
LlamaIndex入门
LlamaIndex简介
LlamaIndex(原名 GPT Index)是一个开源的 Python 库,其擅长简化大规模文本数据的索引、存储和查询操作。它将语言模型与文本数据的高效索引结合起来,使得开发者可以轻松地为复杂的文本信息检索和问答任务构建解决方案。通过构建倒排索引或向量索引,LlamaIndex 可以处理大量的文档,并为每个查询提供上下文感知的答案,显著提高了大规模数据的查询效率和准确性。它特别适用于法律、医学、科研、公司内部知识库等领域中需要处理和分析大量文本数据的场景。
LlamaIndex 不仅支持多种数据源,如文本文件、网页和数据库,还能够与先进的向量数据库(如 Milvus或者Pinecone)进行集成,进一步提升查询速度和准确度。通过与大语言模型(如 Ollama、DeepSeek等开源模型或者GPT的API等)结合使用,LlamaIndex能够在复杂的问答系统、自动摘要、个性化推荐等应用中提供强大的文本理解和推理能力。无论是建立企业内部的知识库,还是创建智能客服系统,LlamaIndex 都能有效地处理大量文档,并提供实时、精准的查询结果。
LlamaIndex的安装
LlamaIndex可以通过pip进行安装,其命令是
pip install llama-index
还可以通过源代码进行安装,首先用git clone 代码
git clone https://github.com/jerryjliu/llama_index.git
然后执行:pip install -e . 或者 pip install -r requirements.txt 就可以安装成功。
LlamaIndex的使用
在docs这个文件夹中放入team_structure.txt这个文件,该文件的内容如下所示:
B公司人力资源部(HR)负责公司的招聘、培训、员工关系管理、绩效考核等职能。人力资源部的组织架构分为三个主要小组:招聘组、培训组和员工关系组。
招聘组负责公司各类职位的招聘,筛选候选人,组织面试并安排入职培训。招聘组目前有5名成员,主要负责技术岗位和管理岗位的招聘。
培训组负责公司内部员工的职业发展培训,组织新员工培训、领导力培训和技能提升课程。培训组目前有3名成员,分别负责技术培训、软技能培训和高管培训。
员工关系组负责员工关系的维护,解决员工与公司之间的各类问题,组织公司文化活动,提升员工满意度。员工关系组目前有4名成员。
人力资源部总监为李晓红,负责整体管理,向公司CEO汇报。每月与各小组负责人召开一次会议,评估部门目标和完成情况。
招聘组负责所有岗位的招聘,包括技术岗位、市场岗位、财务岗位等。技术岗位的招聘由王刚负责,市场岗位招聘由张婷负责,财务岗位招聘由刘峰负责。
培训组目前在进行年度员工培训计划,2025年的重点是提升员工的领导力和跨部门协作能力。
员工关系组正在策划一项关于员工福利的提升项目,预计将在2025年初开始实施。
于是,一个简单的搜索功能可以用以下代码来实现,只输出Top2相似的结果。
代码说明:
- 文档加载:代码使用 SimpleDirectoryReader 从指定的文件夹(例如 docs)中加载文本文件。这些文本文件可以是任何格式的文本文件(如 .txt)。SimpleDirectoryReader 会自动扫描指定文件夹中的所有文件并加载其内容。
- 创建索引:使用 VectorStoreIndex.from_documents(documents) 将加载的文档转化为向量索引。我们还在构造索引时应用了 SentenceSplitter,用于将文档拆分成小块以便更高效的处理。
- 查询引擎:通过 index.as_query_engine() 创建一个查询引擎,可以在该引擎上执行查询并返回最相关的文档或文本块。
- 查询执行:代码通过 query_engine.query(query) 执行用户的查询,并返回与查询最相关的结果。在这个例子中,查询的是 “B公司人力资源部的组织架构是怎样的?”
- 输出:最后,代码会打印检索结果。
import logging
import sys
from llama_index.core import PromptTemplate, Settings, SimpleDirectoryReader, VectorStoreIndex
from llama_index.core.node_parser import SentenceSplitter
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
# Step 1 设置日志
# 设置日志记录的最小级别为 WARNING,避免输出 DEBUG 和 INFO 信息
logging.basicConfig(stream=sys.stdout, level=logging.WARNING) # 只输出 WARNING 及以上级别的日志
# 如果你只想屏蔽来自 llama_index 的日志,也可以使用下面的代码来禁用它
logging.getLogger("llama_index").setLevel(logging.WARNING) # 设置 llama_index 的日志级别为 WARNING
# Step 2 配置 LlamaIndex 使用本地的嵌入模型(可选)
Settings.llm = None
Settings.embed_model = HuggingFaceEmbedding(
model_name="/Users/avilazhang/PycharmProjects/models/BAAI/bge-large-zh-v1.5" # 使用 BGE 中文嵌入模型
)
# Step 3 定义文档路径,假设文档存储在名为 "docs" 的文件夹中
docs_directory = 'docs'
# Step 4 读取文档并构建索引
# 使用 SimpleDirectoryReader 读取文件夹中的所有文本文件
documents = SimpleDirectoryReader(docs_directory).load_data() # 读取 docs 文件夹中的所有 txt 文件
index = VectorStoreIndex.from_documents(documents, transformations=[SentenceSplitter(chunk_size=256)])
# Step 5 存储向量索引
index.storage_context.persist(persist_dir='doc_emb') # 保存向量索引到本地目录
# Step 6 构建查询引擎,搜索TopK。
query_engine = index.as_query_engine(similarity_top_k=2)
# Step 7 模拟用户查询并执行检索
query = "B公司招聘组负责什么内容?"
response = query_engine.query(query)
# Step 8 打印检索结果
print("检索结果:", response)
检索的结果如下图所示,只有两个文档信息,因为TopK的值等于2。

除此之外,LlamaIndex还支持在现有索引的基础上读取索引,并且新增索引。
RAG
RAG的整体流程
一个标准的RAG整体流程如下所示,可以从数据库、文档、API中获取数据并形成Index,然后query提问的时候可以通过Index获得相应的数据(relevant data),再把prompt、query和relevant data输入大模型,即可得到优化后的回答(response)。
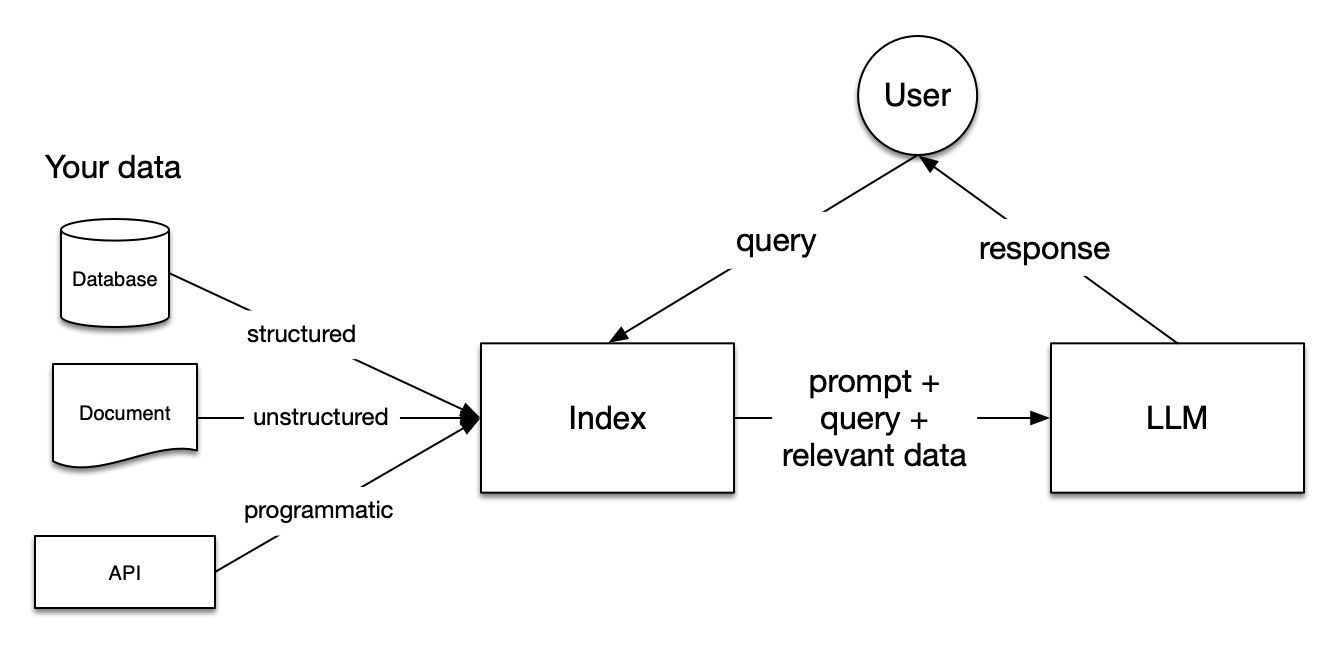
所以,RAG的主要阶段就包括载入、索引、存储、提问、评估。

Embedding模型
llama_index同样可以存储index,并且llama_index可以读取数据库、pdf、txt等类型文档。可以使用嵌入模型来做数据的嵌入工作,并且计算其数据之间的相似度。
from sentence_transformers import SentenceTransformer
# 模型的本地地址,可以使用以下命令来进行下载到本地的某个地址
# modelscope download --model BAAI/bge-large-zh-v1.5 --local_dir /Users/avilazhang/PycharmProjects/models/BAAI/bge-large-zh-v1.5
# 嵌入模型
embedding_models = '/Users/avilazhang/PycharmProjects/models/BAAI/bge-large-zh-v1.5'
# 方法一:
sentences_1 = ["样例数据-1", "样例数据-2"]
sentences_2 = ["样例数据-3", "样例数据-4"]
model = SentenceTransformer(embedding_models)
embeddings_1 = model.encode(sentences_1, normalize_embeddings=True)
embeddings_2 = model.encode(sentences_2, normalize_embeddings=True)
similarity = embeddings_1 @ embeddings_2.T
print(similarity)
# [[0.8553333 0.8520634 ]
# [0.87456274 0.8557937 ]]
# 方法二:
queries = ['query_1', 'query_2']
passages = ["样例文档-1", "样例文档-2"]
instruction = "为这个句子生成表示以用于检索相关文章:"
model = SentenceTransformer(embedding_models)
q_embeddings = model.encode([instruction+q for q in queries], normalize_embeddings=True)
p_embeddings = model.encode(passages, normalize_embeddings=True)
scores = q_embeddings @ p_embeddings.T
print(scores)
# [[0.3372506 0.20507795]
# [0.22591084 0.38495794]]
LlamaIndex与Ollama
用LlamaIndex和Ollama可以构建模型的RAG的知识库并输出:
import logging
import sys
from llama_index.core import PromptTemplate, Settings, SimpleDirectoryReader, VectorStoreIndex
from llama_index.core.node_parser import SentenceSplitter
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
import ollama
from llama_index.core import Document
# Step 1️⃣ 设置日志
# 设置日志记录的最小级别为 WARNING,避免输出 DEBUG 和 INFO 信息
logging.basicConfig(stream=sys.stdout, level=logging.WARNING) # 只输出 WARNING 及以上级别的日志
# 如果你只想屏蔽来自 llama_index 的日志,也可以使用下面的代码来禁用它
logging.getLogger("llama_index").setLevel(logging.WARNING) # 设置 llama_index 的日志级别为 WARNING
# Step 2️⃣ 定义 system prompt
SYSTEM_PROMPT = """You are a helpful AI assistant."""
query_wrapper_prompt = PromptTemplate(
"[INST]<<SYS>>\n" + SYSTEM_PROMPT + "<</SYS>>\n\n{query_str}[/INST] "
)
# Step 4️⃣ 配置 LlamaIndex 使用 BAAI/bge-base-zh-v1.5 作为嵌入模型
Settings.llm = None
Settings.embed_model = HuggingFaceEmbedding(
model_name="/Users/avilazhang/PycharmProjects/models/BAAI/bge-large-zh-v1.5" # 使用 BGE 中文嵌入模型
)
# Step 5️⃣ 定义 B公司人力资源部的组织架构及业务分工文档
docs = [
"B公司人力资源部(HR)负责公司的招聘、培训、员工关系管理、绩效考核等职能。人力资源部的组织架构分为三个主要小组:招聘组、培训组和员工关系组。",
"招聘组负责公司各类职位的招聘,筛选候选人,组织面试并安排入职培训。招聘组目前有5名成员,主要负责技术岗位和管理岗位的招聘。",
"培训组负责公司内部员工的职业发展培训,组织新员工培训、领导力培训和技能提升课程。培训组目前有3名成员,分别负责技术培训、软技能培训和高管培训。",
"员工关系组负责员工关系的维护,解决员工与公司之间的各类问题,组织公司文化活动,提升员工满意度。员工关系组目前有4名成员。",
"人力资源部总监为李晓红,负责整体管理,向公司CEO汇报。每月与各小组负责人召开一次会议,评估部门目标和完成情况。",
"招聘组负责所有岗位的招聘,包括技术岗位、市场岗位、财务岗位等。技术岗位的招聘由王刚负责,市场岗位招聘由张婷负责,财务岗位招聘由刘峰负责。",
"培训组目前在进行年度员工培训计划,2025年的重点是提升员工的领导力和跨部门协作能力。",
"员工关系组正在策划一项关于员工福利的提升项目,预计将在2025年初开始实施。"
]
# Step 6️⃣ 读取文档并构建索引
documents = [Document(text=doc) for doc in docs] # 将文档转化为 LlamaIndex 的文档对象
index = VectorStoreIndex.from_documents(documents, transformations=[SentenceSplitter(chunk_size=256)])
# Step 7️⃣ 存储向量索引
index.storage_context.persist(persist_dir='doc_emb') # 保存向量索引到本地目录
# Step 8️⃣ 构建查询引擎,搜索TopK。
query_engine = index.as_query_engine(similarity_top_k=5)
# Step 9️⃣ 模拟用户查询并执行检索
query = "B公司人力资源部的组织架构是怎样的?"
response = query_engine.query(query)
# Step 10️⃣ 打印检索结果
print("检索结果:", response)
# Step 11️⃣ 构造 Ollama 生成答案的 Prompt
prompt = f"""
请根据以下背景知识回答用户的问题:
【背景知识】
{response}
【问题】
{query}
【回答】
"""
# Step 12️⃣ 使用 Ollama DeepSeek-R1:32b 模型生成答案
print("🤖 正在生成回答...\n")
# 使用 Ollama 调用 DeepSeek-R1:32b 模型进行流式输出
stream = ollama.chat(
model="deepseek-r1:32b",
messages=[{"role": "user", "content": prompt}],
stream=True
)
# Step 13️⃣ 流式输出结果
response_buffer = ""
for chunk in stream:
delta = chunk.get("message", {}).get("content", "")
print(delta, end="", flush=True) # 实时输出
response_buffer += delta
# Step 14️⃣ # 能流式输出最终生成的答案
print("\n\n生成的答案:", response_buffer)

用多条数据查询之后得到以下结论:
| 查询 | 回答(来自 RAG + LLM) | 结论 |
| B公司人力资源部的组织架构是怎样的? | B公司的人力资源部负责公司的招聘、培训、员工关系管理以及绩效考核等职能。该部门的组织架构分为三个主要小组:招聘组、培训组和员工关系组。 1. 招聘组: 负责公司各类职位的招聘,包括技术岗位、市场岗位、财务岗位等。 招聘组目前有5名成员,分别由王刚负责技术岗位招聘,张婷负责市场岗位招聘,刘峰负责财务岗位招聘。 2. 培训组: 负责入职培训及其他类型的员工培训,提升员工的技能和工作表现。虽然背景信息中未详细说明该组的具体情况,但可以推断其在培养员工能力方面起着关键作用。 3. 员工关系组: 负责维护员工与公司之间的关系,解决各类问题,组织公司文化活动以提升员工满意度。 该组目前有4名成员,致力于促进积极的职场环境和增强团队凝聚力。 人力资源部的整体管理由总监李晓红负责,她定期召开会议评估部门目标的完成情况,并向公司CEO汇报。这种层级分明、分工明确的组织架构确保了人力资源各项职能的有效执行。 | 正确 |
| B公司人力资源部2025年有哪些任务? | B公司人力资源部在2025年的任务包括: 1. 年度员工培训计划:重点是提升员工的领导力和跨部门协作能力。这是由培训组负责的任务。 2. 员工福利提升项目:员工关系组正在策划并预计将在2025年初开始实施这一项目。 此外,虽然招聘组负责公司各类职位的招聘工作,但并未提到具体的2025年任务目标。人力资源部总监李晓红每月与各小组负责人召开会议,评估部门目标和完成情况,这也是其常规职责的一部分,但未特别指出为2025年的具体任务。 | 正确 |
| B公司人力资源部的招聘工作有哪些人在负责?我需要找到他们。 | B公司人力资源部的招聘工作由以下人员负责: 1. 王刚 – 负责技术岗位招聘 2. 张婷 – 负责市场岗位招聘 3. 刘峰 – 负责财务岗位招聘 这三位人员分别负责各自领域的招聘工作,如果您需要联系他们,可以按照上述信息进行。 | 正确 |
| 什么是生物学? | 根据提供的背景信息,未提及“生物学”的相关内容。如需了解生物学的定义,请参考可靠的科学资源或教科书。 | 不太好,需要修改Prompt |
| 网络监控是什么? | 网络监控是指通过各种技术和工具持续监测计算机网络的状态和活动,以便及时发现并解决潜在的安全威胁、性能问题或异常行为。其主要目的是确保网络安全、优化网络性能、预防未经授权的访问,并在出现问题时快速响应。 网络监控通常包括以下方面:1. 流量分析:监控数据流量以检测异常模式或潜在攻击。2. 入侵检测和防御:使用防火墙、入侵检测系统(IDS)等工具防止未经授权的访问。3. 性能管理:优化网络资源分配,确保服务质量和高可用性。4. 日志记录与分析:跟踪网络活动,便于审计和故障排查。 这些措施帮助企业保护敏感数据,维护业务连续性和客户信任。 | 正确 |
| 请介绍下数学分析有哪些内容? | 根据提供的背景信息,数学分析的具体内容并未被提及。背景信息主要涉及公司人力资源部的组织结构和职责,包括招聘组、培训组和员工关系组的工作内容。如果您有关于数学分析的具体问题或需要其他帮助,请提供更多相关信息,我会尽力为您解答。 | 不太好,需要修改Prompt |
参考资料
- LlamaIndex:https://docs.llamaindex.ai/en/stable/
- GitHub链接:https://github.com/run-llama/llama_index
- 魔搭社区的嵌入模型:https://www.modelscope.cn/models/BAAI/bge-large-zh-v1.5/summary
- LlamaIndex中文文档:LlamaIndex 🦙 0.6.18
- Pinecore文档工具:Pinecone Database – Pinecone Docs
