
SRE
站点可靠性工程(Site Reliability Engineering,SRE)是由Google提出的一种将软件工程方法应用于运维问题的实践框架,旨在通过自动化、数据驱动和工程化手段提升系统的可靠性与效率。其核心思想是将传统运维任务转化为可编程、可扩展的软件问题,从而实现对大规模分布式系统的高效管理。
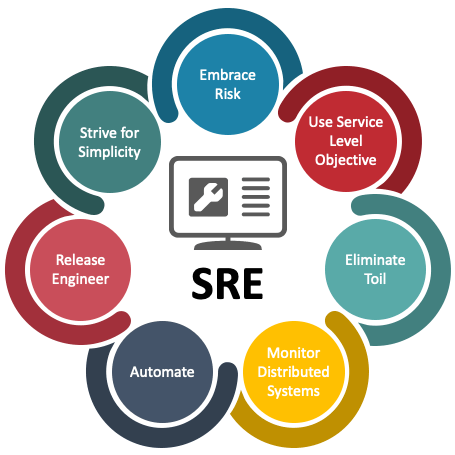
以下是SRE的核心概念和岗位职责:
SRE的定义与原则
- 工程化运维:SRE强调通过编写代码而非手动操作解决运维问题,例如自动化部署、监控和故障恢复。例如,Google的SRE团队通过自动化工具将重复性任务(如服务扩容)的耗时从小时级降至分钟级。
- 服务等级目标(SLO)驱动:SRE通过定义明确的SLO(如99.9%可用性)和错误预算(Error Budget)来平衡新功能开发与系统稳定性。当错误预算耗尽时,团队需优先修复可靠性问题而非发布新功能。
- 减少琐碎工作(Toil Elimination):SRE要求将工程师的重复性操作(如手动扩缩容)控制在50%以下,剩余时间投入长期项目(如架构优化)。例如,Google通过自动化将告警处理时间缩短了90%。
- 拥抱风险与快速迭代:SRE鼓励通过小规模、高频次的变更降低故障影响,结合灰度发布(Canary)和自动化回滚机制。

SRE的岗位职责
- 系统可靠性保障:设计并维护监控告警系统,确保及时响应故障。 制定灾难恢复计划,定期进行故障演练(如“Wheel of Misfortune”模拟故障场景)。
- 自动化与工具开发:开发工具替代人工操作,例如自动化部署流水线或自愈脚本。 案例:Google SRE团队通过自动化将数据库故障恢复时间从数小时缩短至分钟级。
- 性能优化与容量规划:分析系统瓶颈,优化资源利用率(如通过负载均衡减少冗余资源)。 预测流量增长并提前扩容,避免服务过载。
- 跨团队协作:与开发团队共同设计高可用架构,推动“生产就绪”标准(如混沌工程测试)。 通过标准化工具链(如统一监控平台)降低协作成本。
- 文化倡导:推行无责(Blameless)文化,通过事后复盘(Postmortem)系统性改进。 培训开发团队掌握基础运维技能,促进所有权共享(Shared Ownership)。
SRE通过工程化手段将运维转化为可扩展、可持续的实践,同时平衡创新与稳定性,是现代云原生系统可靠运行的关键角色。,它与传统运维的区别包括:
- 主动性:SRE通过预防性工程(如自动化测试)减少故障,而非被动响应。
- 技术深度:SRE需具备软件开发能力,例如用Go/Python编写运维工具。
- 目标对齐:SRE与产品团队共享错误预算,确保业务目标与技术决策一致。
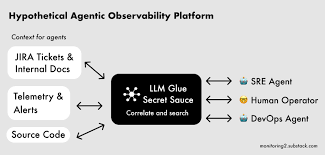
AI SRE Agent
随着数字化转型的加速和云原生技术的普及,现代系统的复杂性和规模呈指数级增长,传统SRE(站点可靠性工程)模式正面临巨大挑战。人工运维团队需要同时处理海量监控数据、多维度故障根因分析以及跨云环境的动态编排,这种高度依赖人工经验的响应方式已难以满足业务对”始终在线”的苛刻要求。在此背景下,AI SRE Agent的引入成为必然——它通过机器学习实时解析TB级日志和指标数据,以概率推理定位潜在故障点;利用强化学习算法自动优化告警阈值和响应策略,将MTTR(平均修复时间)缩短90%以上;更通过数字孪生技术模拟千万级并发场景,提前预测容量瓶颈。这种智能体不仅继承了SRE”工程化运维”的核心思想,更以AI的持续进化能力重构了可靠性管理的范式,使系统具备从”人工治愈”到”自愈”的质变可能。
AI SRE Agent(人工智能站点可靠性工程代理)是一种基于人工智能技术的自动化运维工具,旨在通过AI能力提升云环境或软件基础设施的可靠性、运维效率及事件响应速度,以下是其核心特点与功能:
1. 核心定义与目标
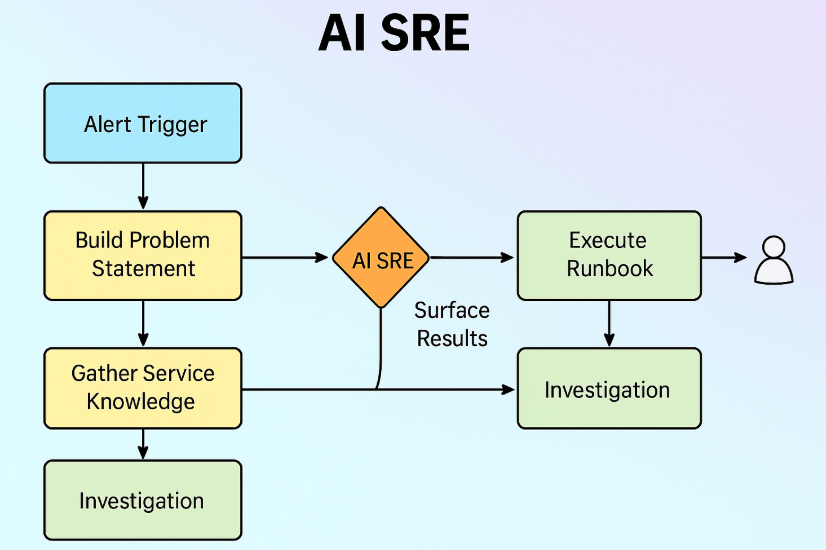
AI SRE Agent结合大型语言模型(LLM)的推理能力和自动化工具,模拟人类站点可靠性工程师(SRE)的工作流程,实现从监控到故障修复的闭环管理。其主要目标包括:
- 自动化根因分析(RCA):快速诊断生产环境问题的根本原因,将传统需数小时的RCA缩短至分钟级。
- 主动运维:通过持续学习资源状态和性能趋势,预测并预防潜在故障,而非被动响应。
- 减轻工程师负担:减少重复性任务(如日志分析、告警处理),让团队专注于创新性工作。
2. 关键技术能力
- 智能监控与告警处理:集成Azure Monitor、PagerDuty等工具,实时响应告警并自动触发调查流程,访问指标、日志和依赖关系以形成假设。
- 自动化修复操作:在用户授权下执行修复动作,如扩展资源、重启应用、回滚部署等。例如,Azure SRE Agent支持对Azure Kubernetes服务(AKS)的Pod重启和版本回滚。
- 安全与合规管理:持续审核资源是否符合安全实践(如TLS版本、托管身份启用),并自动修复漏洞。
- 开发者协作闭环:生成包含详细诊断信息的GitHub Issue,帮助开发者修复代码并防止问题复发。
3. 与传统SRE的差异
- 自主性与学习能力:AI代理通过知识图谱和多层级记忆管理积累系统上下文,逐步优化决策。例如,Cleric能通过历史事件推断Redis内存压力可能导致级联故障。
- 多工具协同:支持与Kubernetes、Datadog、Slack等平台集成,调用API执行跨系统操作。
- 实时性与规模:并行处理数千个信号,同时分析日志、指标和追踪数据,远超人工处理速度。
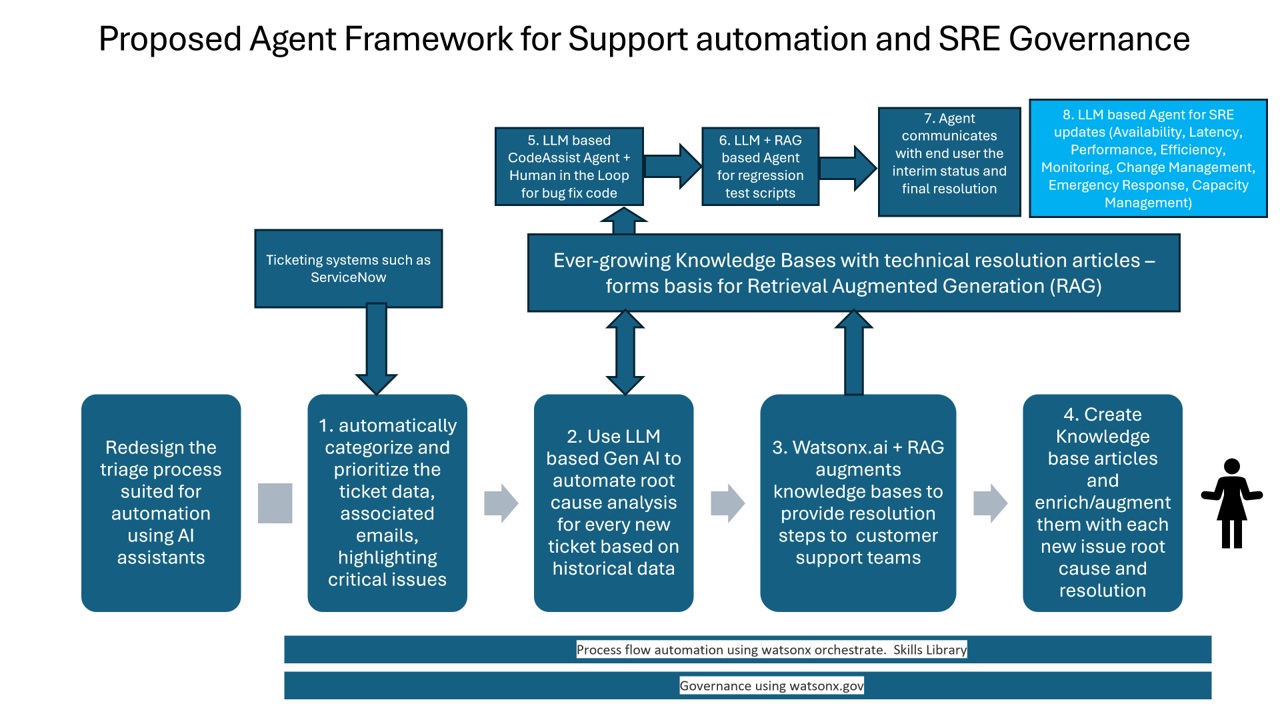
4. 典型应用场景
- 云服务管理:如微软Azure SRE Agent专为Azure资源设计,提供每日健康报告和自动化缓解措施。
- 混合环境优化:AgentSRE等方案支持跨多云和本地基础设施的统一监控与修复。
- 金融与高可用系统:在银行等高风险场景中,AI代理通过预测性维护减少宕机损失。
5. 挑战与限制
- 实时数据依赖:代理需持续获取最新系统状态,数据延迟可能导致误判。
- 信任建立:初期需人类审核关键操作(如资金交易),逐步扩大自治范围。
- 成本控制:大规模部署可能带来算力与存储开销,需平衡效率与资源消耗。
6. 未来方向
行业正从“辅助诊断”迈向“自主修复”,如Traversal等公司通过多代理协作将平均修复时间(MTTR)降低90%。同时,AI SRE框架逐渐扩展至安全、网络等领域,形成跨职能的智能运维生态。

SRE通过工程化重构了运维的底层逻辑,而AI SRE Agent进一步将其推向智能化与自动化。两者的结合不仅解决了规模与复杂度的瓶颈,更重新定义了可靠性管理的边界——从“稳定优先”到“预测自愈”,最终实现系统韧性的质变。AI SRE Agent代表了运维自动化向智能化演进的关键技术,通过AI驱动的决策与行动,显著提升系统可靠性并释放工程师生产力。

