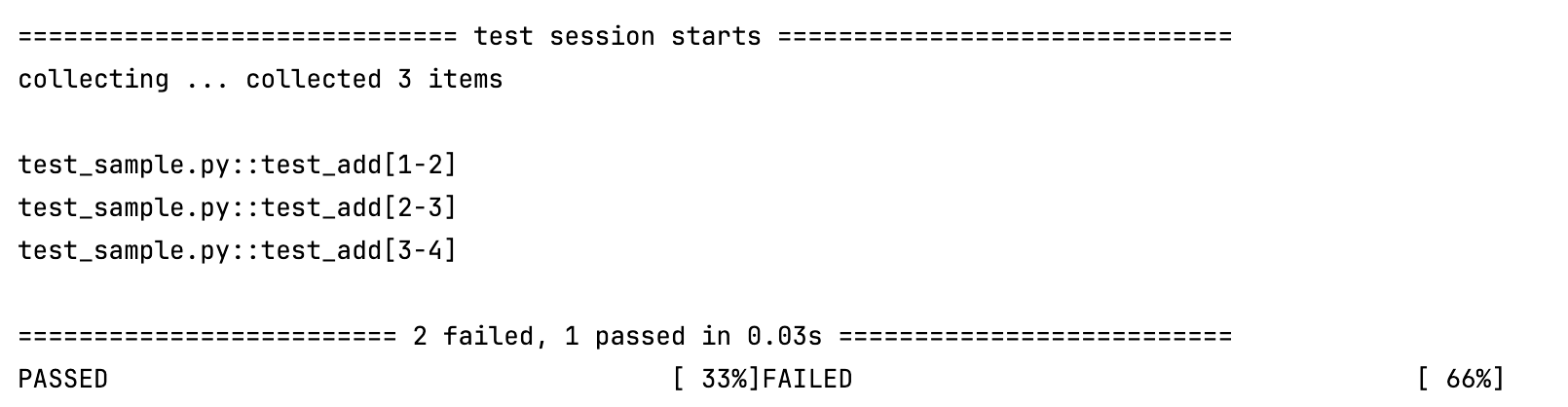
这里,input_data fixture 提供了一个列表,pytest.mark.parametrize 会让测试用例分别使用 (1, 2)、(2, 3) 和 (3, 4) 进行测试,同时验证结果是否在 input_data 列表中。只有第一个案例 (1, 2) 通过了测试。
3.2.3 参数化测试与预期异常
pytest.mark.parametrize 同时支持测试预期的异常。例如,某个函数在特定输入下会抛出异常,可以通过 pytest.raises 配合 @pytest.mark.parametrize 来进行验证:
import pytest
@pytest.mark.parametrize("input_value", ["a", "", None])
def test_invalid_string(input_value):
with pytest.raises(ValueError):
process_string(input_value)
在这个例子中,test_invalid_string 会测试不同的无效输入,检查是否会抛出 ValueError 异常。
3.2.4 参数化大数据集
如果需要测试一个非常大的数据集,pytest 支持通过数据驱动的方式快速生成多个测试用例,而不会让每个数据都显式地写出来。可以结合生成器来实现:
import pytest
@pytest.mark.parametrize("num", range(100))
def test_large_dataset(num):
assert num % 2 == 0 # 示例断言:测试数字是否为偶数
上面的测试将会对 0 到 99 之间的数字逐一进行验证。
4. 插件生态与工具集成
pytest 之所以成为 Python 社区主流的测试框架,不仅在于其核心功能强大,更重要的是拥有一个活跃、丰富的插件生态系统,几乎可以适配所有常见的测试场景。同时,它也具备极强的兼容性,可以轻松与主流的 CI/CD 工具集成,实现自动化测试流水线。
pytest 拥有丰富的插件生态,常用插件包括:
- pytest-cov:测试覆盖率报告;
- pytest-mock:与 unittest.mock 的集成;
- pytest-xdist:并行测试,加快执行速度;
- pytest-django、pytest-flask:与 Web 框架集成。
此外,pytest 与 CI/CD 工具(如 GitHub Actions、GitLab CI、Jenkins)结合良好,是自动化测试的重要组成部分。
4.1. 常用插件介绍
4.1.1 pytest-cov:测试覆盖率分析
pytest-cov 是基于 coverage.py 的插件,用于生成测试覆盖率报告。使用方式如下:
pip install pytest-covpytest --cov=my_module tests/
它可以输出命令行摘要,也可以生成 HTML 报告:
pytest --cov=my_module --cov-report=html
生成的 htmlcov/index.html 可在浏览器中打开,直观查看哪些代码行未被测试覆盖,是测试优化的重要工具。
4.1.2 pytest-mock:更便捷的 mock 工具
虽然 Python 的标准库 unittest.mock 功能很强,但书写稍显繁琐。pytest-mock 提供了 mocker fixture,可以更简洁地进行打桩和模拟:
示例:
def get_user_name():
return external_api.get_name()
def test_mock_name(mocker):
mock = mocker.patch("external_api.get_name", return_value="Alice")
assert get_user_name() == "Alice"
无需手动清理 mock,pytest-mock 会自动恢复原状,避免副作用。
4.1.3 pytest-xdist:并行化测试执行
在测试用例较多或测试时间较长的项目中,使用 pytest-xdist 可以显著加快测试执行速度。它支持多核并发运行测试,还可以分布式运行。
pip install pytest-xdist
pytest -n auto # 根据 CPU 核心数自动并发
pytest -n 4 # 指定使用 4 个 worker 并行
它还能结合缓存机制和失败重试,提高测试效率和稳定性。
4.1.4 与 Web 框架集成:pytest-django、pytest-flask 等
对于 Web 项目,pytest 有专门的插件与主流框架深度集成:
- pytest-django:为 Django 提供 fixture(如 db、client)、命令行选项(如 –reuse-db)和数据库隔离支持。
- pytest-flask:提供 client、app 等内置 fixture,方便进行 HTTP 请求测试。
- pytest-fastapi:结合 Starlette 的测试客户端,对 FastAPI 路由和中间件进行端到端测试。
安装方式也很简单,例如:
pip install pytest-django
配置示例(pytest.ini):
[pytest] DJANGO_SETTINGS_MODULE = myproject.settings 然后在测试中即可使用 Django 的测试数据库:
def test_homepage(client):
response = client.get("/")
assert response.status_code == 200
4.2 与 CI/CD 工具集成
pytest 与持续集成工具(CI/CD)天然兼容,支持标准输出、退出码和测试报告格式,使其易于与各类流水线对接。
4.2.1 GitHub Actions
GitHub Actions 是一种流行的 CI/CD 工具,可以通过 YAML 配置文件轻松集成 pytest 测试流程:
# .github/workflows/test.yml
name: Run Tests
on: [push, pull_request]
jobs:
test:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Set up Python
uses: actions/setup-python@v4
with:
python-version: '3.11'
- run: pip install -r requirements.txt
- run: pytest --cov=my_project --cov-report=xml
也可结合 codecov 插件上传测试覆盖率报告到云端展示。
4.2.2 GitLab CI
在 GitLab 中,使用 .gitlab-ci.yml 文件配置测试流程:
test:
image: python:3.11
script:
- pip install -r requirements.txt
- pytest --junitxml=report.xml
artifacts:
paths:
- report.xml
配合 GitLab 的测试报告视图,可以直观展示测试结果和失败原因。
4.2.3 Jenkins、CircleCI、Travis CI 等
这些工具也都支持运行 pytest 测试脚本,只需配置对应的构建步骤即可。同时,pytest 的插件生态与这些平台兼容性好,支持输出 XML、HTML 等报告格式,便于集成持续部署、邮件通知等功能。
pytest 的强大不仅来自本身的灵活性和易用性,更在于其生态系统的完善。有助于扩展功能(如 mock、并行、覆盖率等),可与各种 Web 框架无缝集成;易于对接主流 CI/CD 工具链,助力自动化测试。得益于这些特性,pytest 能满足从简单脚本测试到大型项目持续交付的一整套需求,是构建现代 Python 测试体系的核心工具。
5. Pytest 最佳实践总结
随着项目规模和复杂度的增加,良好的测试习惯不仅能提升开发效率,还能显著提高代码质量。以下是使用 pytest 过程中积累的一些实用经验和最佳实践建议。
5.1 测试代码要易读、结构清晰
- 将测试文件和源代码分别组织在 tests/ 和 src/(或 my_project/)目录下;
- 每个模块应有对应的测试文件,测试函数的命名应具有描述性;
- 使用一致的命名风格,如:test_functionName_condition_expectedResult();
- 对复杂测试场景,适当拆分多个小测试函数,而非写一个超长的测试用例。
示例结构:
project_root/
├── src/
│ └── calculator.py
├── tests/
│ └── test_calculator.py
├── pytest.ini
└── requirements.txt
5.2 充分利用 fixtures 管理上下文和资源
- 避免在每个测试中重复初始化数据;
- 利用 fixture 的作用域(function、module、class、session)优化资源复用;
- 多个 fixture 之间可以组合使用;
- 使用 yield 语法处理前置设置和清理逻辑;
- 将常用 fixture 抽取到 conftest.py 中,供所有测试共享。
示例(conftest.py):
import pytest
@pytest.fixture(scope="module")
def temp_file(tmp_path_factory):
file = tmp_path_factory.mktemp("data") / "test.txt"
file.write_text("example")
return file
5.3 用参数化减少重复测试代码
- @pytest.mark.parametrize 能显著减少样板代码;
- 如果数据量大、来源复杂,可以结合生成器或外部数据源(如 CSV、JSON);
- 测试函数的参数顺序和数据格式需保持一致,避免位置混乱;
- 参数组合时可以使用笛卡尔积或 pytest_cases 插件进一步优化。
5.4 灵活使用标记(markers)组织测试
使用 @pytest.mark 可以对测试用例分组、打标签、控制运行策略:
- @pytest.mark.slow:标记为慢测试;
- @pytest.mark.api:标记为 API 测试;
- @pytest.mark.skipif(…):基于条件跳过测试;
- @pytest.mark.xfail:标记预期失败的用例(用于待修复 Bug);
并通过命令行选择运行特定标记:
可以在 pytest.ini 中注册自定义标记:
[pytest] markers = slow: marks tests as slow api: marks API-related tests
5.5 编写失败时易于调试的断言
- 避免模糊的布尔断言(如 assert foo),应写清楚期望结果;
- 利用 assert 的详细错误消息功能;
- 对复杂结构(如字典、对象、JSON)断言时尽量分步检查;
- 使用 pytest.raises 明确断言异常及异常类型。
例子:
with pytest.raises(ValueError, match="Invalid input"):
func_that_should_fail("bad input")
5.6 保持测试原子性和无副作用
- 每个测试用例应独立运行,不依赖其他测试的运行结果;
- 测试应可重复运行,避免全局状态污染;
- 对外部依赖(如数据库、网络)应使用 mock 或 fixture 隔离;
- 临时文件、目录应使用 tmp_path、tmpdir 等内置 fixture 管理。
5.7 与覆盖率和静态分析工具配合
pytest --cov=my_project --cov-report=term-missing
- 使用 pytest-cov 生成 HTML 或 XML 报告,配合 CI 展示;
- 搭配 flake8、mypy、pylint 等工具进行代码静态检查。
5.8 集成 CI/CD 流水线自动执行测试
- 在 push、pull request 或 merge 操作时自动触发 pytest;
- 将测试失败作为构建失败条件,确保代码质量;
- 可结合 coverage、pytest-html、junitxml 输出结果报告供平台读取。
5.9 编写测试计划和测试用例文档
虽然 pytest 本身不要求文档化测试,但良好的测试设计仍然重要:
- 为复杂功能设计测试矩阵(输入、输出、边界、异常);
- 维护每个模块的测试用例说明,便于团队协作;
- 对关键路径(核心算法、接口调用)优先覆盖。
5.10 善用社区资源和插件
6. 总结
pytest 是一个功能强大、使用方便的 Python 测试框架。它不仅适合初学者快速入门,也能满足专业团队在大型项目中的复杂测试需求。借助其清晰的语法、丰富的扩展能力和良好的工具支持,pytest 成为现代 Python 开发中不可或缺的一环。如果你还在使用冗长的 unittest 写测试,不妨尝试一下 pytest,它可能会改变你对测试的看法。
7. 参考资料
- 官方文档:https://docs.pytest.org/en/stable/index.html
- GitHub链接:https://github.com/pytest-dev/pytest