卡特赖特是首位获得多项荣誉的女性数学家:1947年当选为英国皇家学会会士(FRS),是该学会首位女性数学家会员。1949年出任剑桥大学格顿学院院长(该院史上第二位女院长),同时保持活跃研究,1950年代在簇集理论领域取得新突破。1951年担任数学协会(Mathematical Association)主席。 1961–1962年担任伦敦数学学会(London Mathematical Society)主席。1964年获得西尔维斯特奖章(Sylvester Medal)。 1968年成为首位获得德摩根奖章(De Morgan Medal)的女性。 1969年被英国女王授予“大英帝国女爵士”(Dame Commander of the Order of the British Empire)称号。
Lars Valerian Ahlfors(1907年4月18日-1996年10月11日)是芬兰著名数学家,以在黎曼曲面和复分析领域的开创性工作闻名于世。他出生于芬兰赫尔辛基,母亲因难产去世,父亲是赫尔辛基理工大学的工程学教授。作为瑞典语家庭的后代,Ahlfors早年就读于瑞典语私立学校,1924年进入赫尔辛基大学,师从Ernst Lindelöf和Rolf Nevanlinna,1928年毕业。
二战期间,Ahlfors曾短暂任教于瑞士苏黎世联邦理工学院(1944-1945),后于1946年重返美国哈佛大学任教直至1977年退休,期间担任William Caspar Graustein数学教授。他还在1962年和1966年两度访问普林斯顿高等研究院。除菲尔兹奖外,Ahlfors还获得1981年沃尔夫数学奖、1982年美国数学会Leroy P. Steele奖等重要荣誉,并担任1986年国际数学家大会名誉主席。
Ahlfors的几何定义:Ahlfors抛弃了对光滑性的要求,转而通过 四边形的模(Modulus of Quadrilaterals)来定义拟共形映射。一个同胚 是 -拟共形的,如果对任意四边形 ,有:
这种定义不依赖于微分结构,适用于更广泛的映射类。
2. Ahlfors在拟共形映射中的主要贡献
Ahlfors在拟共形映射领域的贡献主要体现在以下几个方面:
(1) 重新定义拟共形映射(1954)
在论文 On Quasiconformal Mappings(1954)中,Ahlfors提出了拟共形映射的几何定义,去除了传统定义中对光滑性的要求。这一突破使得拟共形映射的理论更加普适,并能够应用于更广泛的数学问题。为Teichmüller空间的理论奠定了坚实的基础,使得拟共形映射成为研究非光滑几何结构(如分形、Kleinian群的极限集)的有力工具。
在 The Boundary Correspondence under Quasiconformal Mappings(1956,与Beurling合作)中,Ahlfors研究了拟共形映射的边界行为:证明了拟共形映射在Jordan域上的边界对应是拟对称(Quasisymmetric)的。构造了奇异边界对应的例子,即存在拟共形映射,其边界对应完全不绝对连续(与共形映射的F. & M. Riesz定理形成对比)。为后续研究Kleinian群的极限集(如Ahlfors测度零猜想)提供了工具,在双曲几何(如Mostow刚性定理)中有重要应用。
在克莱因群的研究中,Ahlfors摒弃了传统的三维拓扑方法,转而采用复解析工具。他于1964年提出的“有限性定理”指出,有限生成的克莱因群在普通集(ordinary set)上的商空间是一个有限型的轨道曲面(orbifold),这一结果揭示了克莱因群作用的几何结构,为后来的瑟斯顿(Thurston)三维流形理论提供了关键启示。他通过推广伯斯(Bers)的艾希勒上同调(Eichler Cohomology)方法,构造了光滑势函数以处理非光滑边界问题,并引入“软化子”(mollifier)技术克服了极限集(limit set)分析的困难。尽管他提出的“极限集测度零猜想”(Ahlfors Measure Zero Conjecture)未被完全证明,但推动了沙利文(Sullivan)等人在遍历理论和双曲动力系统上的突破性工作。阿尔福斯与伯斯的合作还催生了“面积不等式”(Bers-Ahlfors Area Theorems),量化了克莱因群的几何有限性,并启发了后续对拟共形映射边界对应问题的研究。
当初在国外读博时,我的代数教授对范畴论(category theory)情有独钟,甚至亲自写了两本书,一本是关于环论的,另一本则深入探讨范畴论。每当代数考试临近时,他总爱出一些涉及群论、环论、模论和范畴论的题目,而域论和伽罗华理论却鲜有涉及。虽然教授的书籍颇具深度,但其中的内容往往艰涩难懂,且并不完全契合我的学习口味。于是,无奈之下,我只好前往图书馆翻阅其他参考书,经过一番查找,我偶然发现了 Serge Lang 的《代数学》。然而,翻阅之后,我意识到这本书虽然丰富,但并不完全符合教授考试的风格,最终它只能作为额外的学习补充材料。
终于,在图书馆翻阅了一番后,我找到了这本书——《Algebra: Chapter 0》。这本书不仅涉及范畴论,但却没有那么晦涩难懂,且充满了丰富的例子,极大地激发了我的兴趣。它由Paolo Aluffi编写,是一本研究生水平的代数教材,属于美国数学学会(AMS)《Graduate Studies in Mathematics》系列的第104卷。全书分为九章,内容从集合论和范畴论的基础知识开始,逐步深入群论、环与模、线性代数、域论以及同调代数等核心领域。
皮埃尔·约瑟夫·路易·法图(Pierre Joseph Louis Fatou,1878年2月28日-1929年8月9日)是20世纪初法国著名的数学家和天文学家。他在分析数学的多个分支中作出了重要贡献,尤其在复变函数、动力系统和测度论领域影响深远。法图引理(Fatou’s lemma)、法图定理(Fatou’s theorem)、法图集(Fatou set)以及法图-比伯巴赫域(Fatou–Bieberbach domain)均以他的名字命名,彰显了其学术成就的广泛影响。
迈克尔·阿蒂亚爵士,OM,FRS(Sir Michael Francis Atiyah)1929年4月22日生,英国数学家,被誉为当今最伟大的数学家之一。主要研究领域为几何。1960年代他与伊萨多·辛格合作,证明了阿蒂亚-辛格指标定理。此定理在数学的一些领域均有重要作用。他于1966年荣获菲尔兹奖,与辛格在2004年共同获得阿贝尔奖。
Gaston Maurice Julia(1893年2月3日-1978年3月19日)出生于法属阿尔及利亚的Sidi Bel Abbes。他自幼展现出对数学和音乐的浓厚兴趣,后进入巴黎高等师范学院(École Normale Supérieure)和巴黎大学深造。第一次世界大战期间,21岁的Julia应征入伍,并在战斗中遭受重伤,失去了鼻子,此后终生佩戴皮革面罩遮盖伤处。战后他重返学术生涯,成为法国数学界的核心人物,晚年于巴黎逝世。
数学贡献
Julia集与分形理论
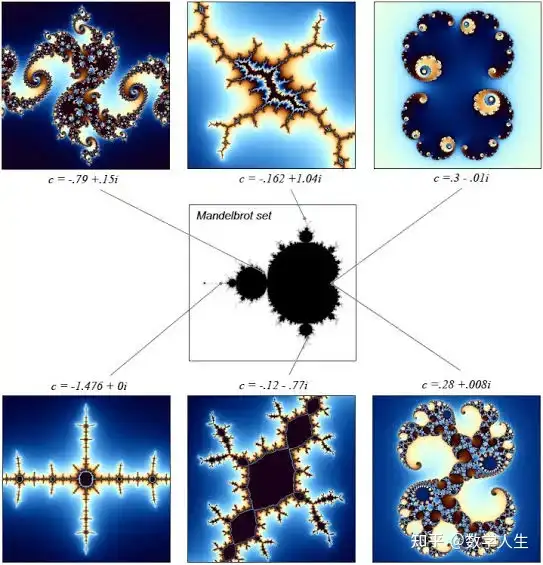
Julia最著名的贡献是提出了Julia集的概念。1918年,25岁的 Julia 发表了199页的里程碑论文《有理函数迭代备忘录》(Mémoire sur l’itération des fonctions rationnelles),系统研究了复平面上有理函数的迭代行为,奠定了全纯动力系统理论的基础。这一成果为他赢得了法国科学院大奖(Grand Prix des Sciences Mathématiques)。 尽管他的工作一度被遗忘,直到20世纪70年代,Benoit Mandelbrot在研究分形时重新发掘并推广了Julia的理论,使Julia集与Mandelbrot集成为分形几何的核心内容。
学术影响与遗产
Gaston Julia 与 Pierre Fatou 共同开创了复动力系统的现代理论。他的研究涉及复分析、几何学、量子理论数学基础等领域,出版30部著作,如《Eléments de géométrie infinitésimale》(1927)和《Cours de Cinématique》(1928),他还培养了Claude Chevalley等著名数学家。《Oeuvres》(6卷,1968–1970)收录其全部研究成果,《Traité de Théorie de Fonctions》(1953)是函数论经典教材。
詹姆斯·亚历山大·梅纳德(James Alexander Maynard)于1987年6月11日出生于英国埃塞克斯郡的切尔姆斯福德。他在剑桥大学皇后学院获得数学学士和硕士学位(2005–2009),随后进入牛津大学贝利奥尔学院攻读博士学位,师从著名数论学家罗杰·希斯-布朗(Roger Heath-Brown),并于2013年完成博士论文《解析数论专题》。
素数间距问题一直是数论研究的核心课题之一,特别是关于素数间最大间距的研究吸引了众多数学家的关注。本文整合了Ford、Green、Konyagin、Maynard和Tao等人在”Large Gaps between primes”和”Long gaps between primes”两篇重要论文中的工作,系统介绍素数大间距问题的发展历史和整体研究思路。
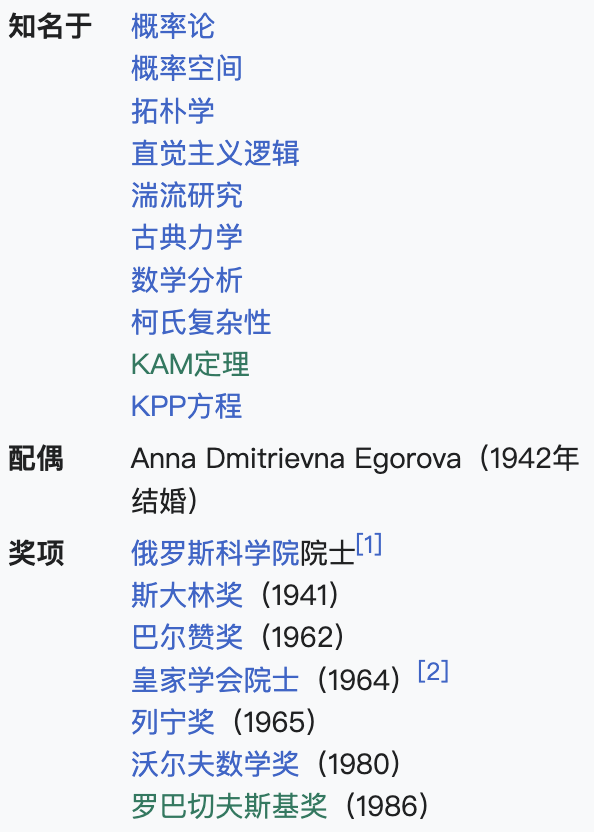
柯尔莫哥洛夫最著名的贡献是1933年出版的《概率论基础》(Grundbegriffe der Wahrscheinlichkeitsrechnung),其中提出了概率论的公理化体系,彻底解决了希尔伯特第六问题中“物理学的公理化”部分。他还创立了KAM理论(与Arnold和Moser合作)、柯尔莫哥洛夫复杂性理论,并在湍流理论、拓扑学、信息论等领域作出开创性工作。尽管在斯大林时期面临政治压力,他仍获得斯大林奖(1941年)和列宁勋章等荣誉。
P. S. Aleksandrov(帕维尔·亚历山德罗夫)亚历山德罗夫称柯尔莫哥洛夫为“数学王子”,强调其思想的广度和深度在同时代数学家中无与伦比。他指出柯尔莫哥洛夫的研究覆盖了从概率论到拓扑学等二十多个数学领域,且在每个领域都带来了根本性的革新(《The Life and Work of Kolmogorov》)。在柯尔莫哥洛夫50岁生日时,亚历山德罗夫还提到:“他的任何一篇论文都能引发对整个领域的重新评估。”
A. Ya. Khinchin(亚历山大·辛钦)辛钦认为柯尔莫哥洛夫具有罕见的才能,能将高度抽象的数学与实际问题结合。他特别指出:“柯尔莫哥洛夫最引人注目的特质是其思想的丰富性——他关于任何工作的每一句话都可能成为一篇博士论文的基础。”(《The Life and Work of Kolmogorov》)。
I. M. Gelfand(伊斯雷尔·盖尔范德)盖尔范德评价道:“数学被视为一门统一学科,很大程度上归功于柯尔莫哥洛夫。”他强调了柯尔莫哥洛夫在整合数学不同分支中的核心作用(《The Life and Work of Kolmogorov》)。
V. I. Arnold(弗拉基米尔·阿诺尔德) 阿诺尔德将柯尔莫哥洛夫与庞加莱、高斯、欧拉和牛顿并列,称“仅需五代人(柯尔莫哥洛夫-庞加莱-高斯-欧拉-牛顿)就能将我们与科学的源头连接起来”。他还提到柯尔莫哥洛夫对莫斯科大学数学系的深远影响,称其与佩特罗夫斯基共同塑造了该系的黄金时代(《A few words on Andrei Nikolaevich Kolmogorov》)。
N. H. Bingham 指出,柯尔莫哥洛夫1933年的《概率论基础》为概率论的公理化奠定了基础,解决了希尔伯特第六问题中关于概率论公理化的部分,甚至影响了保罗·莱维等学者(《Andrey Kolmogorov – MacTutor History of Mathematics》)。
Benoit Mandelbrot 在湍流研究中引用柯尔莫哥洛夫1941年的理论,认为其开创性地解释了能量级联现象,尽管后续发现需通过分形理论修正“间歇性”问题(《Fractals: A Very Short Introduction》)。
柯尔莫哥洛夫被广泛视为20世纪最具原创性和影响力的数学家之一,其工作不仅重塑了多个数学领域,还通过教育和跨学科研究留下了持久遗产。笔者貌似找到一个 Andrei Kolmogorov 不研究的领域,那就是数论(Number Theory)。
在学术职位上,斯梅尔曾先后任教于哥伦比亚大学(1960–1964)、加州大学伯克利分校(1964–1995)和香港城市大学(1995–2002),并在伯克利分校退休后成为荣誉教授。在2003至2012年期间,斯梅尔担任丰田工业大学芝加哥分校的教授;此外自2009年8月1日起,他开始担任香港城市大学的特聘教授。斯梅尔的研究兴趣广泛,晚年还涉足计算理论和数理经济学。他研究了“牛顿法”在数值计算中的收敛性问题,并提出了“斯梅尔问题”(Smale’s problems),即“P vs. NP”问题的数值版本。在经济学领域,他与经济学家合作,探讨了一般均衡理论和市场动态的数学结构。他的多学科研究展现了他对数学及其应用的深刻理解。
1971 年 12 月,在伯克利召开的一个动力系统研讨班结束的时候,貌似解决了一个能很好地应用于动力系统的平面上的棘手问题。解决方案宣称:能把 N 个两两位置不同的点逐步移动到另外的 N 个点,使得在移动过程中不发生自交,并且每一步都整体只移动非常小的距离。坐在前排的资深动力系统专家们都乐观地相信这个结果,因为根据之前的经验,在三维以及更高维数的动力系统的应用中,由于这些点能摆成一般位置,这个结论显然是对的,如今该定理在二维的情形也应该成立。
一个坐在教室最后排的长头发、大胡子的研究生站了起来,说证明中的算法是不成立的。他就是 Bill Thurston。他怯怯地走到黑板前面,画了两幅图,每幅图都有 7 个点。然后开始按照刚才的算法来操作。一开始出现的连线尽管很短很少,但毕竟挡住了另外一部分线的延伸方向。想把另外一部分线继续延长又同时避免出现交叉的话,必须从别的地方绕回来,于是各条线开始变得越来越长。在这个复杂的图示例子里,刚才的算法无效!我从未见过其他人有如此强的理解力,也从来没见过有人能如此之快就创造性地构造出反例。这让我从此对几何上可能出现的复杂性产生敬畏。
这幅 2 米高、4 米宽、画着曲线的壁画(见2003年《美国数学会通讯》第50卷第3期的封面)署有作者和日期:“DPS and BT, December, 1971”,它在伯克利的墙上保留了40多年,直到几年前才被擦去。
过去在伯克利 Evans Hall 里由 Thurston 和 Sullivan 一起画的壁画。这个围着三个点绕来绕去的复杂图像实际上是一条简单闭曲线。| 摄影:Ken Ribet
故事三
上面两个故事在伯克利发生的那个星期,其实我只是从麻省理工学院访问伯克利,讲一系列关于微分形式和流形同伦论的课。那时候叶状结构与微分形式到处出现,并且成为研究的热潮,我想利用在我的研究中出现的1-形式来描述基本群的中心下降序列,进而构造叶状结构。这些叶状结构的叶子覆盖了从流形到它的幂零流形的映射图像。幂零流形就是从基本群的高阶幂零子群出发构造的流形。这其实是把利用同调来构造的到高维环面的 Abel 映射推广成幂零的情形。由于缺少 Lie 群的知识,我曾向麻省理工学院和哈佛大学的微分几何学家们请教这个推广的可能性,但我自己还是没弄明白。这些都太模糊、太代数化了。
就在以上两个故事发生期间,我向我的老朋友 Moe Hirsch 提起了 Bill Thurston。Thurston 是 Moe 的博士生,那时候正处于博士阶段的第五年。我记得是 Moe 还是谁说过,Bill 开始念博士时进展很缓慢,甚至在口试时出了点小问题。当时 Bill 被要求举一个万有覆盖的例子,他选择了画亏格为2 的曲面的万有覆盖,在黑板上画出一些笨拙的八边形,八个八边形共用一个顶点。
亏格 2 曲面的万有覆盖。
这种论证很快就在黑板上越来越呈现为没有说服力的混乱。我想 Bill 是第一个在考场上想出如此非平凡的万有覆盖的人。Moe 说,不久之后,Bill 便开始以每个月一个的速度解决博士论文级别的大问题。许多年之后,我听说就在那段时间里, Bill 刚好有了他的第一个孩子 Nathaniel。孩子在晚上不睡觉,所以 Bill 也没法睡觉。在念研究生的时候,有一整年的时间,他晚上都只能与 Nathaniel 在地板上来回地走。
我安排 Bill 先去普林斯顿高等研究院(IAS),然后来麻省理工学院做一场报告,并计划把他招到麻省理工学院。但最后的结果是,Bill 在 1973-1974 年来麻省理工学院访问了一年,但那一年我正好去访问法国高等科学研究院(IHES),并且在法国一待就是 20 年。而 Bill 则被邀请回到普林斯顿大学任职。
故事四
普林斯顿高等研究院,1972-1973
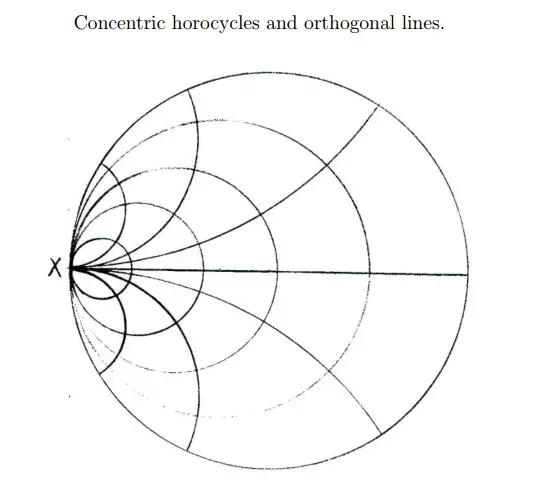
在 1972-1973 这段时间,我从麻省理工学院访问普林斯顿,于是与 Bill 接触的机会更多了。一天,我们从普林斯顿高等研究院出来准备去吃午饭。我问 Bill,什么是极限圆(horocycle)。他说:“你们待在这儿别动。”然后他开始向学院的草地走去。走了一段距离,他停住并转过身来,说:“你们在以我为圆心的圆周上。”然后他转身走得更远,再次转过身来说了一些东西。由于距离远,他说什么我已经听不清楚了。他每走到一个新的地方就再喊一次,我们终于知道他说的是同样的意思:“你们在以我为圆心的圆周上。”接下来他走得更远了。由于距离太远,他喊什么我都听不见了。等他转过身来使劲喊大概同样意思的时候,我忽然知道了什么是极限圆。
极限圆
Atiyah 问我们其中某些拓扑学家:平坦向量丛是否存在分类空间?他曾对这样的丛构造出一些新的示性类。由 Brown 定理,我们知道这东西存在,但是还不知道如何具体地构造出来。第二天,Atiyah 说,当他问 Thurston 这个问题的时候,Thurston 给出了一个神奇的构造:把作为向量丛结构群的李群看成一个抽象群,赋予离散拓扑,然后就给出分类空间。
后来,我听说 Thurston 通过画图证明给 Jack Milnor 看:任意单峰映射的动力系统模式都会出现在取适当值c时对应的二次函数 x → x2+c 的迭代中。我因为正在学习动力系统,所以就计划花一个学期的时间在普林斯顿,向 Bill 学习这篇从刚才提到的画图而发展出来的关于 Milnor-Thurston 万有性的著名论文。
Bill 和我每天重复这样的事情,配合得很完美。每天加州时间早上 8 点的时候,我准备好我的两场报告内容,做好一切提问的应对。当陈述 Bill 那些绝妙地控制住测地线长度的技术时,演讲推向高潮!这些测地线是分支皱褶曲面在分支处的曲线。要估计它们的长度,利用的却是内蕴曲面上测地流产生的动力系统的熵。这个熵又与分支曲面万有覆盖的面积增长率有关。但在负曲率的空间中,这个面积的增长速度却又被双曲球体的体积增长率所控制。证毕!不但如此,Thurston 还构造出一个漂亮的例子,表明估计的界是精确的。对于听众之一的 Harold Rosenberg(他是来自巴黎的精明的朋友)来说,这次报告的水平是超乎想象的。报告结束之后,他沮丧地问我:“Dennis,你是不是一直把 Thurston 锁在你办公室的楼上呀?”
在 2011 年 Banff 举行的 Jack Milnor 的 80 岁寿宴上,我和 Bill 再次相遇。在 30 年之后,我们从之前研究中断的地方重新开始。(当我第二次见到他的绿色格子衬衫时,我称赞这件衣服,第二天他就把衣服送给了我。)我们还约定一起去攻克 Klein 群和复动力系统框架里遗留下来的一个大问题:不变线场猜想。这是一个好主意,不幸的是,它永远都不可能实现了。
Thurston 在 Banff 的会议上讲解多项式迭代与熵之间的联系。
在那次会议上,当 Jeremy Kahn 报告他和 Markovic 合作的对长达数十年之久的子曲面猜想作出的证明的时候,Bill 小声对我说:“我忘了取偏移这一步了。”在 Kahn-Markovic 的证明中,需要把所有可能的理想三角形粘起来,构造出浸入的曲面,然后把遍历理论应用到在这个空间的作用上。当两个理想三角形沿着一条边粘合时,各自的中心在粘合的边上的垂足也许并不吻合,而是可以差了一个偏移量。这一步偏移保证了取极限时不遗漏任何东西,这也正是 Bill 之前的证明里漏掉的。我带着极为愉快的心情看到 Kahn 和 Markovic 完成了证明。证明的每一步都让我回忆起 30 多年前 Bill 发明的类似关键思想与技术。这些思想与技术都传递到他在普林斯顿的门徒们那儿了。
同一次会议上 Kahn 讲解他与合作者的技术。
本文英文原文出自Notices of the A.M.S.,2015 年 11 期。中文翻译曾发表于杜晓明科学网博客,此文为最新修订版,原文题目为“沃尔夫奖得主Sullivan:菲尔茨奖得主Thurston的十个故事”,现标题为编者所加。原文链接:https://www.ams.org/journals/notice
维灵顿·塞尔索·德梅洛(Welington Celso de Melo,1946-2016)是20世纪后半叶巴西数学界的杰出代表,以其在动力系统理论,特别是实一维动力系统和单峰映射重整化研究方面的开创性工作而闻名于世。这位严谨而富有洞察力的数学家不仅推动了数学理论的发展,还培养了一批优秀的学生,其中包括菲尔兹奖得主阿图尔·阿维拉。
阿维拉的学术道路堪称传奇。19岁时,他开始撰写关于动力系统理论的博士论文,并于2001年在IMPA获得博士学位,导师是著名数学家维灵顿·德梅洛(Welington de Melo)。同年,他前往法国进行博士后研究,师从1994年菲尔兹奖得主让-克里斯托夫·约科兹(Jean-Christophe Yoccoz)。
曼弗雷多·佩尔迪冈·多·卡莫(Manfredo Perdigão do Carmo,1928-2018)是20世纪巴西最具影响力的数学家之一,被誉为”巴西微分几何的元老”。他通过开创性的研究、经典教材的撰写和杰出学生的培养,将巴西推上了国际微分几何研究的版图。多·卡莫的学术生涯跨越半个多世纪,其贡献不仅体现在理论研究中,更在于他建立了一个繁荣的数学学派。
假努力的核心特征之一是过度文档化。在这种文化中,简单的任务往往被包装成复杂的流程。例如,本可以在一个小时内解决的技术问题,却需要员工编写大量分析报告并附上多种可视化图表,所谓的“知识沉淀”实际上只是对工作效率的拖延和时间的浪费。类似的情况还体现在数据的重复填写上,员工不得不在多个系统间手动同步数据,尽管这样的行为只是为了“闭环”数据流,实际上却消耗了几倍的时间和精力。而且在AI工具日益盛行的今天,不使用信息化和 AI 工具来分析数据,频繁使用手工统计数据就是企业效率低下的表现。
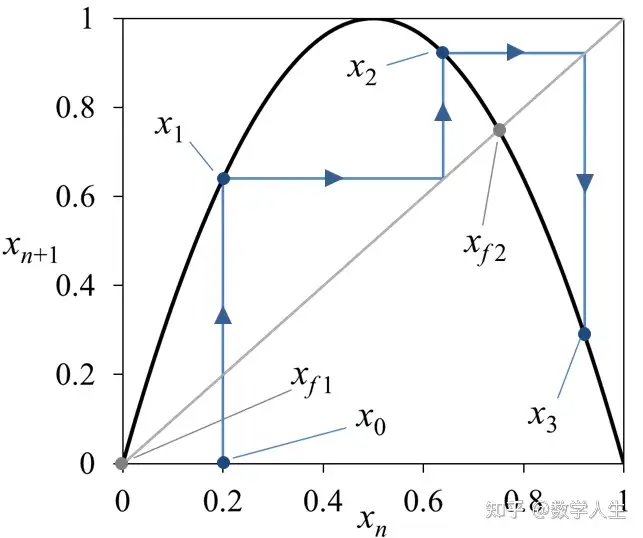
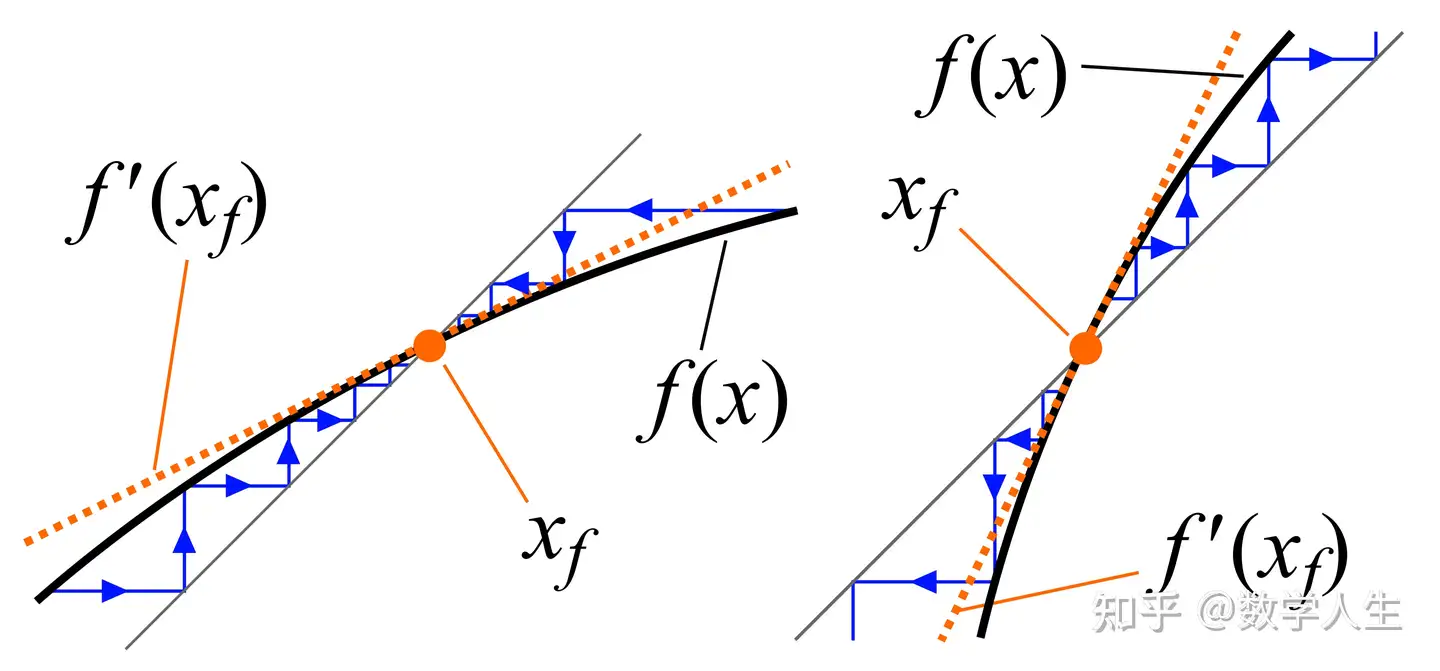
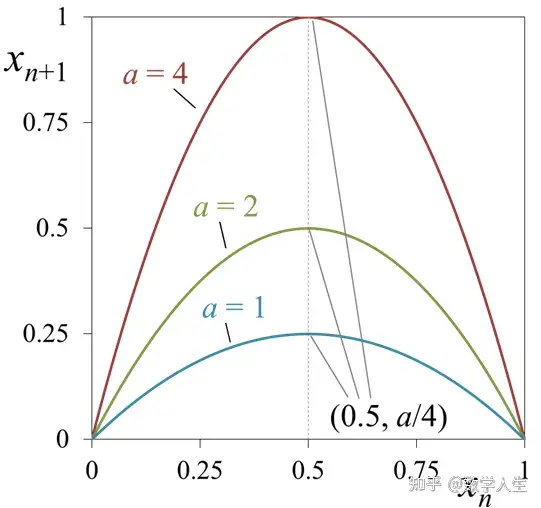
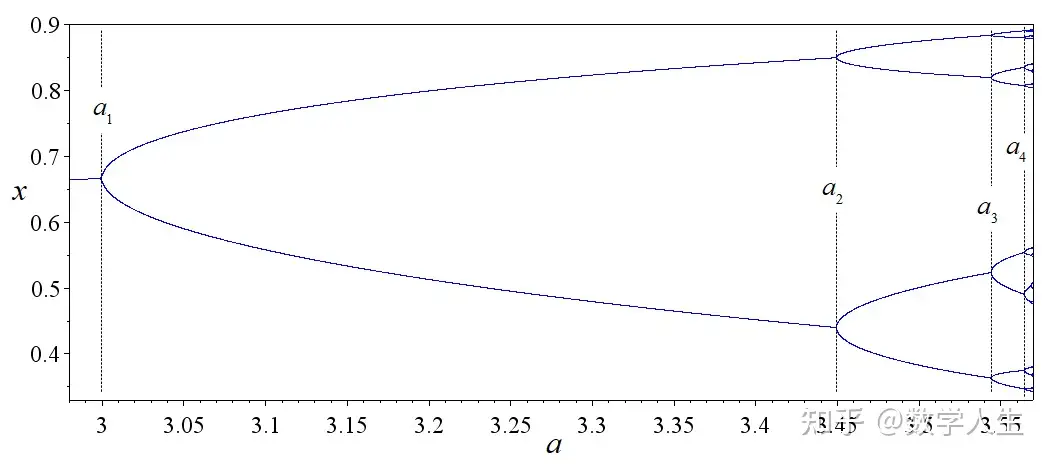
在2010年12月的新加坡,没有冬天,只有雨天。每天差不多下午四点,天色微暗,图书馆的窗外就会下起一场雷阵雨,雷声轰鸣却不让人害怕,反而像是某种自然的节奏。而且下雨的时间非常准时,不多不少,正好是每天下午的四点左右。当年由于办公位紧张,再加上我的运气一般,导致我没有抽到办公位,所以我每天就喜欢坐在新加坡国立大学的理学院图书馆(Science)靠窗的位置,桌上摊着一篇数学论文,题目看起来很有难度:《Polynomial maps with a Julia set of positive Lebesgue measure: Fibonacci maps》。这是导师布置的任务,要我找出这篇论文中的一个“gap”,而且这个gap是Xavier Buff在1997年就已经指出,但是又没有明确指出哪一段有问题。我当时还很年轻,对动力系统入门并不算久,也没有阅读论文的经历,面对那些抽象的定理和公式,一度感到焦头烂额。
这篇论文声称,对于足够大的偶数 \ell,总存在实数c,使得映射 z \mapsto z^\ell + c 的Julia集具有正的Lebesgue测度。这是一个重要的结论,也是一道未解的难题。可惜的是,1997年时法国数学家Xavier Buff指出论文中存在严重缺陷,但具体问题所在一直无人给出明确分析。导师要我做的,就是从这篇纸面看似无懈可击的证明中,找出那个致命的漏洞。那段时间,我每天在图书馆待到闭馆,翻来覆去地研究每一个lemma、每一页的推导,一边听着窗外准时的雨声,一边陷在公式构筑的迷宫里。
不过,Xavier Buff针对Fibonacci Maps还是撰写了一篇英文的文章《FIXED POINTS OF RENORMALIZATION》。他将经典多项式映射的重正化理论拓展至更广泛的映射类型(称为L-映射),特别针对具有特定临界轨道组合结构的斐波那契映射(非经典重正化对象),构建了一个封闭的自洽重正化算子。证明实对称斐波那契映射的迭代重正化序列会收敛到一个二阶周期循环(即两个映射交替互为重正化结果)。这两个映射在临界点邻域内表现相同,而在另一特定区域内则呈现符号相反的对称关系。通过重正化不动点导出关键函数方程(Cvitanović-Feigenbaum方程),并证明其解具有独特的几何性质:解的解析域是由拟圆边界界定的拟盘。由此构造的多项式类映射,其动力系统的Julia集具有拟共形等价性(如等价于某类多项式的朱利亚集或拟圆)。这篇论文虽然提供了一个不错的想法,但是对指出原始论文的Gap帮助有限。
做科研比较痛苦的事情就是思考问题,而且要克服的事情就是每天起床之后要面对一天的失败,毕竟365天起码有300天没有结果。经过我个人的不懈努力,一页一页磨,总算在博士第三年把论文推进到Chapter10。虽然推进的速度相对其他方向慢了许多,但是我在阅读论文的过程中还是把周边的论文都读了个遍,包括但不限于Fibonacci Interval Map、Fibonacci Circle Map、Renormalization Theory、Martingale Theory 等方向的书籍与论文资料,当时给我的感觉就是除了这篇文章没搞定,其他论文都搞定了。而且这篇原始的论文我差不多也花费了快三年的时间,可能是我个人的天分不太够吧。在2021年左右,我在师弟的一篇报道中看到下面这一段话,引用在这里以激励大家努力工作从而做出杰出成果:
最近到了2025年,回想起当时的种种,也觉得颇有一番道理。如果只是为了做一个普通的结果,那就最好不要去做了。还是要以核心的论文和课题为目标,只有树立远大的目标,最终才会有一个好的结果。比如说,在研究动力系统的过程中,如果以发表《Annals of Mathematics》为目标,那么说不定最终能发表一篇《Communications in Mathematical Physics》;如果以发表《Communications in Mathematical Physics》为目标,或许可以发表一篇《Ergodic Theory and Dynamical Systems》;如果以发表《Ergodic Theory and Dynamical Systems》为目标,最终可能只会发表一篇《Discrete and Continuous Dynamical Systems》;而如果以《Discrete and Continuous Dynamical Systems》为目标,那么估计最后只能发表国内期刊了。当时我还在读博士的时候,我们私下认为,要想在动力系统领域做下去,博士期间至少得发一篇《Ergodic Theory and Dynamical Systems》这个档次的论文,毕竟这算是动力系统领域的敲门砖,发表了之后就算是正式进入这个领域了。

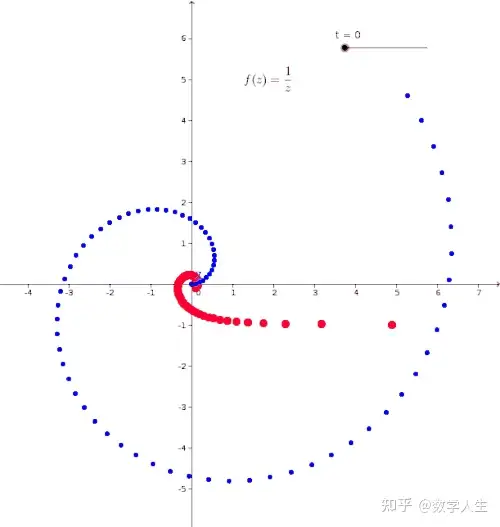




















 ,其中
,其中 称为最大伸缩比(Maximal Dilatation)。
称为最大伸缩比(Maximal Dilatation)。 是
是 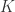 -拟共形的,如果对任意四边形
-拟共形的,如果对任意四边形  ,有:
,有:
 满足
满足  ,存在唯一的(在规范化条件下)拟共形映射
,存在唯一的(在规范化条件下)拟共形映射  ,使得其复导数
,使得其复导数 几乎处处成立。
几乎处处成立。 是拟圆周当且仅当存在常数
是拟圆周当且仅当存在常数 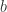 ,使得对任意三点
,使得对任意三点  ,
, 在
在  和
和  中间,有:
中间,有: (即“三点不等式”)
(即“三点不等式”)





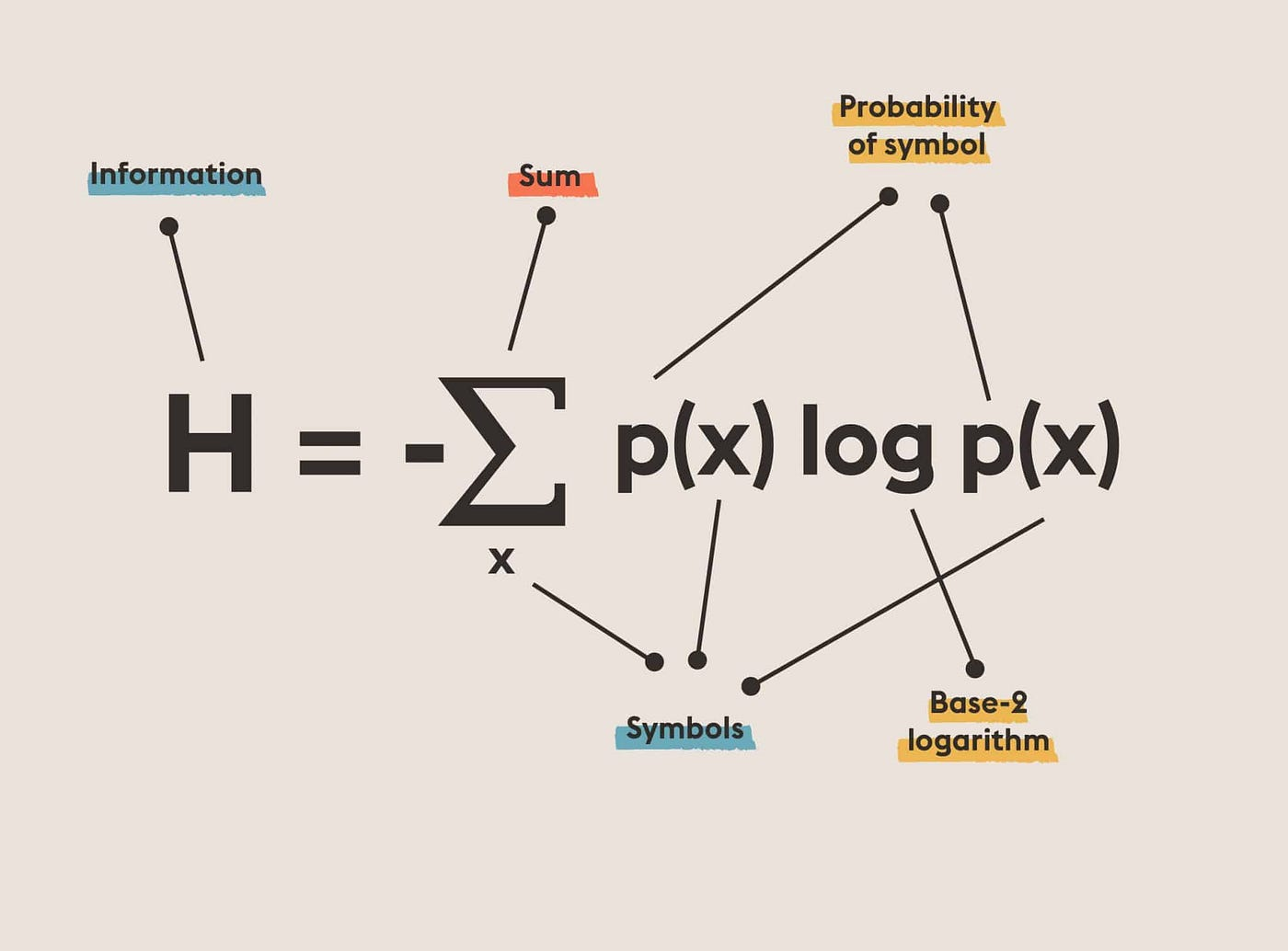







 ,其逐点下极限函数的积分不超过积分序列的下极限:
,其逐点下极限函数的积分不超过积分序列的下极限:











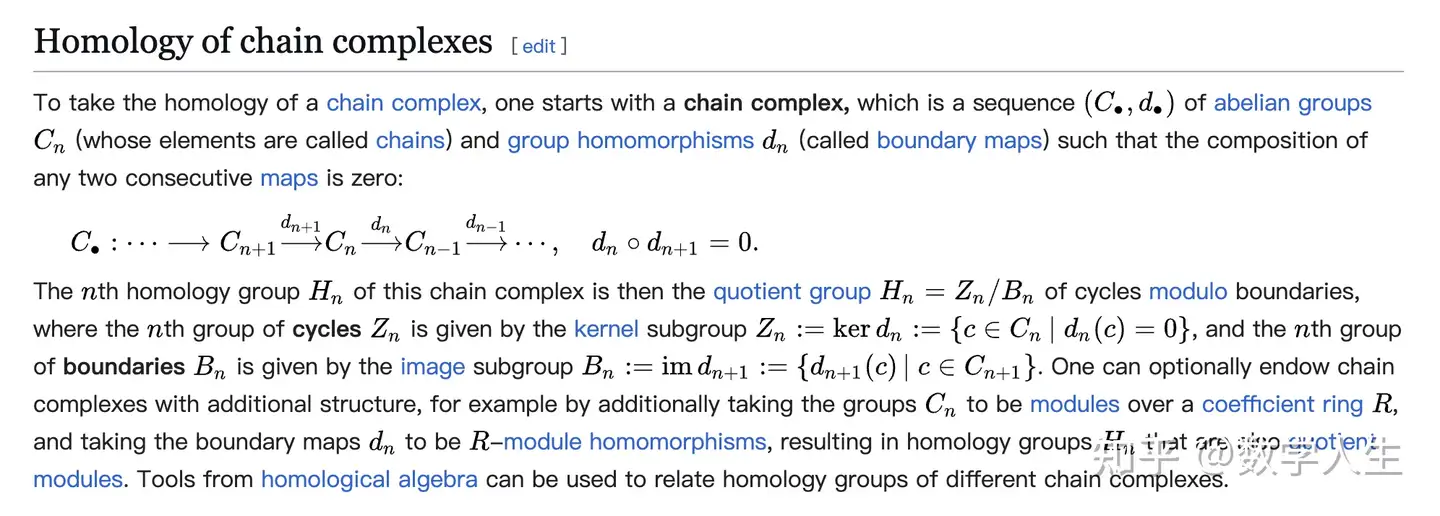











 ,是否存在无限多个素数对
,是否存在无限多个素数对 满足
满足  ,其中
,其中 为仅依赖
为仅依赖  的常数?
的常数? 。
。 若对所有素数
若对所有素数 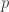 ,存在同余类避开所有
,存在同余类避开所有  ,则称为可容许的。素数
,则称为可容许的。素数  -元组猜想断言此类集合对应无限多
-元组猜想断言此类集合对应无限多  使
使  全为素数。
全为素数。 ,素数在模
,素数在模  算术级数中均匀分布(误差可控),则称素数具有水平
算术级数中均匀分布(误差可控),则称素数具有水平 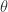 。Bombieri-Vinogradov定理给出
。Bombieri-Vinogradov定理给出  ,而Elliott-Halberstam猜想断言
,而Elliott-Halberstam猜想断言  。
。
 的权重,Maynard引入更灵活的多元函数:
的权重,Maynard引入更灵活的多元函数:  , 其中
, 其中 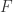 为光滑函数,支撑在
为光滑函数,支撑在  上。这种形式允许权重对各除数
上。这种形式允许权重对各除数  独立调控。
独立调控。 。假设Elliott-Halberstam猜想时,间距可降至12。对
。假设Elliott-Halberstam猜想时,间距可降至12。对  的普适界。
的普适界。 ,其中:
,其中: 为
为  -范数,
-范数, 反映
反映  时
时  ,
, 时
时  ,从而保证多素数对的存在性。
,从而保证多素数对的存在性。 、
、 )将
)将  )和精细的余项分析,确保主项主导。
)和精细的余项分析,确保主项主导。 形式,利用中心极限现象简化积分估计,证明
形式,利用中心极限现象简化积分估计,证明 。
。
 为第n个素数,定义G(X)为不超过X的连续素数之间的最大间距:
为第n个素数,定义G(X)为不超过X的连续素数之间的最大间距:
 的意思。
的意思。 。
。 。
。 初始c=1/3,后续研究主要集中于提高c值。
初始c=1/3,后续研究主要集中于提高c值。 。
。 覆盖区间
覆盖区间 ![[1,Y]](https://s0.wp.com/latex.php?latex=%5B1%2CY%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) ,使得
,使得 都是合数,从而在
都是合数,从而在 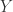 附近创造长度为
附近创造长度为 和随机边集
和随机边集  ,若满足:边基数有界:
,若满足:边基数有界: ,顶点度条件:
,顶点度条件: ,相关性控制:边集间依赖性弱,则可高效覆盖大部分顶点,这一工具为构造大间距提供了关键技术支持。
,相关性控制:边集间依赖性弱,则可高效覆盖大部分顶点,这一工具为构造大间距提供了关键技术支持。
 ,其中隐含常数是有效且可计算的。这一结果显著改进了Rankin的经典下界。他发展了随机覆盖技术处理可变的同余条件,将素数k元组猜想与间距问题联系起来,建立了筛法理论与组合覆盖之间的新联系。该工作引发了系列后续研究:证明存在包含完美
,其中隐含常数是有效且可计算的。这一结果显著改进了Rankin的经典下界。他发展了随机覆盖技术处理可变的同余条件,将素数k元组猜想与间距问题联系起来,建立了筛法理论与组合覆盖之间的新联系。该工作引发了系列后续研究:证明存在包含完美  )仍有差距,需要全新的思路。未来可能在以下方向突破:结合更精细的分布模型,发展处理高相关性筛法问题的新工具,探索素数分布与随机矩阵等领域的联系。
)仍有差距,需要全新的思路。未来可能在以下方向突破:结合更精细的分布模型,发展处理高相关性筛法问题的新工具,探索素数分布与随机矩阵等领域的联系。

 的素数对)。现状:尽管定理2(Zhang等)证明存在无限多对素数间隔不超过246,但猜想中“严格等于2”的结论仍未解决。该猜想是更广泛的素数k元组猜想的特例。
的素数对)。现状:尽管定理2(Zhang等)证明存在无限多对素数间隔不超过246,但猜想中“严格等于2”的结论仍未解决。该猜想是更广泛的素数k元组猜想的特例。 ,最大素数间隔满足:
,最大素数间隔满足: 。
。
 ,存在无限多整数
,存在无限多整数 同时为素数。现状:定理1(Maynard-Tao)证明了弱形式,即存在无限多
同时为素数。现状:定理1(Maynard-Tao)证明了弱形式,即存在无限多 个
个  )。现状:定理6表明,若该猜想成立,则素数最小间隔可降至6。但猜想本身未被证明,且是突破现有方法(如定理2中246的上界)的关键障碍。
)。现状:定理6表明,若该猜想成立,则素数最小间隔可降至6。但猜想本身未被证明,且是突破现有方法(如定理2中246的上界)的关键障碍。 个线性函数同时为素数。定理6指出,即使假设广义Elliott-Halberstam猜想,最小间隔下界仍无法低于6。大间隔问题:现有方法依赖于构造连续合数序列,其长度受限于最小素因子的分布。Maier-Pomerance猜想认为最大连续合数序列长度应为:
个线性函数同时为素数。定理6指出,即使假设广义Elliott-Halberstam猜想,最小间隔下界仍无法低于6。大间隔问题:现有方法依赖于构造连续合数序列,其长度受限于最小素因子的分布。Maier-Pomerance猜想认为最大连续合数序列长度应为: ,但当前结果(定理3)尚未达到这一预测。
,但当前结果(定理3)尚未达到这一预测。

 ,其中:
,其中: 是样本空间,
是样本空间,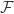 是事件,
是事件,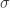 -代数,
-代数, 是概率测度这些公理至今仍是概率论的标准框架。条件期望:他严格定义了条件期望,使其成为现代概率论的核心工具。零一律(Kolmogorov’s Zero-One Law):证明某些极限事件的概率只能是0或1,这对随机过程的研究至关重要。
是概率测度这些公理至今仍是概率论的标准框架。条件期望:他严格定义了条件期望,使其成为现代概率论的核心工具。零一律(Kolmogorov’s Zero-One Law):证明某些极限事件的概率只能是0或1,这对随机过程的研究至关重要。
 ,
,
 空间):定义了最弱的分离公理,影响了一般拓扑学的发展。维数理论:他研究了拓扑空间的维数,并构造了开映射增加维数的反例,挑战了当时对维数的直观理解。
空间):定义了最弱的分离公理,影响了一般拓扑学的发展。维数理论:他研究了拓扑空间的维数,并构造了开映射增加维数的反例,挑战了当时对维数的直观理解。

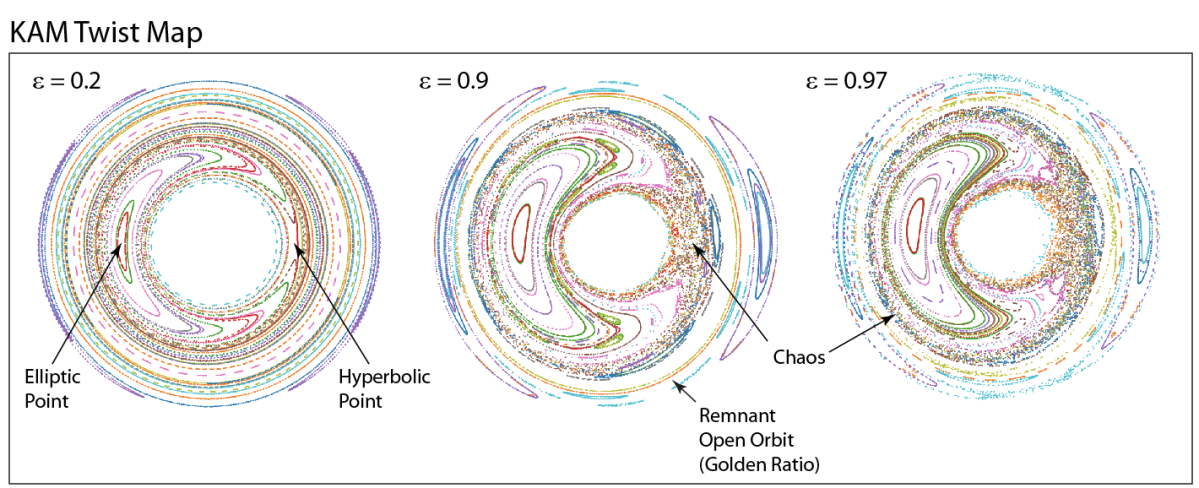
 类)。
类)。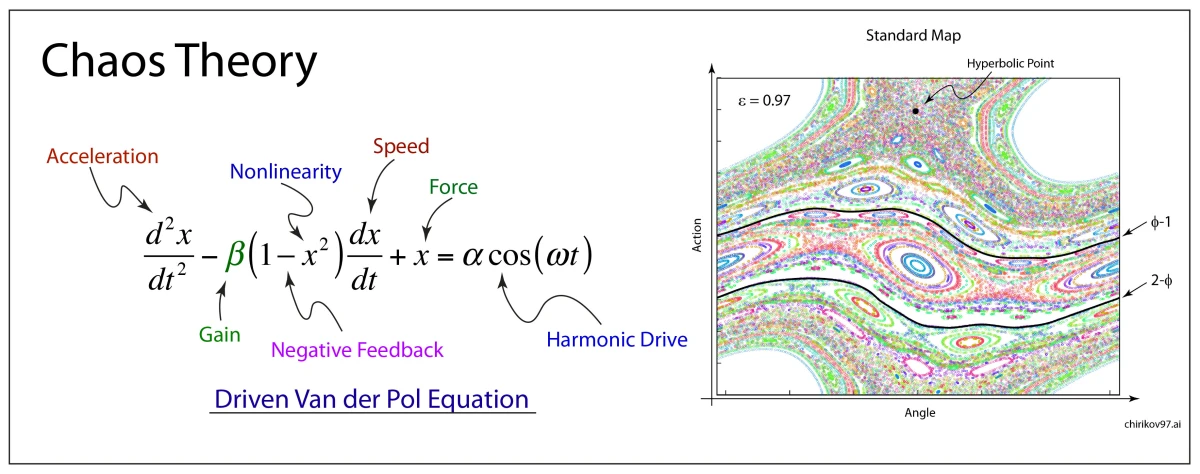
 ,确保系统非线性。
,确保系统非线性。 (
( ,
,  ),排除共振。
),排除共振。 ,实际物理系统可能超出此范围。
,实际物理系统可能超出此范围。 时,Arnold扩散表明非KAM环面区域可能存在缓慢混沌输运。
时,Arnold扩散表明非KAM环面区域可能存在缓慢混沌输运。














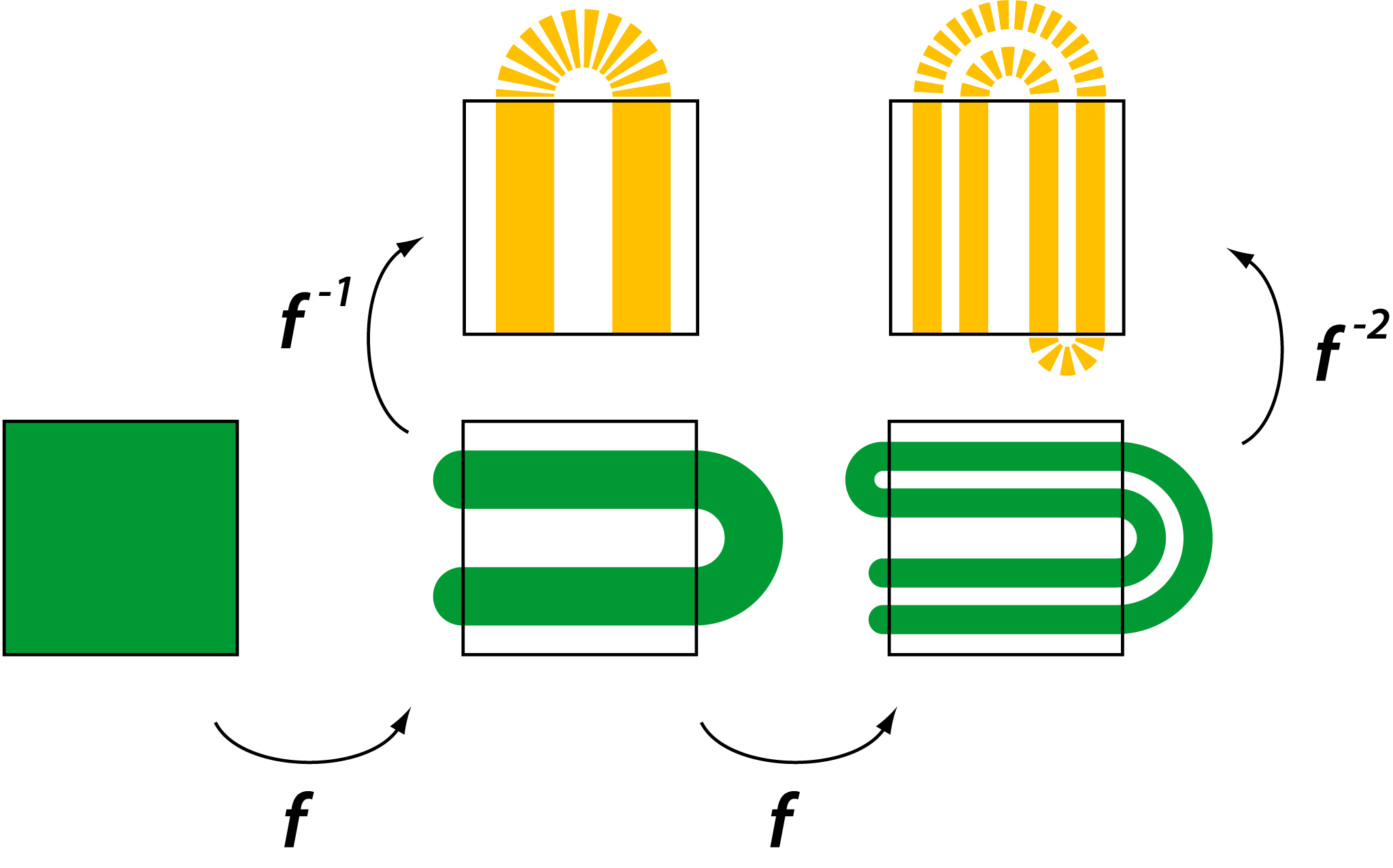
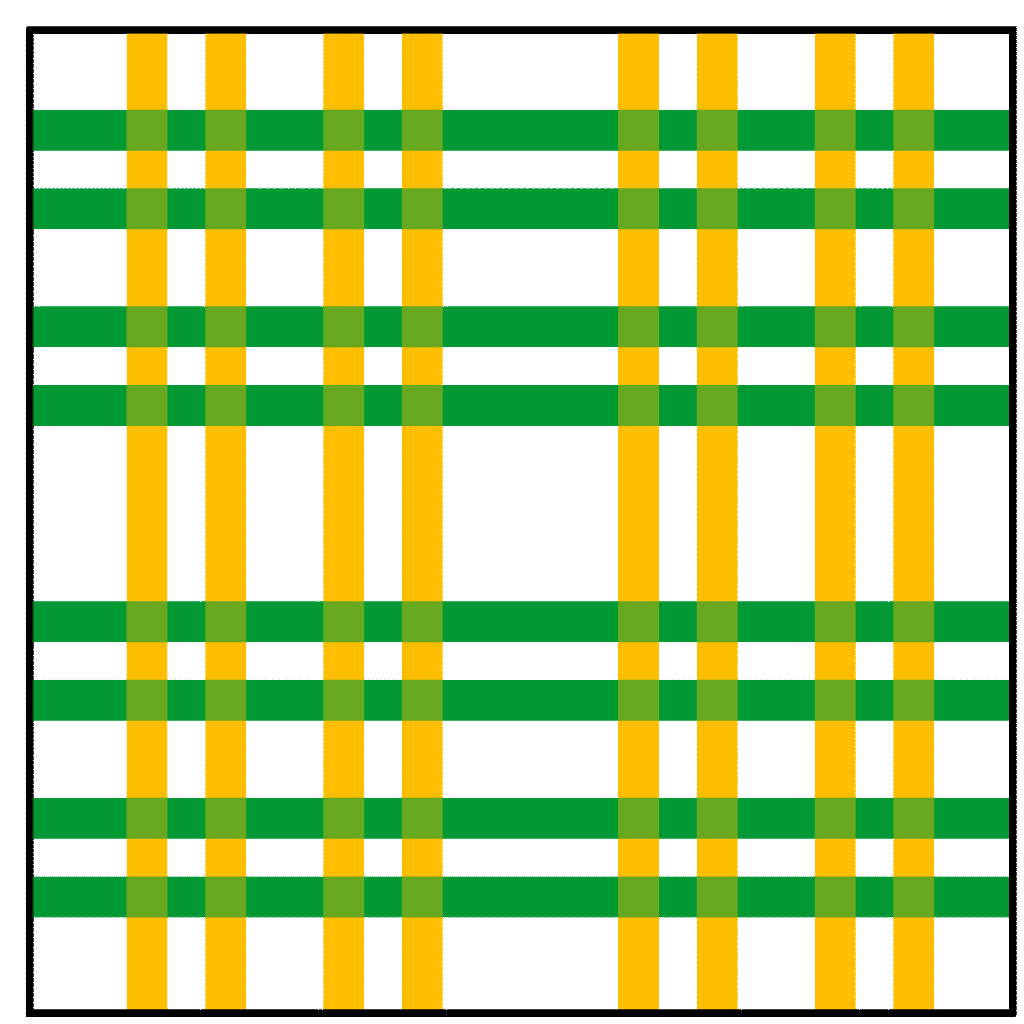
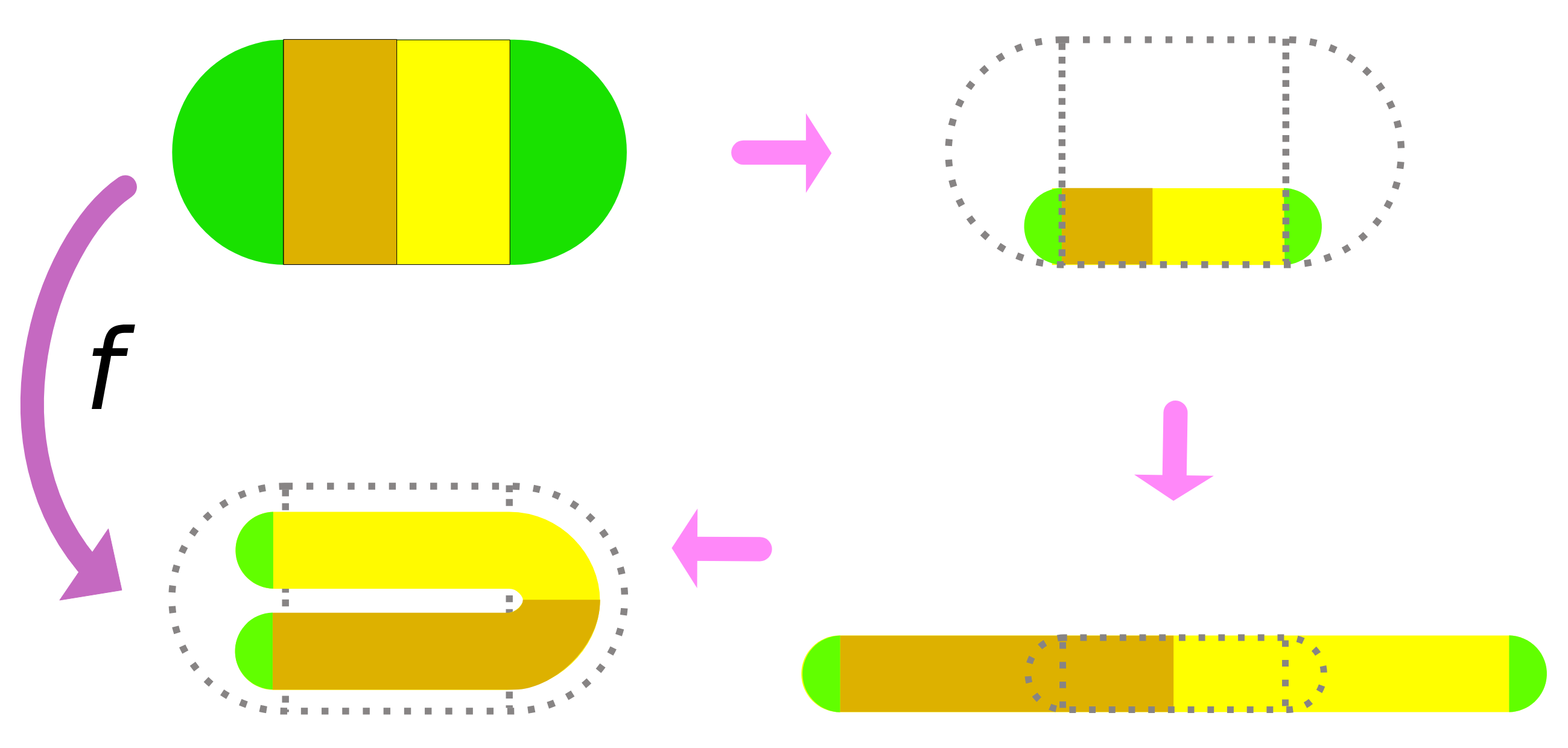
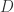 (例如单位正方形
(例如单位正方形 ![[0,1] \times [0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D+%5Ctimes+%5B0%2C1%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) )。马蹄映射
)。马蹄映射 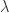 倍,
倍, )。
)。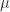 倍,
倍, )。
)。 则相当于反向操作,即垂直拉伸、水平压缩,并反向折叠。
则相当于反向操作,即垂直拉伸、水平压缩,并反向折叠。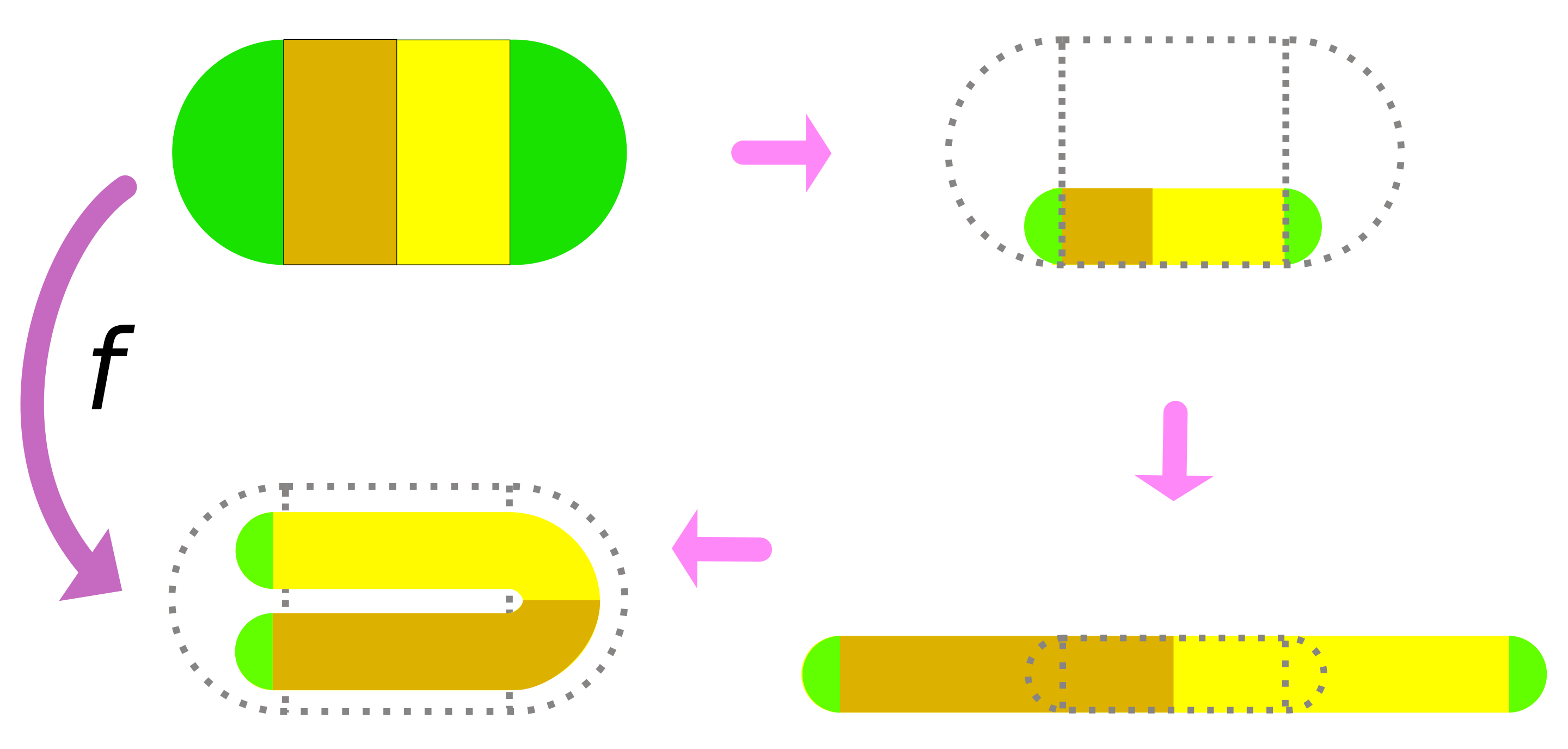
 。
。 )表示,其中“0”和“1”分别代表点在每次迭代中落在左侧或右侧条带。这种对应关系表明,马蹄映射的动力学行为等价于伯努利移位(Bernoulli Shift),即一个无限符号序列的混沌系统。
)表示,其中“0”和“1”分别代表点在每次迭代中落在左侧或右侧条带。这种对应关系表明,马蹄映射的动力学行为等价于伯努利移位(Bernoulli Shift),即一个无限符号序列的混沌系统。