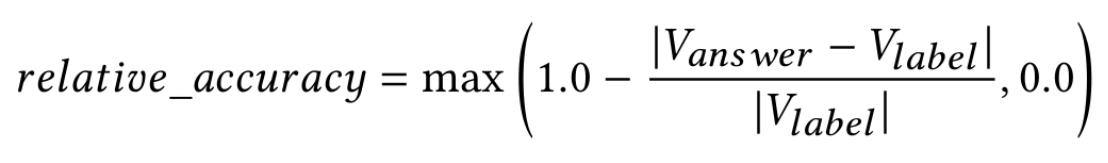Hardy 与 Littlewood 的合作堪称数学史上合作关系的典范。在他们合作的极盛时期,欧洲数学界流传着许多有关他们的善意玩笑。 比如 Bohr 曾经开玩笑说当时英国共有三位第一流的数学家:一位是 Hardy,一位是 Littlewood,还有一位是 Hardy-Littlewood。而与之截然相反的另一个玩笑则宣称 Littlewood 根本就不存在,是 Hardy 为了自己的文章一旦出现错误时可以有替罪羊而杜撰出来的虚拟人物。 据说 Landau 还专程从德国跑到英国来证实Littlewood 的存在性。
素数(如2, 3, 5, 7, 11, 13…)是只能被1和它本身整除的正整数,被称为“算术的原子”。
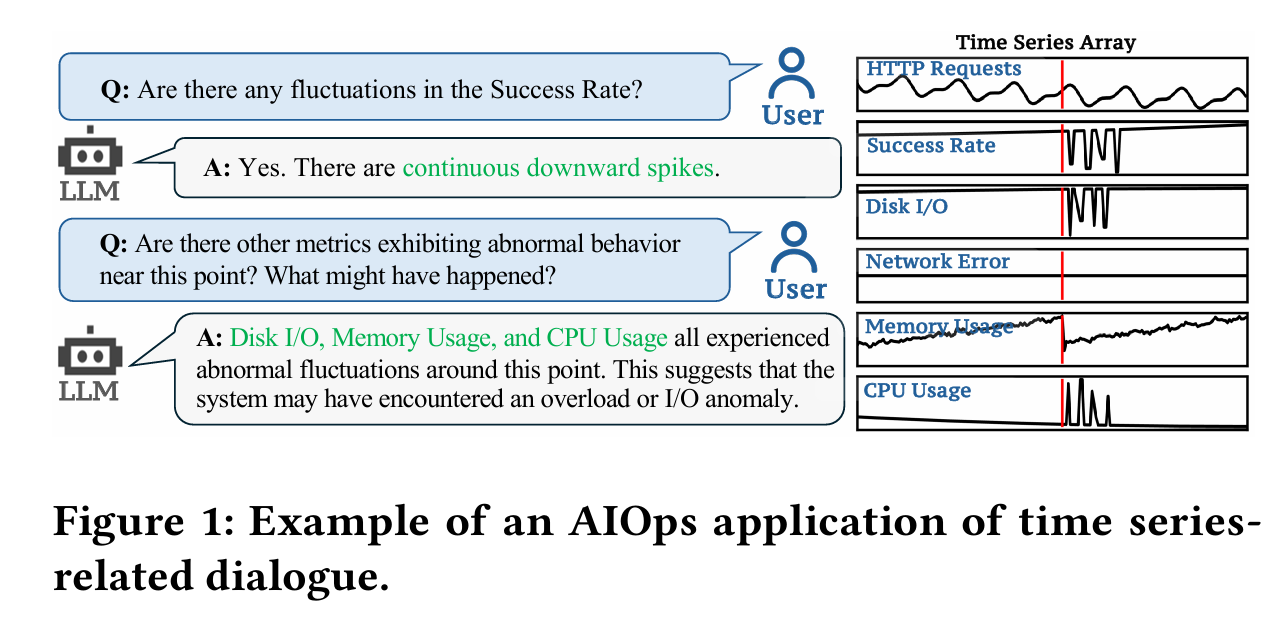
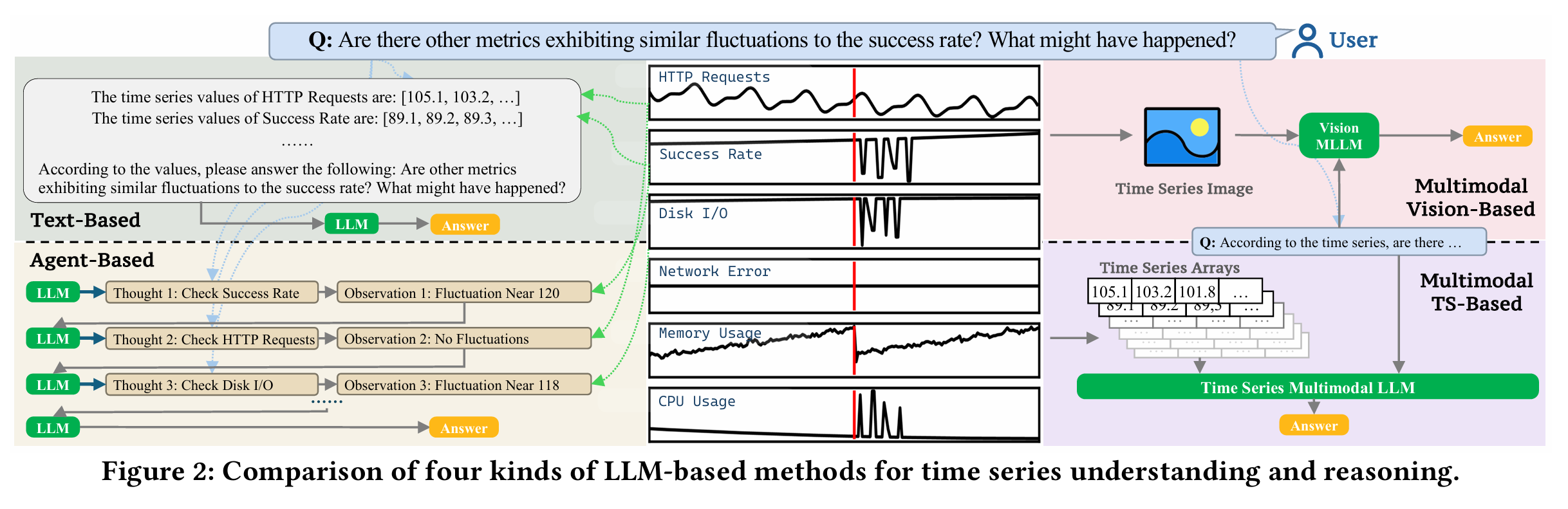
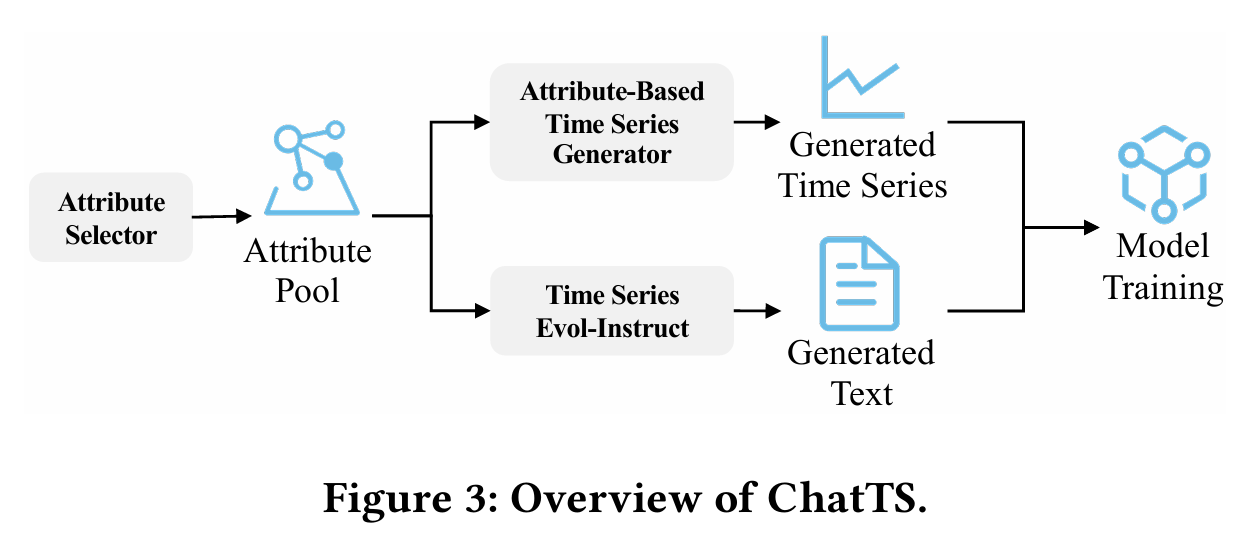
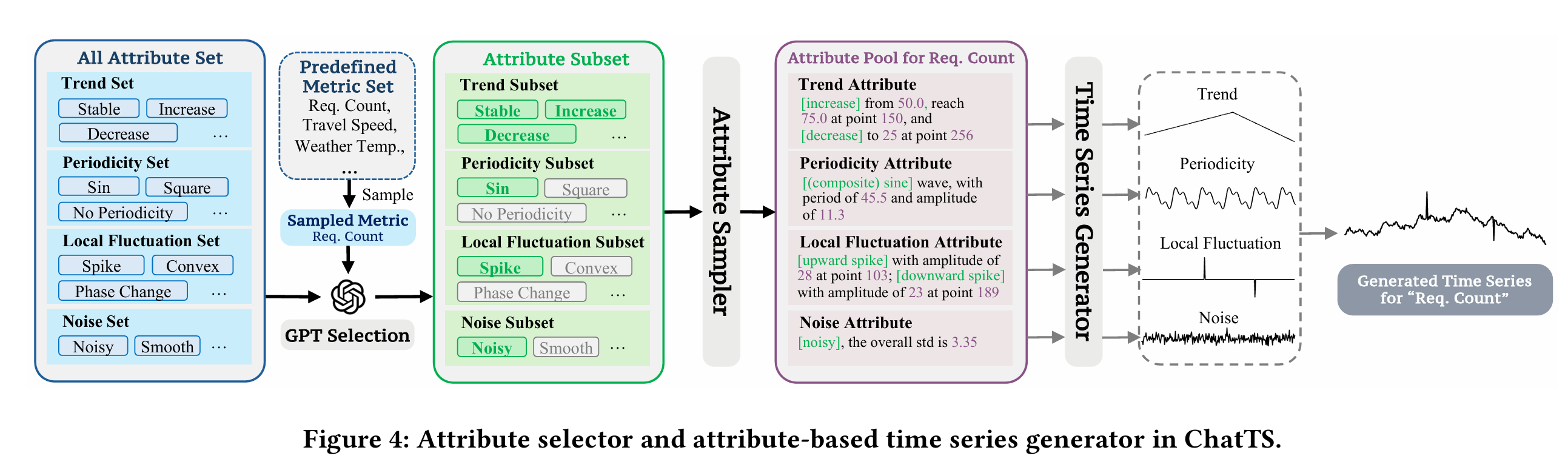
数学家长期试图理解:素数在数轴上是如何分布的?表面看,它们很随机,但又不是完全无序。素数,是算术的原子,也是数学的诗篇。书的开篇如游戏开场,“谁想成为百万富翁?”用一个富有现代气息的问题,把读者从功利的世界轻轻拉入一个古老、神秘的国度。素数之谜的诱人魅力不言自明,那些散布在数轴上的孤独整数,如恒星般璀璨,却从不规律地排列,仿佛宇宙中跳动的节奏,等待人类去探寻其中的和谐与隐秘的旋律。
黎曼猜想(Riemann Hypothesis)是数论中最著名、最深邃也最神秘的未解难题之一。它由德国数学家伯恩哈德·黎曼(Bernhard Riemann)于1859年提出,至今悬而未决,被称为“数学皇冠上的明珠”。其本质是关于素数分布的一个深层猜想。它指出:所有非平凡零点的实部都等于 1/2。我们分开来解释。
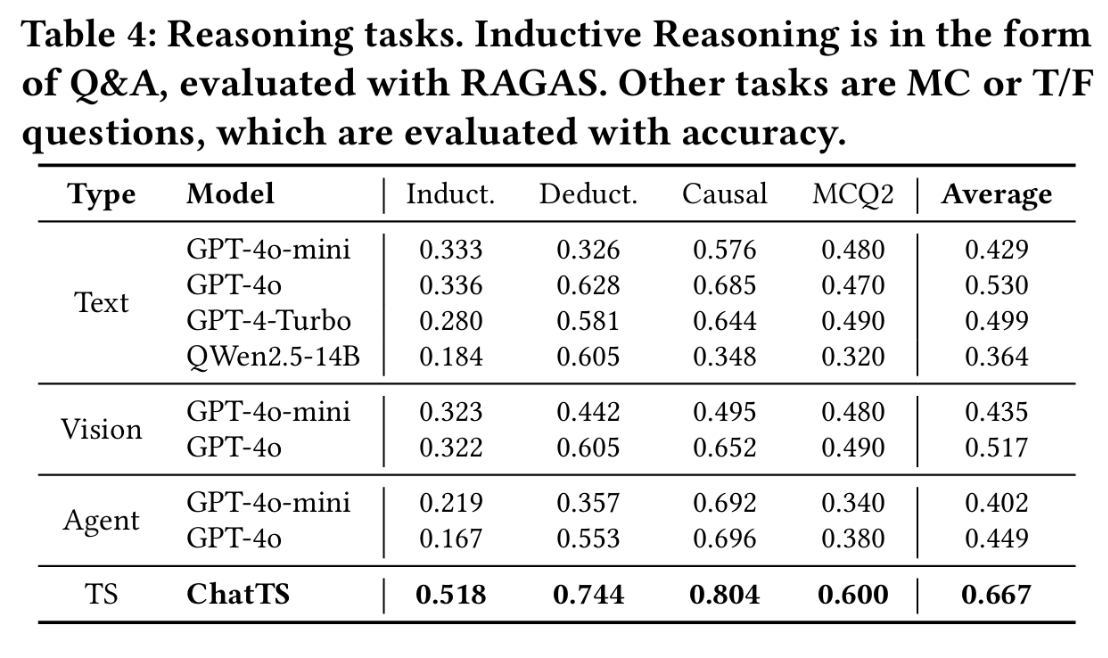
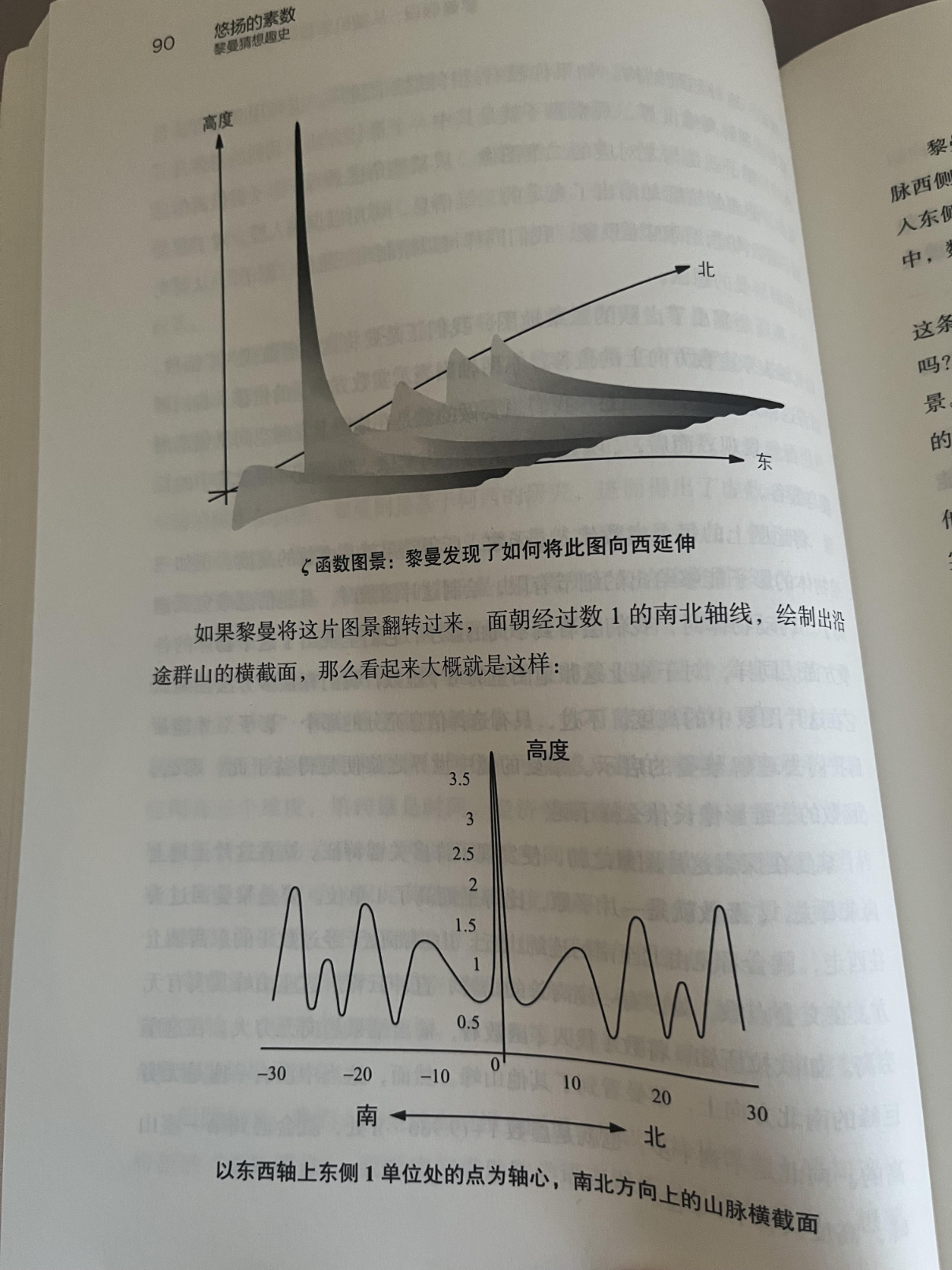
欧拉在18世纪发现了一个惊人的联系:正整数的幂次求和可以与素数的幂次乘积通过一个公式联系到一起,它把素数和函数论连接了起来。黎曼进一步研究这个函数,并将其延拓到复数域(复变函数),得到了一个具有非凡意义的观察:ζ 函数的“零点”,与素数的分布密切相关。
黎曼注意到 ζ(s) 在复数域中有无穷多个零点。去掉那些“平凡零点”后(即 s = -2, -4, -6, …),剩下的“非平凡零点”出现在所谓的“临界带”:黎曼猜想断言:所有非平凡零点的实部都是 1/2。也就是说,这些零点全都位于复平面上的“临界线”:Re(s)= \frac{1}{2}。
在《悠扬的素数》中,黎曼的身影几乎是全书的主线。他用虚数作为观察镜,发现素数在混乱中隐藏的节奏,仿佛宇宙的心跳。而后继者如:
希尔伯特曾说:“如果我死后能复生,第一件事就是问黎曼猜想是否已经被证明。”
阿塔拉·塞尔贝格、哈代与李特尔伍德、埃尔德什等名家也都为其贡献一砖一瓦。
蒙哥马利与戴森发现其零点分布与量子混沌系统相似,拉近数学与物理的边界。

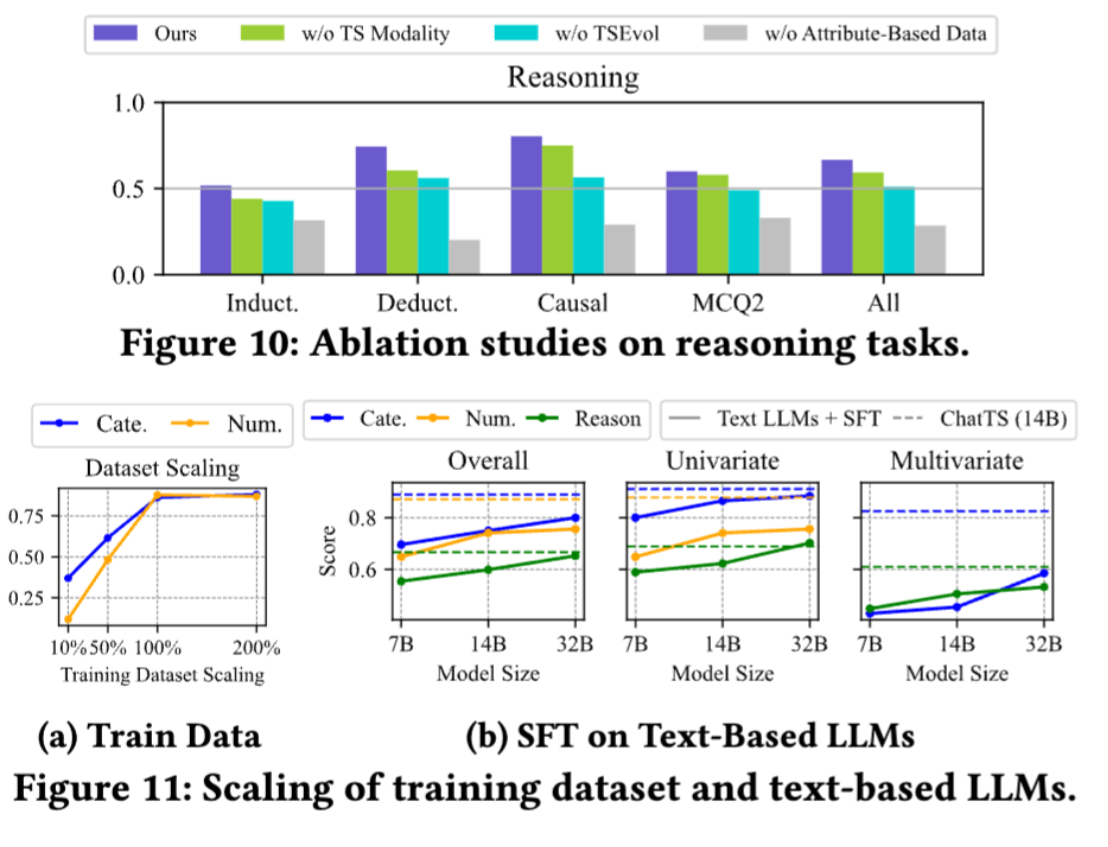
在这个以快节奏和实用主义主导的时代,《悠扬的素数:只有勇者,才能够攀登数学的珠峰》如一股清泉,静静流淌,却激起无数涟漪。这本书,不仅是一部素数的朝圣之旅,更是献给所有热爱思考者的一曲深情咏叹调。20周年纪念增订版,让人重温数学之美,也见证人类在这座知识珠峰上的攀登轨迹。

作者用娓娓道来的笔触,将数学史上一道道闪光的名字编织成一幅宏伟的智者群像画。欧几里得的冷峻、欧拉的优雅、高斯的洞察、黎曼的深邃……他们不仅是定理的缔造者,更是精神世界的开拓者。尤其是黎曼,那位用虚数搭建观察镜、窥见另一个宇宙秩序的神秘数学家,他提出的黎曼假设,是本书贯穿始终的隐线,也是数学王国中最炽热的圣杯。
书中的语言轻盈而不轻薄,深刻而不晦涩。作者时而引用古典诗意:“ζ函数:音乐与数学的对白”,时而嵌入科技话题:“未来是光明的,未来是椭圆的”。每一章都有其节奏与情绪的变化,就像一场探险:从远古的演算石板,到量子鼓面上跳动的零点,从哥德尔的不完全性,到RSA的公钥密码,从虚数空间的镜中花,到大数据背景下寻找大素数的工程,这本书既是一部思想史,也是一部数学的交响诗。

在《悠扬的素数》中,黎曼 ζ 函数的零点被比作一场音乐会的“音符”,每一个零点都有其节奏。黎曼猜想就像乐谱中的和声要求——若它成立,那整个数学宇宙就会像一首完美的交响曲,充满秩序与美感;若它不成立,整个宇宙的“调性”都将改变。黎曼猜想,不仅是关于函数的技术问题,更是一面镜子,映出人类追寻秩序与美的勇气。它是数学中的“珠穆朗玛峰”,吸引着一代又一代的攀登者。无论我们是否登顶,它始终在那,用它神秘的姿态提醒我们:最伟大的问题,往往不仅关乎答案,更关乎追问本身。
在《悠扬的素数》中,作者将 Hardy 描述为“数学唯美主义者”,他追求的是无用之美。他曾以一种近乎狂热的信仰写道:“我从未做过一件对人类实用的事,这是我作为纯数学家的荣耀。”而 Littlewood,是比他年轻六岁的搭档。他不像 Hardy 那样“高冷”,更多一份幽默和实用精神。他们从1911年开始合作,持续了将近四十年,在素数、级数、ζ函数等领域合著了超过100篇论文。他们的合作之深,不仅体现在成果上,更体现在他们之间那四条著名的“数学合作守则”上:
- 写给彼此的内容,对错并不重要;
- 没有义务回信,甚至没有义务阅读对方的信件;
- 尽可能不要思考同样的问题;
- 每篇合著文章都视为共同作品,哪怕一方完全没参与。
这些幽默的条款,其实是对学术合作本质的深刻理解:信任、高度自治、责任共享与彼此照顾。在《悠扬的素数》的结构中,这正是数学精神的一部分:人类不是孤独地攀登这座珠峰,而是手牵手、肩并肩地在冰雪间前行。

书中没有详细展开 Hardy 和 Littlewood 的逸事,但他们的故事流传至今,仍如琴弦上的颤音,余音绕梁。最著名的,当然是 Hardy 去医院探望拉马努金时说的那个“出租车笑话”:
Hardy 说:“我坐的出租车号是 1729,好无趣的数字。”拉马努金马上答道:“不,那是一个非常有趣的数字!它是最小的可以用两种不同方式写成两个立方数之和的数:1729 = 1³ + 12³ = 9³ + 10³。”Littlewood 听说这个故事后笑着说:“这是个典型的 Hardy 式数学笑话:优雅、抽象、毫不实用。”
在数学的历史上,没有几对搭档像 Hardy 和 Littlewood 一样,留下如此深远的痕迹。他们没有破解黎曼假设,但他们拓展了通向它的路径。他们用分析的方法处理素数的分布,让原本“跳跃无序”的整数显出隐藏的节奏和韵律。
《悠扬的素数》不是纯粹讲数学理论的书,它讲的是人——执着的数学家、孤独的天才、沉默的计算者、突破常规的梦想家。而 Hardy 和 Littlewood,就像一对用数学谱曲的演奏家,在这部“素数交响曲”中演奏了最默契的一段二重奏。

尤为动人的是后记中,作者讲述张益唐与梅纳德关于素数间距的故事。这不仅是现代数学突破的真实记录,更是“孤独攀登者”精神的致敬。张益唐在清贫中坚持研究,梅纳德在工作中发现灵感,他们仿佛是黎曼在21世纪的回声:即使没有荣耀加身,即使无人喝彩,只要仍在为素数的秩序而燃烧,他们就是数学真正的英雄。《悠扬的素数》不只是一本数学书,它更像是一封写给智性之美的情书。读它的人,不必是数学家,但一定是爱思想、爱真理、爱自由的人。这本书教我们:在数字的荒原之中,依然可以听见诗歌,在冷峻的定理背后,也藏着人类最温热的梦想。