
本文作为智能运维系统的探索,这篇论文的标题是《Focus: Shedding Light on the High Search Response Time in the Wild》,来自于清华大学裴丹教授。目标是解决在运维过程中,发现高搜索响应时间之后,使用机器学习算法发现异常的原因和规则。该系统(Focus)使用过2.5个月的数据,并且分析过数十亿的日志。下面将会详细介绍这篇文章的主要内容。
问题描述:
To help search operators dubug HSRT (high search response time),Focus is a search log analysis framework to answer the three questions:
(1) What is the HSRT condition?
(2) Which HSRT condition types are prevalent across days?
(3) How does each attribute affect SRT in those prevalent HSRT condition types?
解决方案:
Focus has one component for each of the above questions:
(1) A decision tree based classifier to identify HSRT conditions in search logs of each day;
(2) A clustering based condition type miner to combine similar HSRT conditions into one type, and find the prevalent condition types across days; following Occam’s razor principle.
(3) An attribute effect estimator to analyze the effect of each individual attribute of SRT within a prevalent condition type.
基础知识准备:
(A) Search Logs:
For each measured query, its search log records two types of data: SRT and SRT components, Query Attributes.
(1) SRT and SRT components:(特征层)

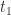
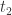
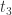

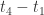




(2) Query Attributes:(特征层)
The search logs record the following attributes for each measured query:
(i) Browser Engine: Webkit(e.g. Chrome, Safari and 360 Secure Browser), Gecko, Trident LEGC, Trident 4.0, Trident 5.0, and others.
(ii) ISP: China Telecom, China Unicom, China Mobile, China Netcom, CHina Tietong, others.
(iii) Localtion: Based on the client IP, convert IP to its geographic location. In total, there are 32 provinces.
(iv) #Image: the number of embedded images in the result page.
(v) Ads: A result page contains paid advertise links or not.
(vi) Loading Mode: The loading mode of a result page can be either synchronous or asynchronous.
(vii) Background page views: On the service side, the search engine S also post-analyzes the logs and generates the background page views. The background PVs (page views) for a query q is measured by the number of queries served within 30 seconds before and after q is served.It reflects the average search request load where q is served. Due to confidentiality constraints, we normalize specific background PVs (page Views) by the maximum value.(事后分析,统计出一些必要的特征,输入 Focus 系统的机器学习模型中)
(B) HSRT and HSRT Conditions:(样本层)
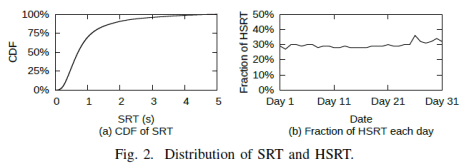
Usually, we can use cumulative distribution fraction (CDF) of SRT in the search logs to determine the high search response time condition (HSRT condition). In this paper, we define HSRT as the SRT longer than 1s.
Challenges of Identifying HSRT Conditions: In order to identify HSRT conditions in multi-dimensional search logs.(以下是这个系统的一些难点和挑战点)
(a) Naive Single Dimensional Based Methods: including pair-wise correlation analysis and so on, but is inefficient.
(b) Attributes can be potentially interdependent on each other: that means Naive Bayes Method may not applicable in this situation.
(c) Need to avoid output overlapping conditions: like {#image>30}, {ads=yes}, and {#image>20, ads=yes}. (随着时间的推移,每天使用模型可能会推出类似或者重复的规则)。
关键思想和系统概况
Condition is a combination of attributes and specific values in search logs.
HSRT Condition is a condition that covers at least 1%$ of total queries, and has the fraction of HSRT large than the global level:
(# of HSRT queries in a HSRT condition / #of queries in a HSRT condition) > (# of HSRT queries / # of queries). This is in order to assign to labels and we can change this definition in practice. (这只是用来打标签的定义,用于判断什么是HSRT,在实际的应用中,我们可以根据具体的场景采用不同的定义,例如返回码等指标)。
‘Focus’ System Overview:
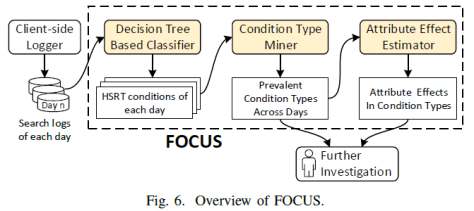
Input: search logs(日志)
(i) Use a decision tree based classifier to identify HSRT conditions in search logs every day; (每天可以使用决策树模型从日志中提取HSRT条件)。
(ii) Use a clustering based condition type miner to identify condition types of similar HSRT conditions, and fine prevalent condition types across days; (用于把类似的条件融合在一起)。
(iii) Use an attribute effect estimator to analyze how an attribute affects SRT and SRT components in each prevalent condition type. (用于判断哪些属性或者特征对这个标签影响更加深远)。
Output: prevalent condition types and their attributes effects on SRT.(第二步输出的条件以及第三步属性的重要性)。
Part (i): Decision Tree Based Classifier including ID3, C4.5, CART. It contains five important parts: (1) expressing attribute splits; (2) evaluate splits; (3) stopping tree growing; (4) assigning Labels: assign HSRT labels to the left nodes whose fraction of HSRT is larger than the global fraction of HSRT; (5) identify HSRT Branching Attribute Conditions. (这里是 Focus 系统所采用的机器学习算法)。
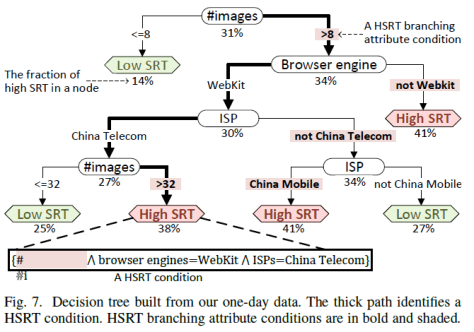
Part (ii): Condition Type Miner: group HSRT conditions according to (1) the same combination of attributes, (2) the same value from each category attribute, and (3) similar interval for each numeric attribute, using Jaccard Index to measure the similarity between intervals. (条件的融合)。
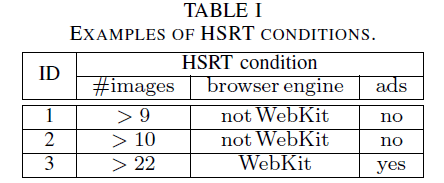
Part (iii): Attribute Effect Estimator: With each condition type
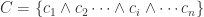
we design a method to understand how each attribute condition 
For example, what is the HSRT fraction caused by 
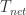
Main Idea: flip condition 
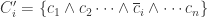

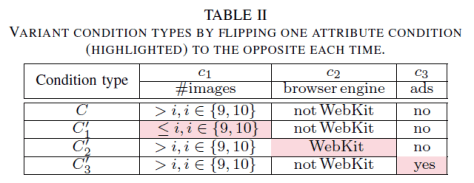
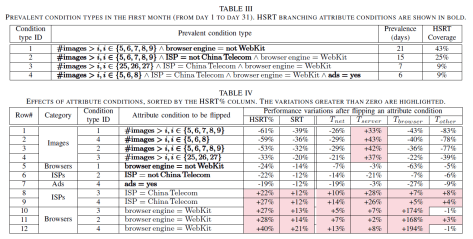
In Table IV, the results are sorted by the variation of the fraction of HSRT in condition types (HSRT% column) caused by flipping an attribute condition.
(i) We highlight the variations greater than zero (getting worse after flipping an attribute condition).
(ii) We focus on that flipping the HSRT branching attribute conditions can yield improvements on HSRT%. For example, the condition #image>x are all ranked at the top. It means we need to reduce the impact of images on SRT and we can get the highest potential improvement of HSRT.
(iii) Table III and Table IV are the output of Focus to the operators for these months.
Observations by Further Inverstigation
Table IV raises some interesting questions:(通过 Focus 输出的表格 Table IV 可以提出很多其余的问题,也许是人工经验不容易发现的问题)
(1) Why does reducing #images increase
(2) How do ads inflate SRT? Why do the pages with ads need more 
(3) Why does Webkit engine perform better, especially greatly decreasing 
(4) It is nature that switching ISPs can affect network transmission time
