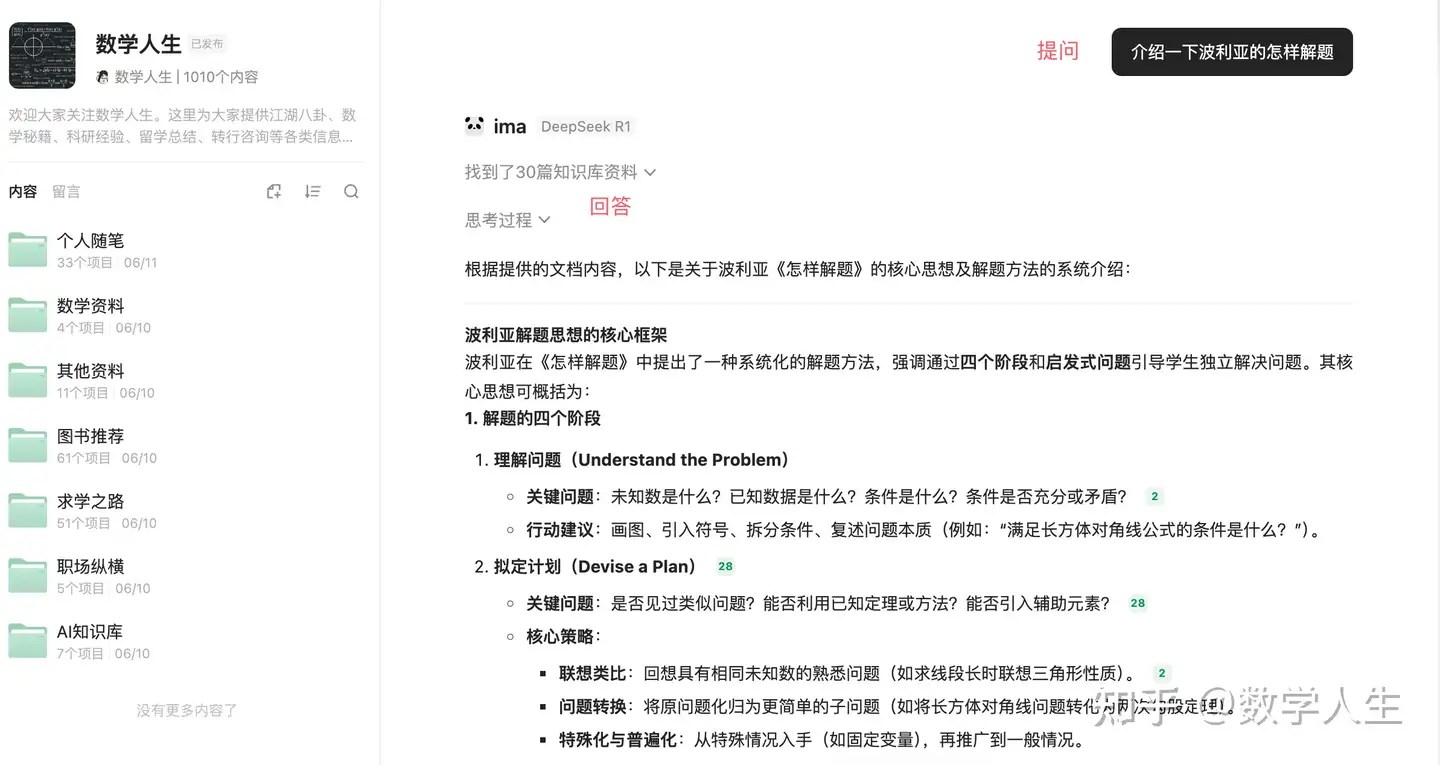
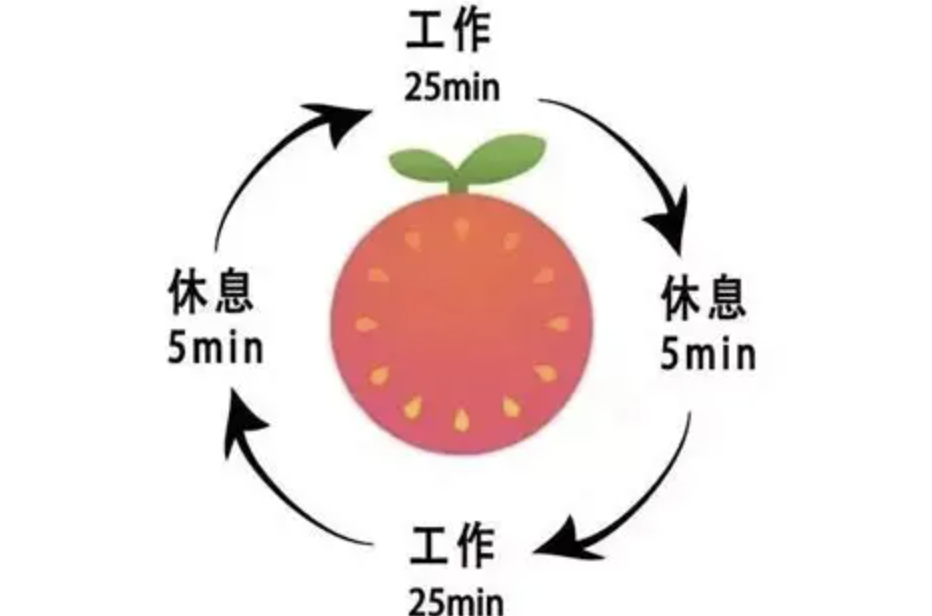
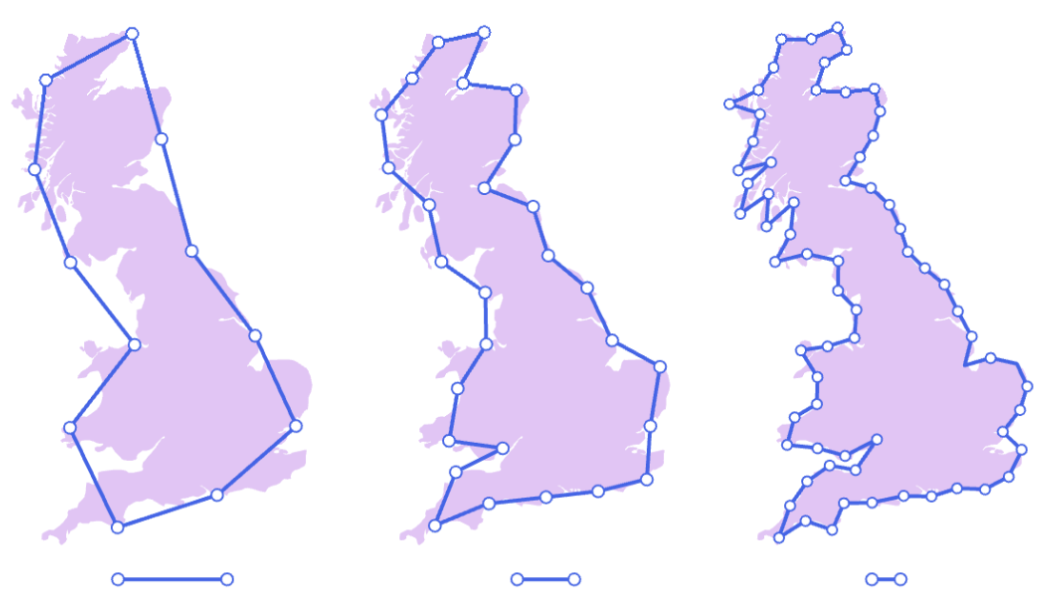
复动力系统: 对复平面上的简单函数(如 f(z)=z2+c ,其中 z 和 c 是复数)进行反复迭代。对于不同的初始点 z0 和参数 c ,其轨道行为(趋向无穷或保持有界)会形成极其复杂的边界。朱利亚集(Julia set)是使得迭代行为不稳定的点集边界。曼德布罗特集(Mandelbrot set)则是参数 c 的集合,使得从 z0=0 开始的迭代序列保持有界。这些集合都是具有精细结构和分数维数的著名分形。
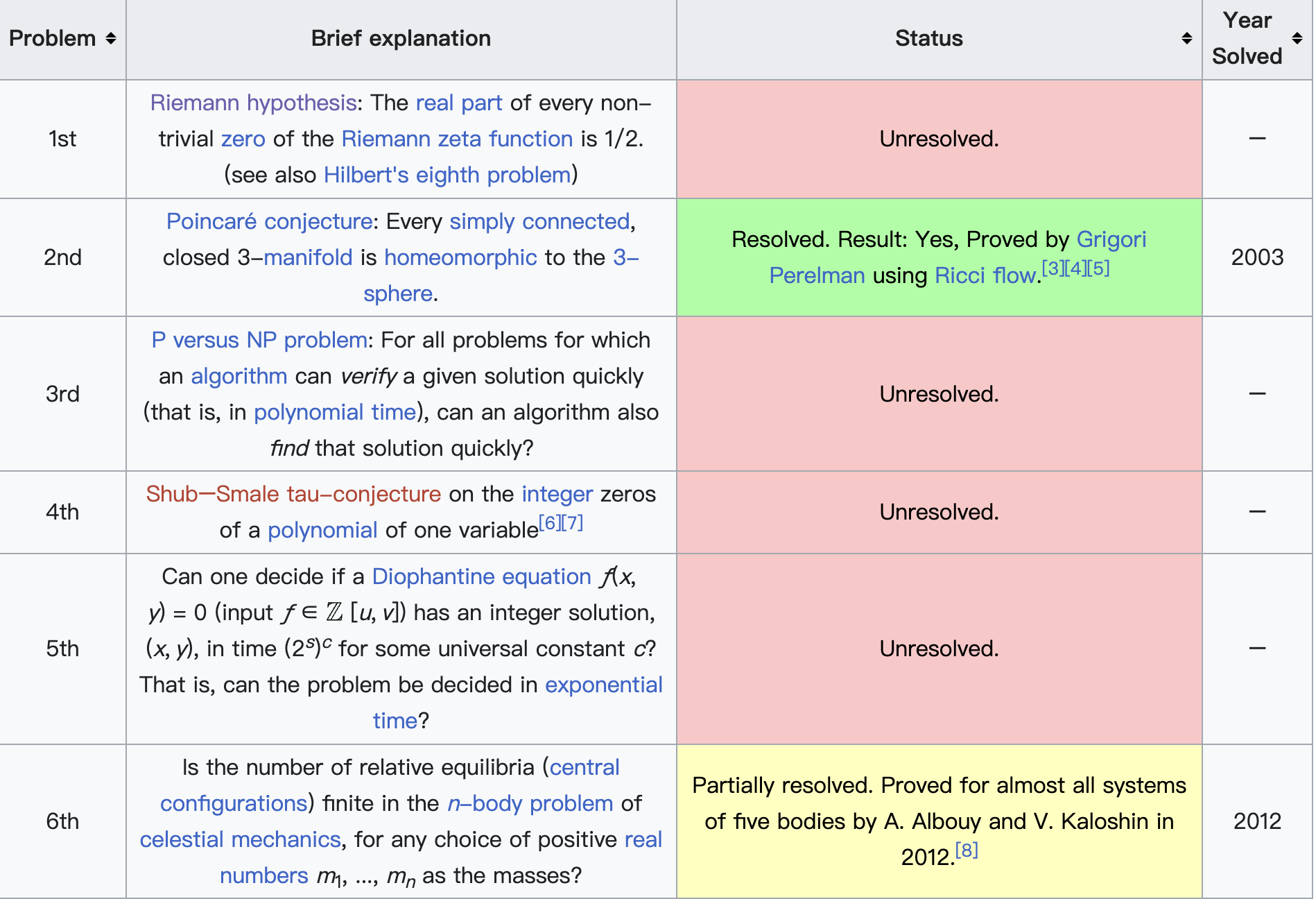
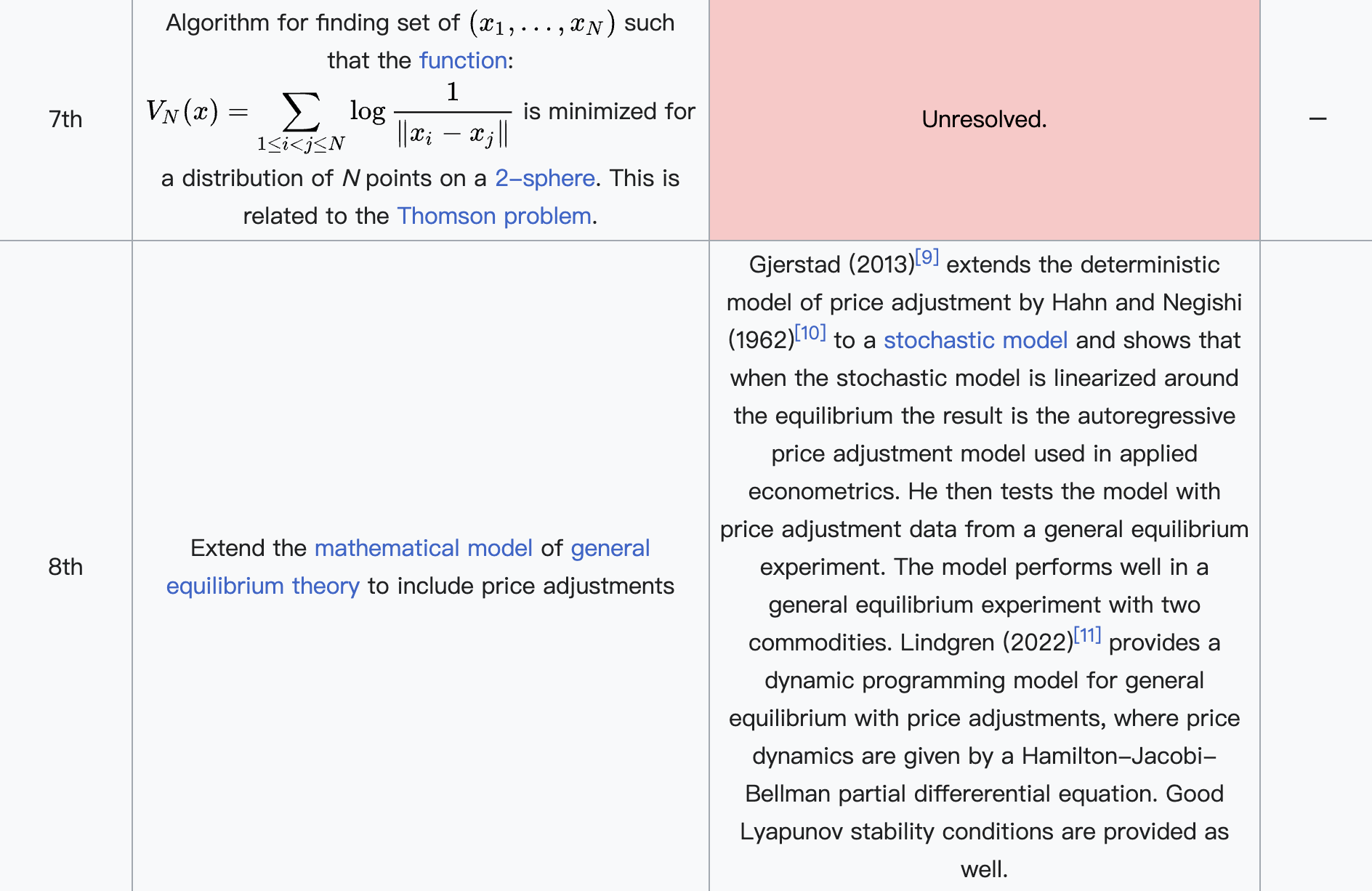
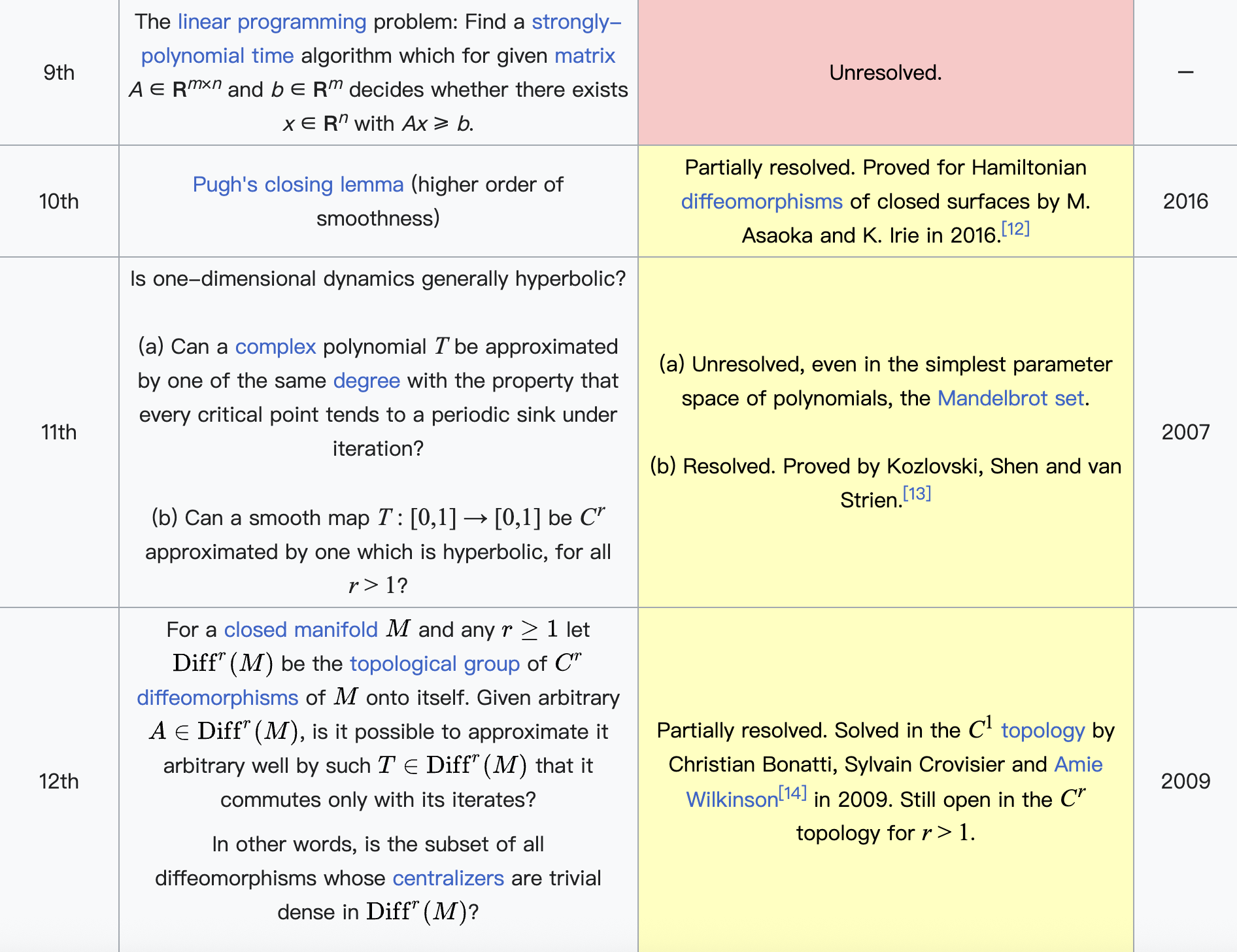
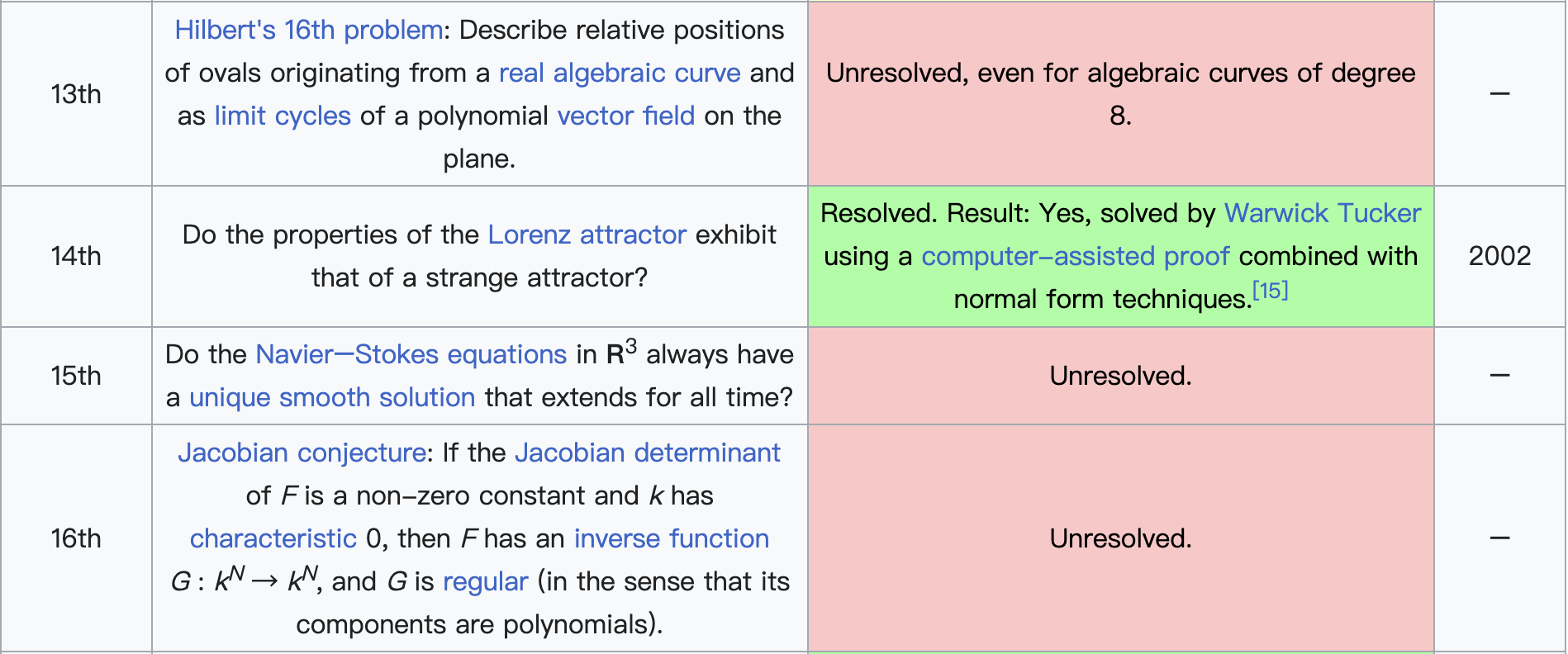
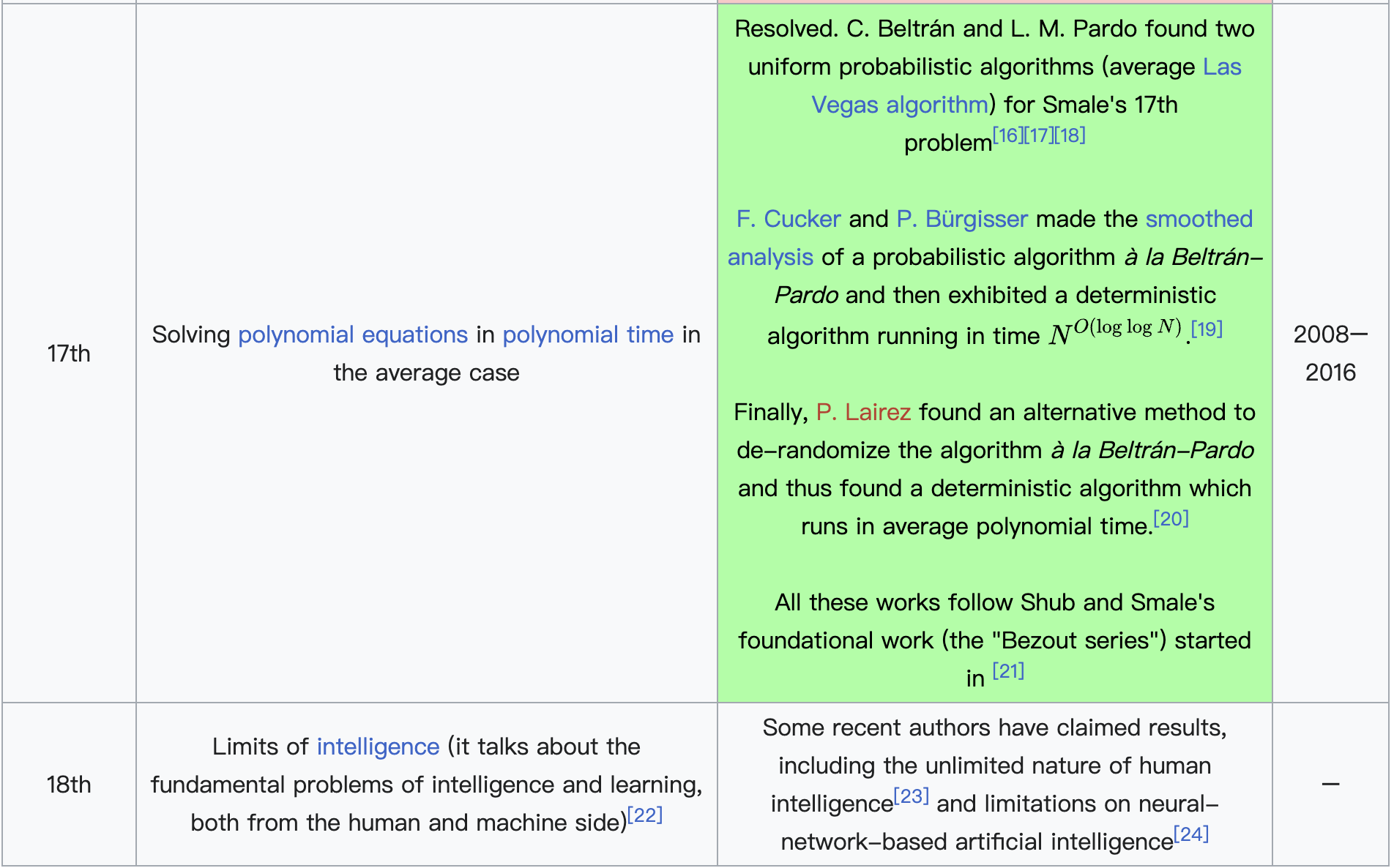
在斯梅尔看来,数学的发展不仅依赖于过去问题的解决,也需要对未来的大胆构想。1998年,他仿效大数学家希尔伯特的传统,发布了21世纪数学问题清单,总共列出18个未解的重要问题。这些问题涵盖数论、代数几何、计算理论、偏微分方程与动力系统等多个前沿方向。其中包括著名的黎曼猜想、P vs NP问题、纳维–斯托克斯方程的解的存在性与光滑性等,这些问题后来也被选为千禧年七大数学难题的一部分。斯梅尔的问题清单不仅展示了他对数学整体脉络的深刻理解,也对21世纪的数学研究方向产生了重要影响。
作为一位导师,斯梅尔同样具有极强的影响力。他培养的48位博士生中,有许多成为动力系统和混沌理论的领军人物,其中包括与他合著《微分方程、动力系统与混沌导论》的莫里斯·赫希(Morris Hirsch)和著名的科普作家、混沌研究者罗伯特·德瓦尼(Robert L. Devaney)。他们共同撰写的这本教材,已被引用超过12,000次,成为全球无数数学系与工程系课程的标准读物。
在现代数学的研究中,数学教育(Math Education)作为一个重要的研究领域,虽然看似不如一些前沿方向那么引人注目,但它仍然在 ICM 的标准中占有一席之地,数学教育也算是数学的研究方向之一。随着人工智能(AI)技术的飞速发展,数学教育与 AI 的结合呈现出巨大的潜力。从小学到大学的整个教育体系,AI 技术可以提供个性化的教学体验,助力每一个学生提升其数学能力。
ICM 2026 Speakers
如果是 AI 与数学教育相结合,那么可以做的东西就太多了。从小学开始,到中学,一直到后面的大学教育,都有数学的身影。从小学到大学阶段,AI 都能够提供个性化的教学体验。例如,在基础教育阶段,AI 可以通过智能算法分析学生的学习行为和学习进度,提供定制化的学习内容,帮助学生发现自己的薄弱环节,进而进行针对性训练。这种方式相比传统的一刀切式教学,可以更有效地提升学生的数学素养和解决问题的能力。
在大学阶段,数学学习不仅限于基础知识的掌握,还涉及大量的专业文献和研究论文的阅读与分析。面对复杂的数学论文,传统的阅读方式往往需要耗费大量的时间与精力,尤其是在理解深奥的理论、推导过程或未解决的问题时,学生和研究者往往感到力不从心。然而,借助 AI 工具,读者可以更高效地进行论文的“粗读”和初步分析。
论文总结
通过 AI 工具的支持,学生可以先对整篇论文进行快速扫描和概括,AI 可以提取出文章的核心内容,包括主要结论、方法论以及重要的数学定理和公式。这种自动化的初步整理,帮助学生更快速地把握论文的大致框架,从而为更深入的研究提供指引。此外,AI 工具还能够根据学生的需求,进行论文内容的梳理和重构,帮助他们在特定的学术背景或研究领域中找到所需的信息。这对于那些内容繁杂、篇幅冗长的论文尤其重要,能有效节省时间,减少信息过载的困扰。
学生可以把自己的教材、笔记、练习册扫描或者拍照后上传到 IMA 的知识库中。系统会自动解析文档内容,提取关键词并生成标签,比如“三角函数”“极限思想”等。这种结构化的知识整理方式,让学生不再受限于纸质资料的查找困难,一键就能定位所需内容。
有了自己的知识库之后,遇到不会做的题目就可以直接在 IMA 中提问。比如输入“如何证明勾股定理?”或者上传一张数学题目的截图,IMA 就会结合你上传的资料和知识库内容,自动生成解题思路和步骤,甚至会标注答案的出处,方便回溯学习。这种基于个人资料的 AI 问答,比传统搜索更精准、更贴合学生自己的学习节奏。
IMA 的「知识库广场」中还有大量公开的数学资源,如“高中数学大全”“竞赛题型解析”等。学生可以加入这些共享知识库,直接提问获取优质解答,甚至还能将自己整理的公式表、真题解析上传创建共享库,与同学互助协作。更贴心的是,IMA 还能识别手写公式并转化为可编辑文本,对于板书、笔记内容的整理极为方便。同时,通过输入“制定7天微积分复习计划”,学生还能生成个性化的学习方案,配合手机和电脑端的同步功能,随时随地保持学习节奏不掉队。
作为一名数学系研究生,我们的学术道路上往往充满了理论与实践的挑战。从深奥的数学证明到应用实践的编程,我们不仅要精通数学知识,还要能将这些理论转化为实际应用。尤其是当前,AI技术正在成为数学与计算机科学交叉的前沿,跨足 AI 领域,提升编程能力与实践能力已经成为许多数学系学生的必修课。最近,我使用了一款由腾讯推出的 AI 智能工作台 —— ima,它帮助我在寻找实习、学习计算机基础知识、整理资料、参加建模竞赛等多个方面大大提升了工作和学习效率。今天就和大家分享一下,数学系研究生如何通过 ima 跨足 AI 领域。
寻找实习与职业规划,ima 帮你整理资料与提升能力
在研究生阶段,我们不仅要专注于学术研究,还需要关注未来的职业发展。尤其是进入 AI 方向,我们往往面临如何高效找到实习机会的问题。通过 ima,我可以在“知识库”中专门创建一个【实习机会】文件夹,收藏一些求职网站的页面、HR推荐的公司信息、以及相关领域的招聘职位。通过一键保存网页内容,我把所有相关资源集中到一个知识库中,随时可以查看和更新。
不仅如此,ima 还支持全网搜索功能。当我输入“数学研究生 AI 实习”时,ima 会从各大招聘网站、公众号等地方搜寻到相关的职位信息,生成图文并茂的答案,帮助我迅速掌握市场动态。同时,它还能结合我的个人兴趣和目标提供一些定制化的建议。
学习计算机基础知识,快速补充 Linux、网络等技能
作为数学系的学生,我们的编程背景可能相对薄弱。特别是在 AI 和大数据分析中,掌握计算机基础知识,如 Linux 操作系统、网络编程、数据结构和大模型的应用,变得尤为重要。在这一方面,ima 的智能搜索和知识库管理功能非常有用。
我利用 ima 上传了大量计算机基础知识的书籍和学习资料,创建了【计算机基础】知识库,包含了 Linux 命令行操作、Python 编程、机器学习基础等内容。当我遇到不懂的概念时,只需在 ima 搜索框输入问题,比如“如何搭建深度学习环境”或者“网络编程中的 TCP/IP 协议”,ima 会帮助我从全网内容中提取精华,快速生成详尽的图文答案,帮助我理解并记忆复杂的计算机知识。
通过创建一个团队共享的知识库,我可以在其中安排各自的任务、记录讨论结果、总结工作进展,并利用 ima 的分类与标签功能,方便地对每个项目文件进行组织管理,确保团队成员能快速获取最新的资料与思路。
用 AI 辅助提升编程能力,事半功倍
在数学系的学习中,编程能力是不可或缺的。ima 不仅能帮助我整理编程资料,还能在编写代码时提供实时帮助。我常常通过 ima 的 Markdown 编辑器记录编程笔记,输入 “/” 唤起 AI 来扩写代码或修正错误。例如,在学习机器学习时,我遇到过一个调参的难题,直接输入问题,AI 会根据已有的资料和我上传的代码给出优化建议,帮助我解决问题。
工欲善其事必先利其器
ima 是一款非常适合数学系研究生的工具,它不仅可以帮助我们高效管理学习资料、提高编程能力,还能够在职业发展中为我们提供有价值的建议与资源。通过智能搜索、知识库管理、团队协作等功能,ima 让我们在学习、竞赛、实习、职业规划等方面都能事半功倍。如果你也想像我一样,通过 AI 工具提升自己的学习效率和实践能力,赶紧去体验 ima 吧!你可以从官网下载客户端,或者在微信小程序中搜索“ima 知识库”,开启你的 AI 学习之旅。
大学生活节奏紧凑,尤其是对于数学系的学生来说,每学期要面对多个高强度的专业课程,如高等代数、实变函数、数理统计,以及不断出现的编程课、选修课、通识课,资料来源五花八门,整理难度也越来越大。如何把零散的知识系统地管理起来?我最近尝试了一款由腾讯推出的 AI 工具 —— ima 知识库,发现它非常适合我们这种需要“多线程”处理信息的大学生,尤其是理工科学生。今天就来和大家分享一下我的使用经验。
把所有学习资料放进个人知识库,从此告别混乱
以前我笔记一部分文件堆在电脑桌面,公众号收藏夹也是“看过就忘”,几周下来就乱作一团。有了 ima 后,我直接在 PC 端新建了几个知识库:比如【数学分析】、【高等数学】、【C++编程基础】、【军事理论】等。讲义 PDF、老师分享的 PPT、参考资料、刷题记录都能上传,还能一键收藏网页和公众号文章。
更厉害的是,如果我在自己的知识库中提问,ima 会只根据我自己的笔记资料回答问题,比如输入“#概率论 期末重点”,它会生成我之前所有笔记、重点总结的融合回答,避免了 AI 胡编乱造的“幻觉”,特别适合期末复习或准备报告时查缺补漏。
不只是做笔记,更是内容创作的帮手
数学系同学日常还要写作业、小论文、通识课项目总结之类的内容。我一般用 ima 的 Markdown 编辑器来写笔记和文档,随时可以输入 / 唤起 AI 帮我扩写、生成段落,甚至可以生成配图和思维导图。我还尝试用它写过一个“素数间距”的初稿,只输入了一点点提纲,AI 帮我扩展了思路,还能帮忙翻译查找外文资料,省心又省力。
微信小程序+多端同步,哪里都能用
最让我满意的是它的多端同步。我在教室或者食堂突然想到一个公式推导的思路,打开手机上的 ima 小程序随时记录;课后在寝室用MacBook端继续补充;周末去图书馆打开 Windows又能无缝衔接,所有内容都在云端同步,还有 30G 免费空间,非常实用。对于我们这种经常用到不同设备的学生来说,统一平台+实时同步太友好了。
ima 更像是我的学习助理,帮助我在信息爆炸的时代,把碎片知识收集起来、整理清晰,并且在需要时快速调用出来。不管你是刷题、写论文、找资料、记录灵感,甚至和同学协作,ima 都能提供非常实用的功能。推荐大家都去体验一下,特别是数学、计算机、物理等理工科专业的同学,可能你会像我一样,一用上就“停不下来”。
刚入学新加坡国立大学(NUS)时,作为一名数学博士,我为自己设定了一个明确的目标:在四大数学期刊上发表论文,即《Annals of Mathematics》、《Inventiones Mathematicae》、《Journal of the American Mathematical Society》和《Acta Mathematica》。这个目标是我科研生涯早期最重要的方向,也是我不断努力的动力源泉。
从 2004 年前后开始(请知情人指正),Shaw 成立的 DE Shaw Research(DESRES)开始正式运营。在 David Shaw 的精心包养下,30 多个失业的博士屌丝们什么也没干,在优雅的环境里,足足读了一年半的论文,搞出了 Anton 的草图。之后,更多的屌丝加入,全身心专注于 Anton 的研发。
2007 年,比预期还早了快一年,来自五湖四海的屌丝和 geek 们发布了 Anton 的第一代。计算化学的最大黑科技诞生了:它比一般的超级计算机快约 10,000 倍。比最好的超算也快 1,000 倍。
对的。变态的 10,000 倍,四个零,四个数量级。
10000 倍是什么意思呢?计算化学里面,模拟分子运动轨迹的持续时间的长短是非常重要的。用模拟网球比赛来做类比:以前“超级计算机”算了一个月,我们只能模拟出击球的 1 秒钟的瞬间,而现在 Anton 出世,我们同样花一个月,就可以模拟整场球赛中网球的轨迹了。












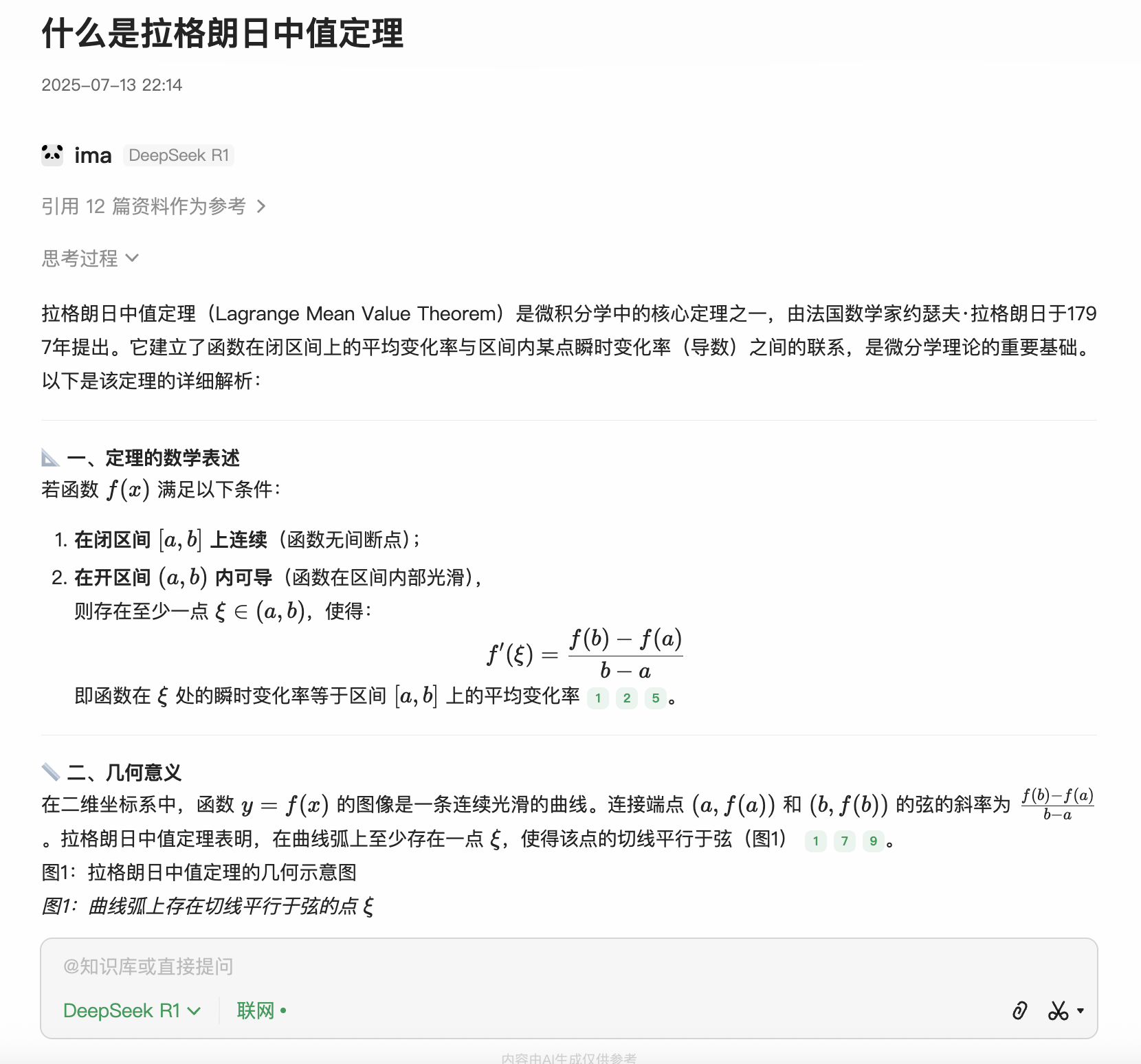
 使得
使得  这个区域内没有黎曼函数的零点,都是巨大的突破。
这个区域内没有黎曼函数的零点,都是巨大的突破。 ,于是提出猜想:
,于是提出猜想: (对数积分)。数学家勒让德(Adrien-Marie Legendre,1798)在《数论随笔》中提出经验公式:
(对数积分)。数学家勒让德(Adrien-Marie Legendre,1798)在《数论随笔》中提出经验公式: ,首次尝试用解析方法逼近素数分布。
,首次尝试用解析方法逼近素数分布。 使得:
使得:  具体值:
具体值: ,
, 。他使用的关键工具是切比雪夫函数
。他使用的关键工具是切比雪夫函数  ,并且证明
,并且证明  当且仅当
当且仅当  。
。 函数,并发表论文《论小于给定数值的素数个数》,定义:
函数,并发表论文《论小于给定数值的素数个数》,定义:  。解析延拓至复平面(除
。解析延拓至复平面(除  外全纯)。显式公式给出
外全纯)。显式公式给出  的精确表达式(含黎曼函数的零点):
的精确表达式(含黎曼函数的零点):  。
。 ,则素数定理误差最优。
,则素数定理误差最优。 (对
(对  ),并推出:
),并推出:  。具体的方法:
。具体的方法: 的欧拉乘积和非零性,证明
的欧拉乘积和非零性,证明  在
在  解析。
解析。
 。
。 。
。 模式。
模式。 推出 PNT。
推出 PNT。 无零点,而黎曼猜想要求
无零点,而黎曼猜想要求  。
。 上无零点的结论,直接等价于数论中的核心定理——素数定理(Prime Number Theorem)。根据刚刚的陈述,素数定理描述素数分布渐近行为:
上无零点的结论,直接等价于数论中的核心定理——素数定理(Prime Number Theorem)。根据刚刚的陈述,素数定理描述素数分布渐近行为:  或等价形式
或等价形式 其中:
其中: 的素数个数,
的素数个数, 对所有实数
对所有实数  在
在  表示为复积分:
表示为复积分: 

 )弱得多,但已足以推出素数分布的主项。
)弱得多,但已足以推出素数分布的主项。 ,但无零点条件仅给出
,但无零点条件仅给出  。
。 )中零点分布,有以下结论:
)中零点分布,有以下结论: )处有零点,这些零点称为平凡零点。
)处有零点,这些零点称为平凡零点。 ),且是
),且是  )内。
)内。 上。
上。 (
( 为正整数):除负偶数(平凡零点)外,
为正整数):除负偶数(平凡零点)外, 表明,若
表明,若  是零点,则
是零点,则  也是零点,但平凡零点仅在负偶数处。
也是零点,但平凡零点仅在负偶数处。 成立,这是素数定理证明的关键步骤。
成立,这是素数定理证明的关键步骤。 ,其中
,其中  是常数。
是常数。 :无零点(欧拉乘积收敛且非零)。
:无零点(欧拉乘积收敛且非零)。 ),但黎曼假设认为它们实际全部位于
),但黎曼假设认为它们实际全部位于  使得
使得 
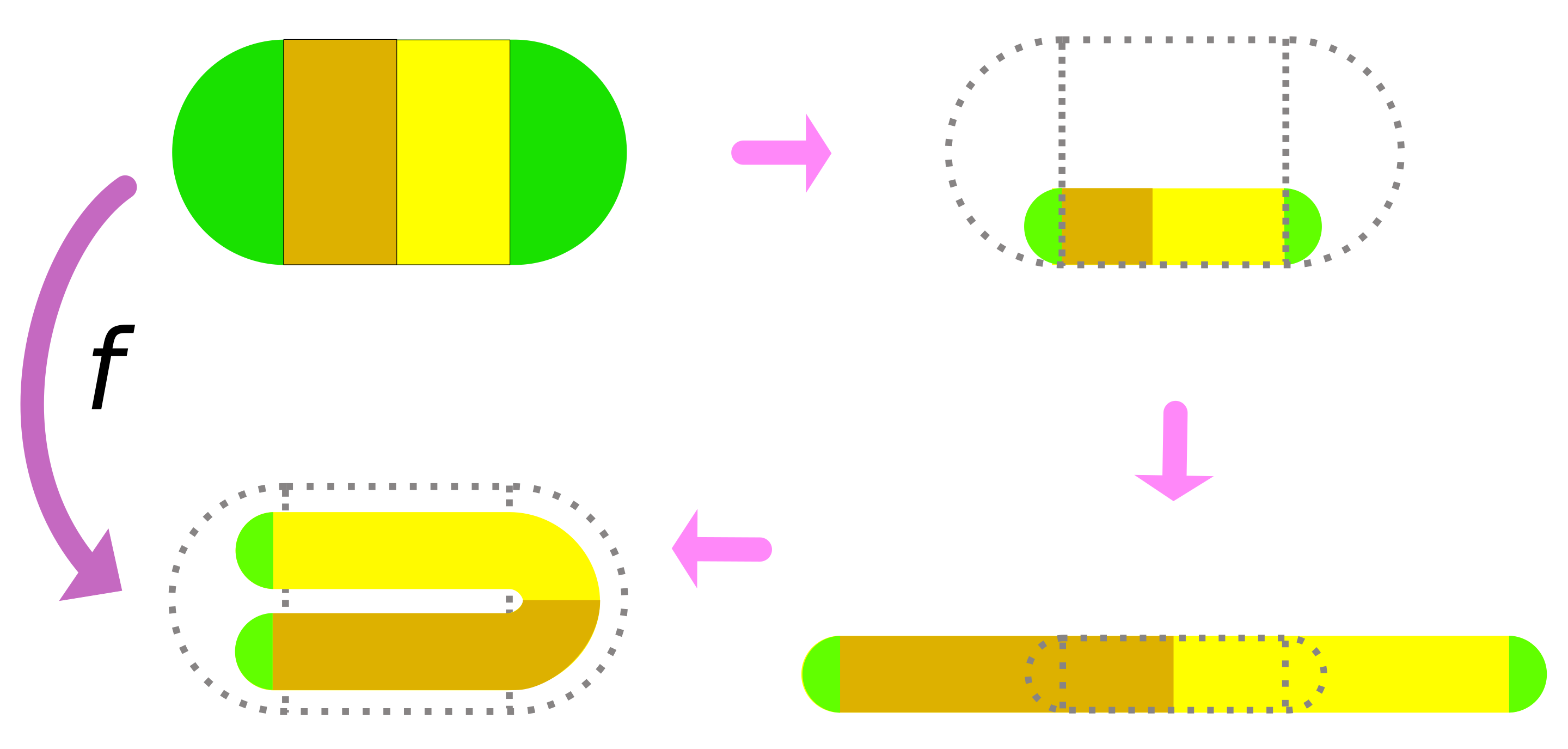

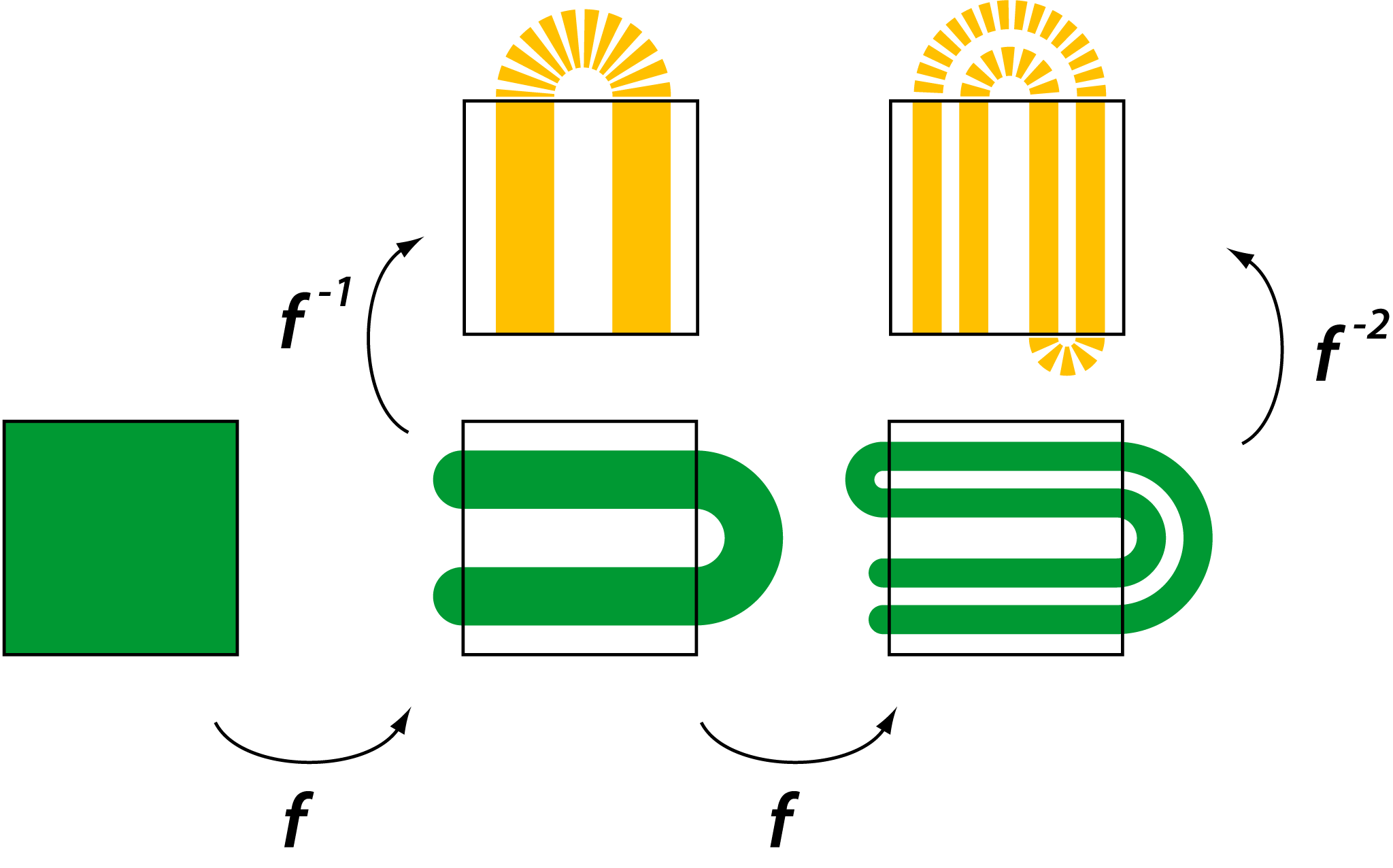
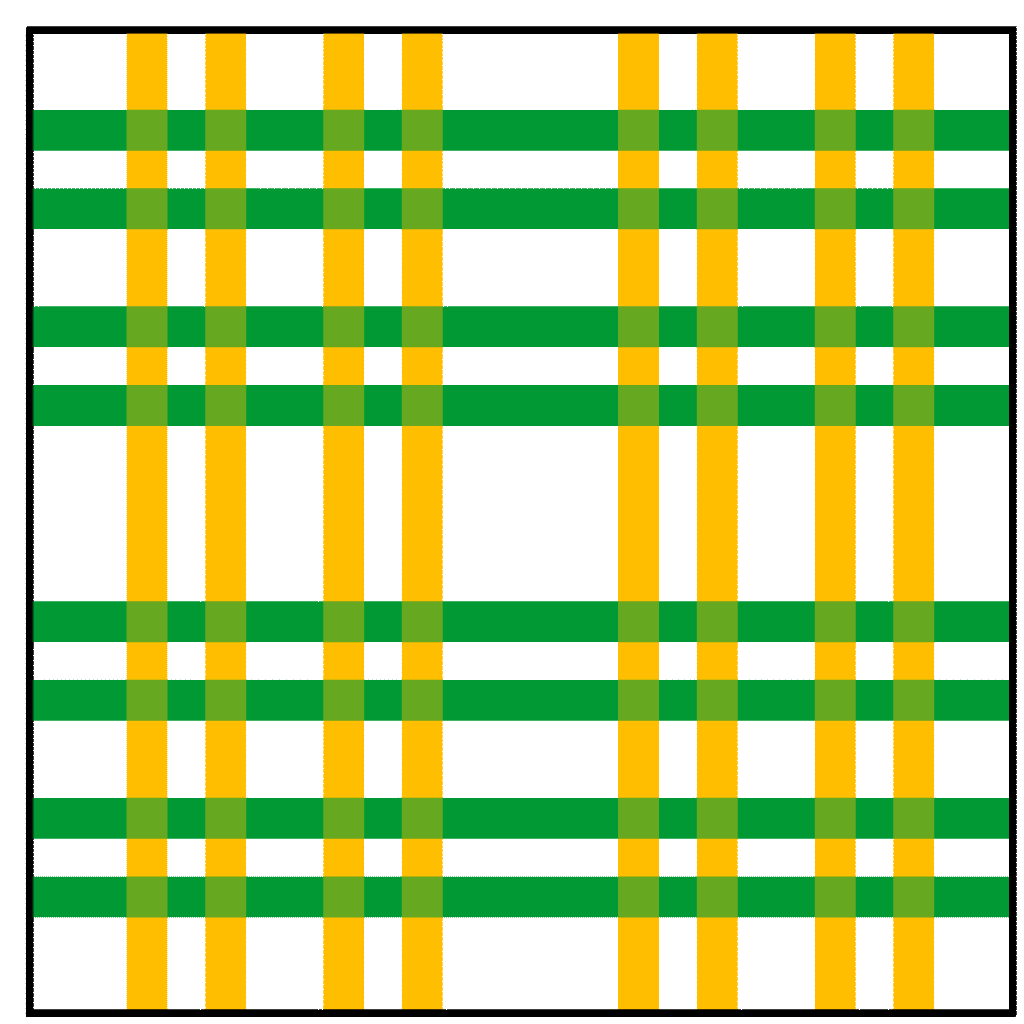


 。
。 。
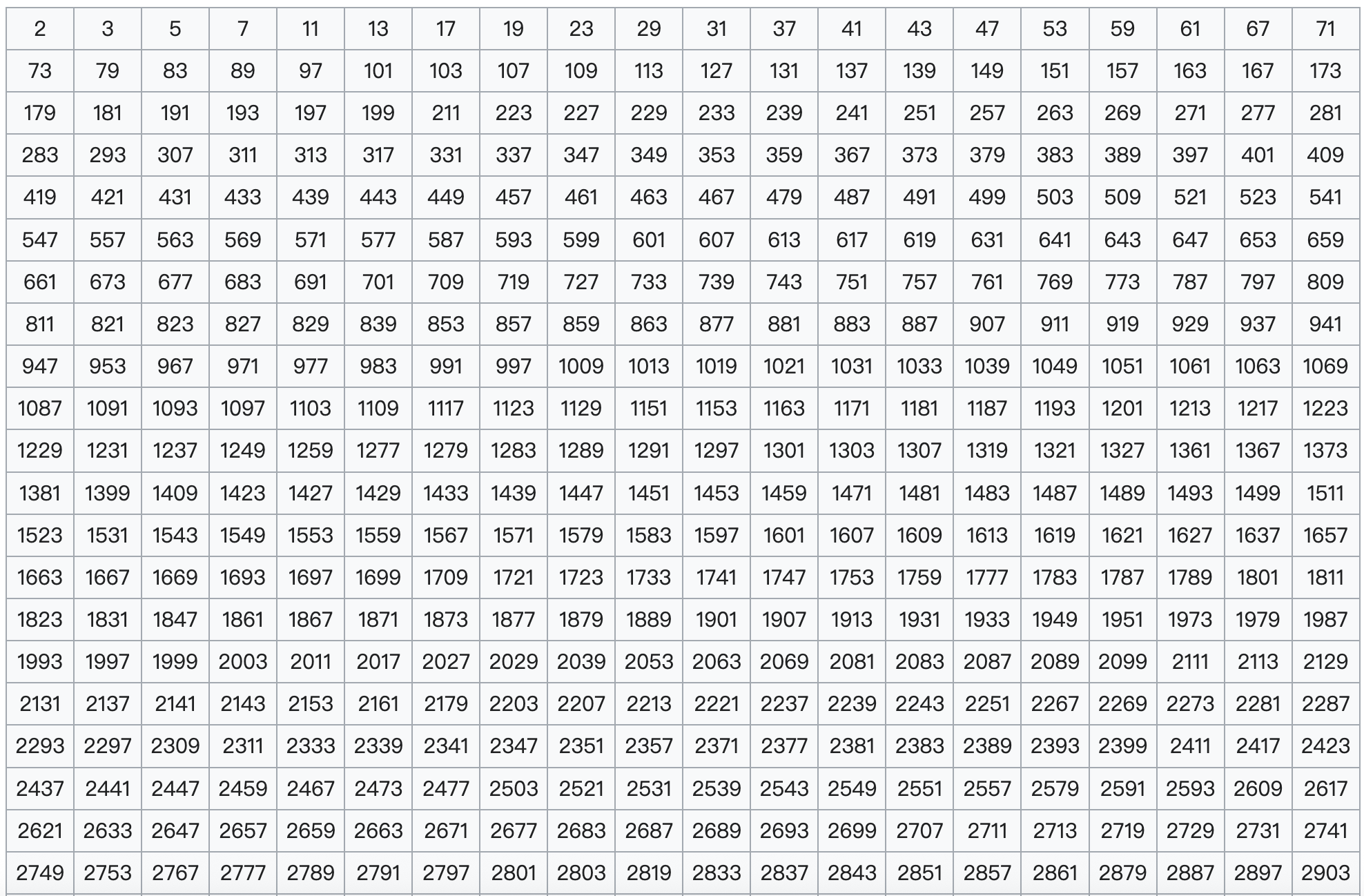
。 不被任何
不被任何  整除(因
整除(因  )。
)。

 时,有:
时,有:  表示渐近等价,即:
表示渐近等价,即:  。通过数值的计算,我们可以直接得到下面的计算结果。
。通过数值的计算,我们可以直接得到下面的计算结果。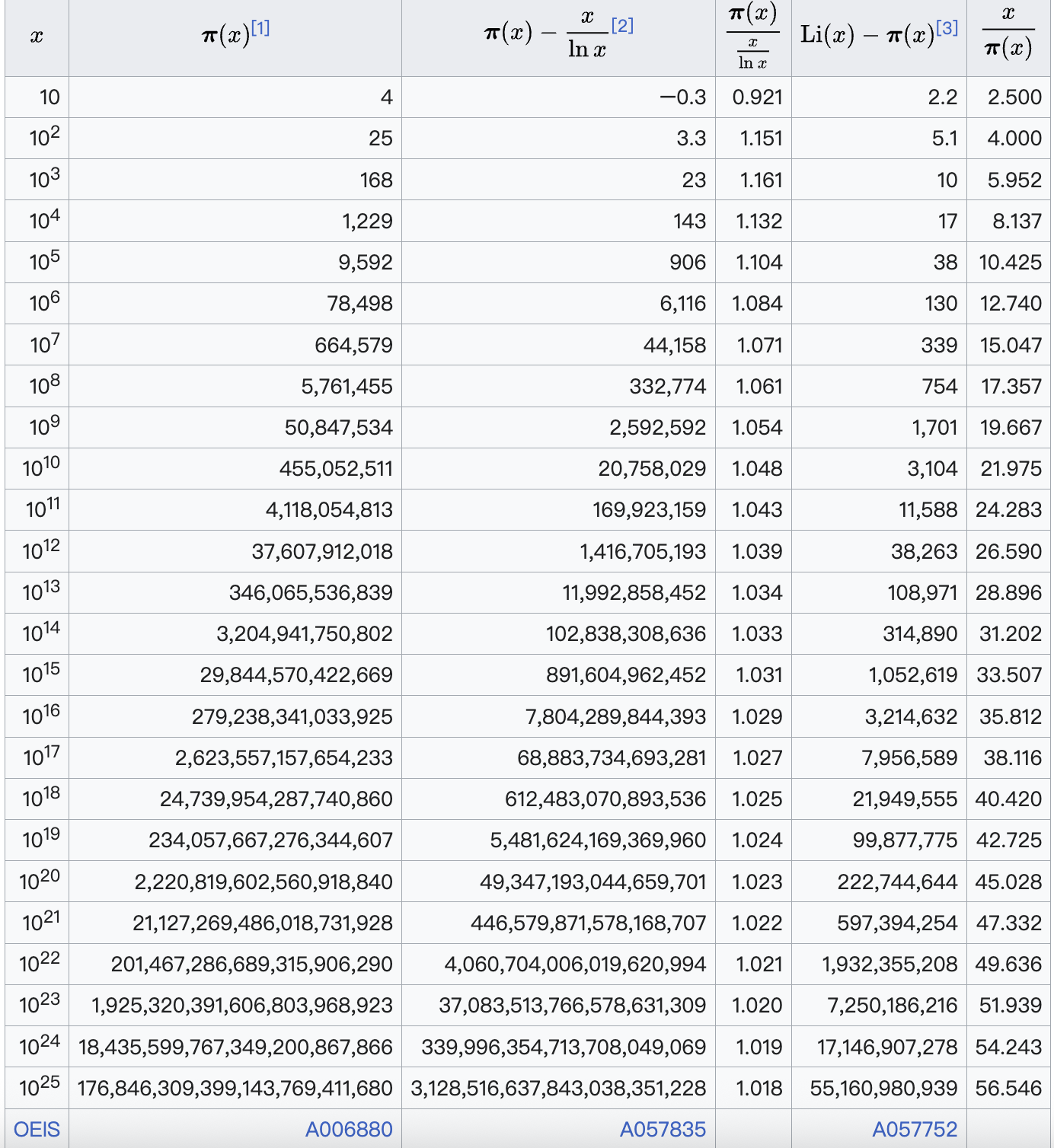
 ,其中
,其中  是对数积分函数,满足
是对数积分函数,满足  。
。 (对所有素数
(对所有素数  的
的  求和),则:
求和),则:  。定义
。定义  (其中
(其中  是冯·曼戈尔特函数,当
是冯·曼戈尔特函数,当  时
时  ,否则为 0),则:
,否则为 0),则: 
 时,
时, ,而
,而  ,比值约
,比值约  。
。 时,
时, ,
, ,比值约
,比值约  ,更接近 $ latex 1$。
,更接近 $ latex 1$。 的极限若存在必为
的极限若存在必为 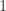 ,并给出上下界
,并给出上下界  。
。 。狄利克雷定理(算术级数中的素数分布)是素数定理在模
。狄利克雷定理(算术级数中的素数分布)是素数定理在模 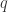 余
余  (
( )素数集上的推广。
)素数集上的推广。
 表示第 n 个素数,那么相邻素数的间距就是
表示第 n 个素数,那么相邻素数的间距就是  。当
。当  是正整数的时候,定义
是正整数的时候,定义  ,那么
,那么  就是孪生素数猜想。
就是孪生素数猜想。 ,存在无穷多对相邻素数,其差恰好为
,存在无穷多对相邻素数,其差恰好为  为所有孪生素数对
为所有孪生素数对  的集合,则其倒数和收敛:
的集合,则其倒数和收敛:  该级数的极限值称为 布鲁恩常数(Brun’s constant),记为
该级数的极限值称为 布鲁恩常数(Brun’s constant),记为  :
:  。
。 ),而孪生素数的倒数和收敛。这表明孪生素数比全体素数稀疏得多,即使孪生素数有无穷多对(孪生素数猜想尚未证明),其分布密度也足够低以保证倒数和有限。收敛性说明孪生素数的分布满足:
),而孪生素数的倒数和收敛。这表明孪生素数比全体素数稀疏得多,即使孪生素数有无穷多对(孪生素数猜想尚未证明),其分布密度也足够低以保证倒数和有限。收敛性说明孪生素数的分布满足:  , 即孪生素数的数量增长慢于
, 即孪生素数的数量增长慢于  (对比素数定理
(对比素数定理  的素数 p,p 既不整除 n,也不整除 n+2。则
的素数 p,p 既不整除 n,也不整除 n+2。则  。
。 ,其中 C为常数,具体推导利用容斥原理和不等式放缩(如切比雪夫边界)。
,其中 C为常数,具体推导利用容斥原理和不等式放缩(如切比雪夫边界)。 可得:
可得: 
 例如:当
例如:当 时,
时, ;当
;当 时,
时, 。针对收敛速度这个问题,因
。针对收敛速度这个问题,因  (
( 为孪生素数常数),级数收敛极慢,需极大
为孪生素数常数),级数收敛极慢,需极大 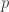 和
和  ,其差为2(即“k+1”)。在1966年,E. Bombieri与H. Davenport证明孪生素数密度上界:
,其差为2(即“k+1”)。在1966年,E. Bombieri与H. Davenport证明孪生素数密度上界: ,表明孪生素数分布稀疏,后人称之为Bombieri-Davenport上界。在1978年,中国数学家陈景润证明:存在无穷多对素数
,表明孪生素数分布稀疏,后人称之为Bombieri-Davenport上界。在1978年,中国数学家陈景润证明:存在无穷多对素数  ,其差不超过7000万(即
,其差不超过7000万(即  )。这一成果解决了弱哥德巴赫猜想的关键部分。
)。这一成果解决了弱哥德巴赫猜想的关键部分。 ,存在常数
,存在常数  ,使得无穷多对素数差不超过
,使得无穷多对素数差不超过  ,并探索广义孪生素数分布。
,并探索广义孪生素数分布。 )仍未完全证明,但246已是迄今最佳上界。
)仍未完全证明,但246已是迄今最佳上界。 ,即:
,即: 。
。 。
。 。
。 )。其结果长期未被超越,成为经典基准。
)。其结果长期未被超越,成为经典基准。 。
。 ,突破Rankin框架。
,突破Rankin框架。 (对应素数
(对应素数  )。上述渐进结果保证了间隔的无限增长,但具体数值依赖计算验证。素数大间距的发展历程体现了从初等证明到调和分析、组合数学的深度融合,尤其是2014年工作融合了多重数学工具,重塑了素数间隔的理论框架。
)。上述渐进结果保证了间隔的无限增长,但具体数值依赖计算验证。素数大间距的发展历程体现了从初等证明到调和分析、组合数学的深度融合,尤其是2014年工作融合了多重数学工具,重塑了素数间隔的理论框架。