Ollama的介绍 Ollama 是一款强大的人工智能语言大模型(LLM)平台,专注于为开发者和企业提供高效、可定制的文本生成和自然语言处理能力。通过集成先进的深度学习技术,Ollama 能够在本地 帮助用户生成高质量的文章、解答复杂问题、提供自动化客服支持等。无论是内容创作、数据分析,还是智能客服系统,Ollama 都能提供灵活的解决方案,并支持跨平台应用。凭借其易用的接口、快速的响应速度和强大的定制化功能,Ollama 已成为越来越多开发者和企业的首选工具,为他们在复杂任务中提供智能化的辅助和支持。
Ollama的入门 在GitHub的官网上,可以找到Ollama的链接是:https://github.com/ollama/ollama 。同时,它可以支持MAC、Windows、Linux的使用,并且Linux的下载和安装命令如下:
curl -fsSL https://ollama.com/install.sh | sh
除此之外,Ollama还支持通过Docker的方式进行部署。在使用Ollama的之前,需要将其安装在电脑上,根据不同的操作系统,可以选择不同的安装方式。
下载与安装 Windows系统 打开浏览器,访问 Ollama 官方网站:https://ollama.com/download ,下载适用于 Windows 的安装程序。下载地址为:https://ollama.com/download/OllamaSetup.exe 。下载完成后,双击安装程序并按照提示完成安装。打开命令提示符或 PowerShell,输入以下命令验证安装是否成功:
如果上述命令显示版本号,则表示安装成功。
Mac系统 打开浏览器,访问 Ollama 官方网站:https://ollama.com/download ,下载适用于 macOS 的安装程序。下载地址为:https://ollama.com/download/Ollama-darwin.zip 。下载完成后,双击安装包并按照提示完成安装。安装完成后,通过以下命令验证:
如果上述命令显示版本号,例如ollama version is 0.6.5,则表示安装成功。如果显示zsh: command not found: ollama,则表示没有安装成功。
Linux系统 在Linux系统上,可以一键安装ollama,输入以下命令即可:
curl -fsSL https://ollama.com/install.sh | bash
安装完成后,通过以下命令验证:
如果上述命令显示版本号,则表示安装成功。
部分模型 在GitHub的官网上,我们可以看到Ollama可以支持和下载的模型种类是非常多的,包括Gemma、DeepSeek、Llama、LLaVA等,并且不同的大小也可以通过参数来进行选择。通常来说,模型的参数越多,模型的大小也就越大。更全的模型库可以参考链接:https://ollama.com/library 。
模型 参数 大小 下载 并运行 Gemma 3 1B 815MB ollama run gemma3:1b Gemma 3 4B 3.3GB ollama run gemma3 Gemma 3 12B 8.1GB ollama run gemma3:12b Gemma 3 27B 17GB ollama run gemma3:27b QwQ 32B 20GB ollama run qwq DeepSeek-R1 7B 4.7GB ollama run deepseek-r1 DeepSeek-R1 671B 404GB ollama run deepseek-r1:671b Llama 3.3 70B 43GB ollama run llama3.3 Llama 3.2 3B 2.0GB ollama run llama3.2 Llama 3.2 1B 1.3GB ollama run llama3.2:1b Llama 3.2 Vision 11B 7.9GB ollama run llama3.2-vision Llama 3.2 Vision 90B 55GB ollama run llama3.2-vision:90b Llama 3.1 8B 4.7GB ollama run llama3.1 Llama 3.1 405B 231GB ollama run llama3.1:405b Phi 4 14B 9.1GB ollama run phi4 Phi 4 Mini 3.8B 2.5GB ollama run phi4-mini Mistral 7B 4.1GB ollama run mistral Moondream 2 1.4B 829MB ollama run moondream Neural Chat 7B 4.1GB ollama run neural-chat Starling 7B 4.1GB ollama run starling-lm Code Llama 7B 3.8GB ollama run codellama Llama 2 Uncensored 7B 3.8GB ollama run llama2-uncensored LLaVA 7B 4.5GB ollama run llava Granite-3.2 8B 4.9GB ollama run granite3.2
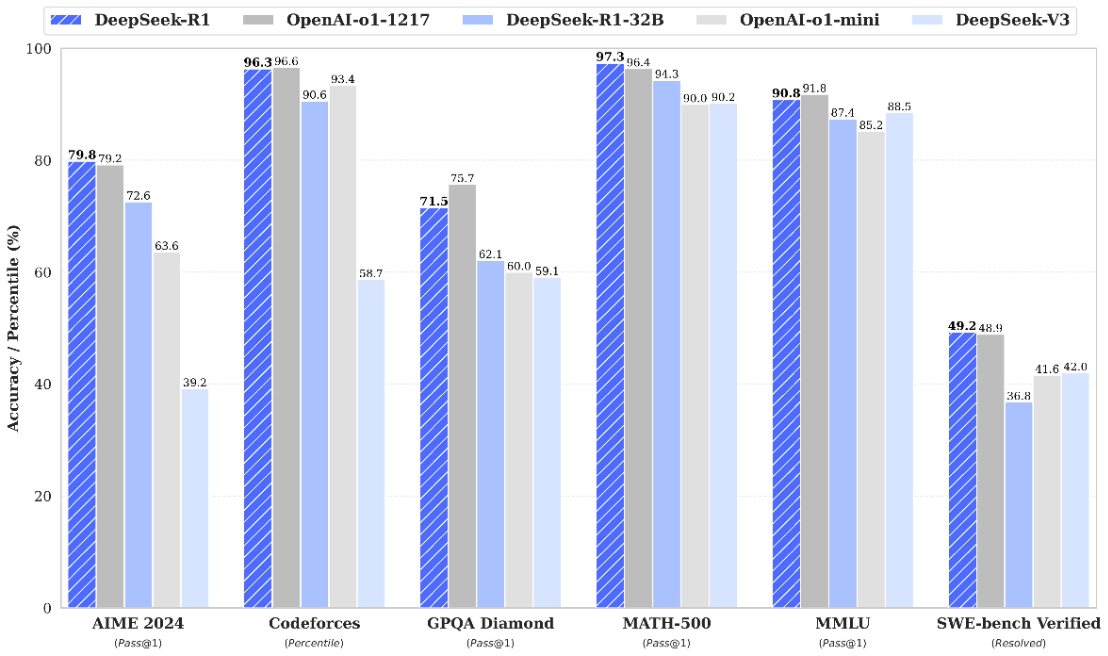
DeepSeek-r1会有不同的模型参数和大小,最少的模型参数是1.5b,最大的模型参数是671b。这些可以在Ollama的官网上找到,并且可以基于本地电脑的配置下载到本地电脑进行运行。在运行模型的时候,请注意mac的内存情况,以及参考Ollama官方提供的建议:You should have at least 8 GB of RAM available to run the 7B models, 16 GB to run the 13B models, and 32 GB to run the 33B models.
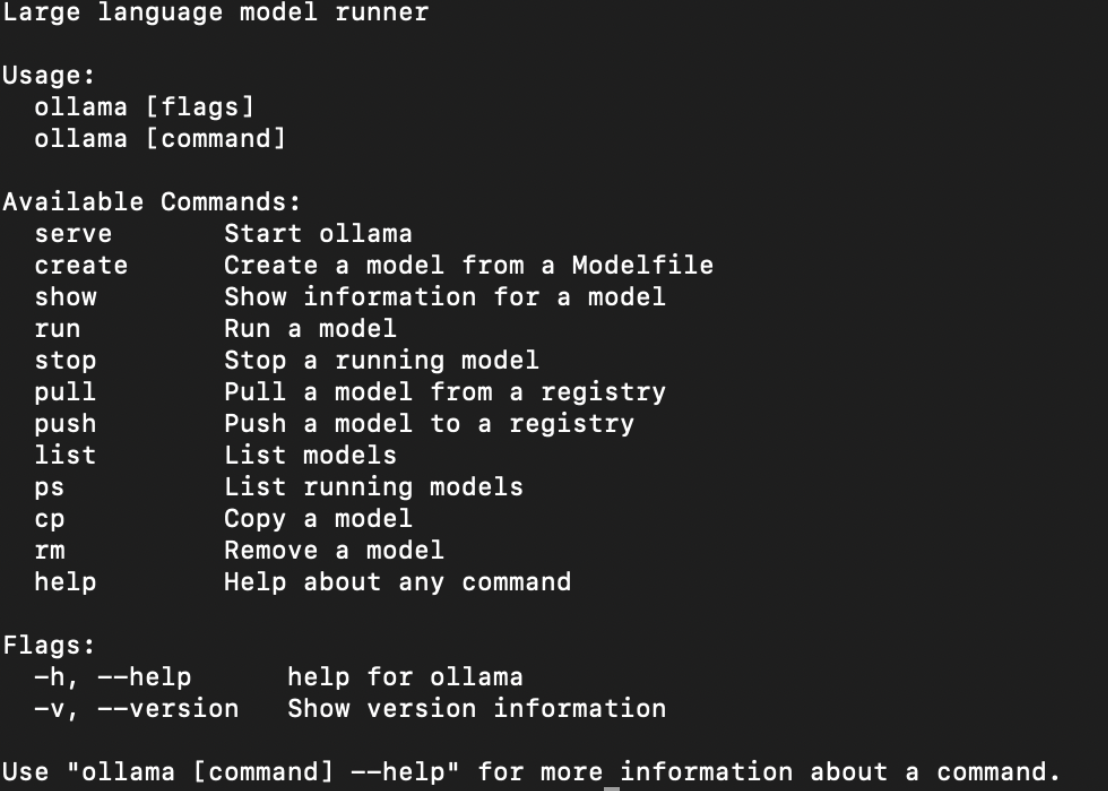
Ollama的使用 模型下载 使用帮助命令可以查到ollama的常见命令如下:
目前以操作deepseek-r1:7b模型为例,当你只需要下载模型的时候,需要使用命令:
ollama pull deepseek-r1:7b
当你需要下载模型并且运行的时候,需要使用命令,同时就会进入对话功能,正常的使用即可。退出的时候可以使用ctrl+d或者/bye即可。
ollama run deepseek-r1:7b
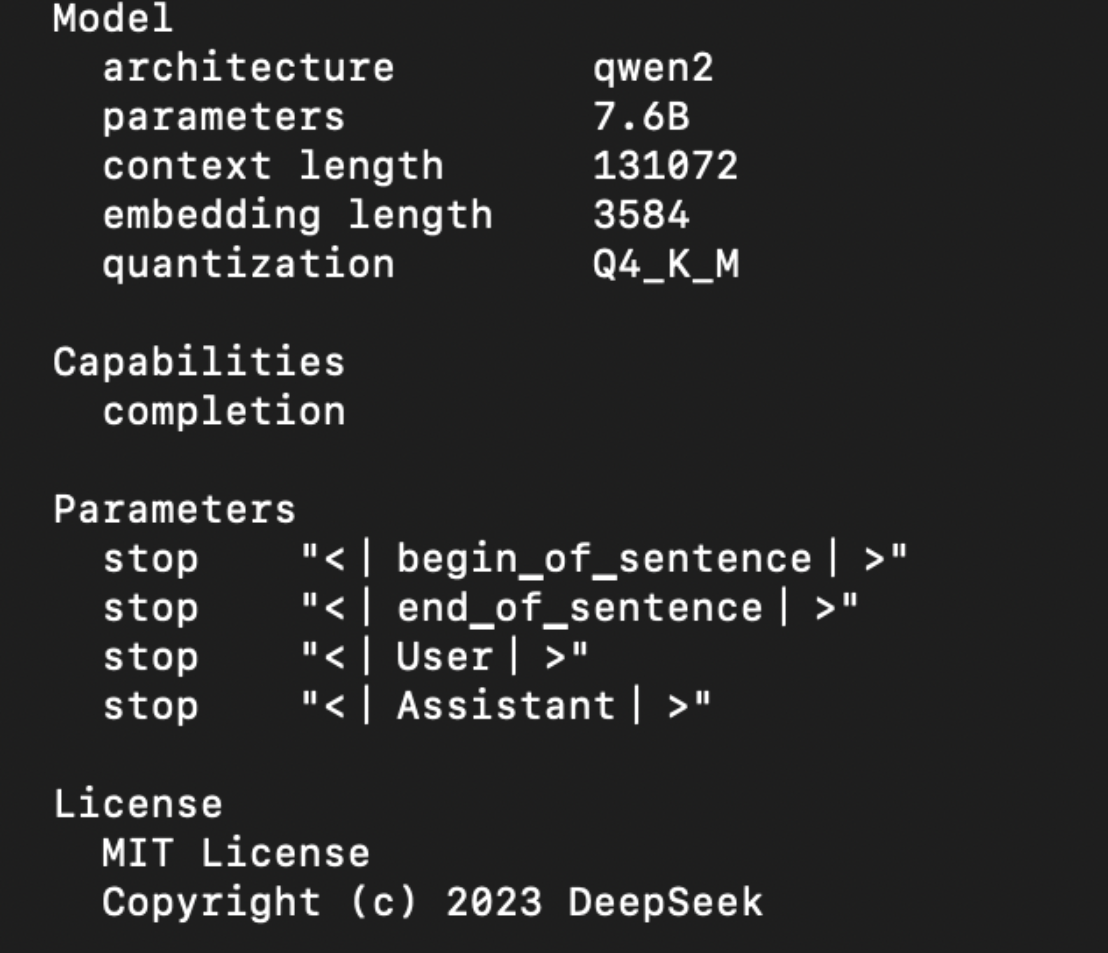
如果想查看该模型的细节,可以用show命令进行展示。
ollama show deepseek-r1:7b
当你想查看Ollama安装了多少大模型的时候,可以使用命令:
在mac上执行ollama serve,会出现Error: listen tcp 127.0.0.1:11434: bind: address already in use的错误。原因是:Mac安装Ollama后,启动Ollama后会本地监听本地TCP的11434端口,但这个监听仅仅是本地层面的监听,无法被本地以外的主机访问,也就是无法被同网段的主机访问。如果其他主机需要访问的话,需要采用docker部署的方式,重新修改一个新的端口即可,同时对外开放相应的端口。
模型交互 命令行交互 在mac上启动命令行,可以将模型直接启动起来,进入对话模式。
ollama run deepseek-r1:7b
在交互模式下,输入/bye或按下Ctrl+d退出即可。
单次命令交互 通过管道将输入传递给相应的模型,模型进行输出,例如输入“什么是数学?”就可以用以下命令:
echo "什么是数学?" | ollama run deepseek-r1:7b
使用命令行参数 甚至还可以直接在命令行中传递输入以下内容,直接获得结果。
ollama run deepseek-r1:7b "撰写一份周报的模板"
使用文件交互,例如有一个文件是input_text_1.txt,内容是“什么是化学?”,那么通过这个符号<以及路径和文件就可以输入给模型,并且得到输出的结果。
ollama run deepseek-r1:7b </Users/zr9558/Documents/Datasets/text/input_text_1.txt
自定义提示词 通过 Modelfile 定义自定义提示词或系统指令,使模型在交互中遵循特定规则。创建自定义模型,编写一个 Modelfile:
FROM deepseek-r1:7b SYSTEM "你是一个编程助手,专门帮助用户编写代码。"
创建自定义模型:
ollama create runoob-model -f ./Modelfile
运行自定义模型:
发送请求交互 通过curl命令可以看到当前端口启动的模型:
curl http://localhost:11434/api/tags
通过curl命令和相应的参数配置,可以实现发送请求给本地mac启动的模型。
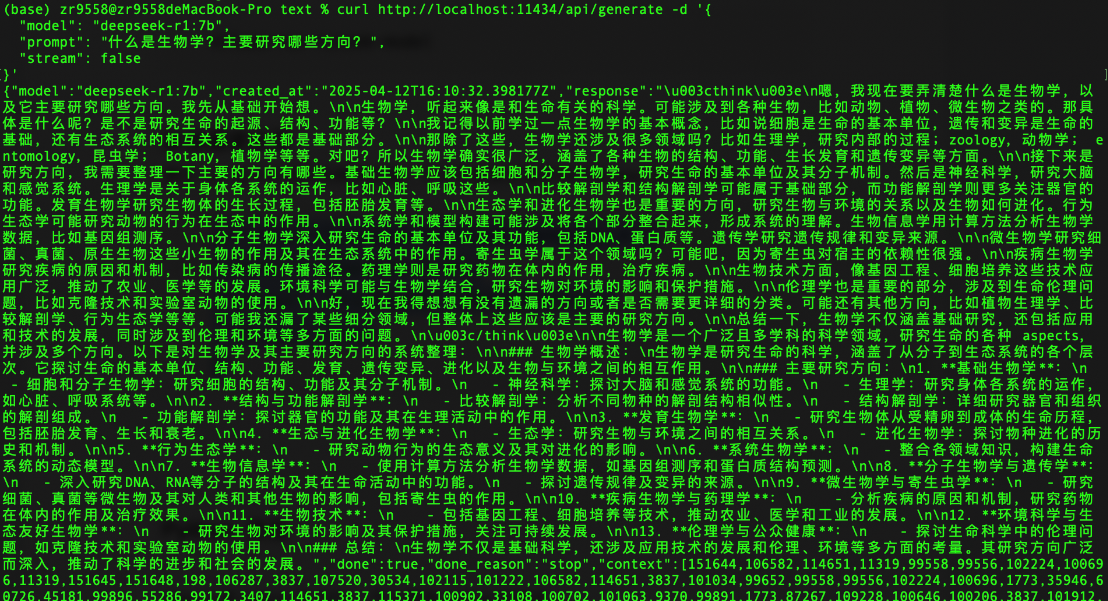
curl http://localhost:11434/api/generate -d '{
"model": "deepseek-r1:7b",
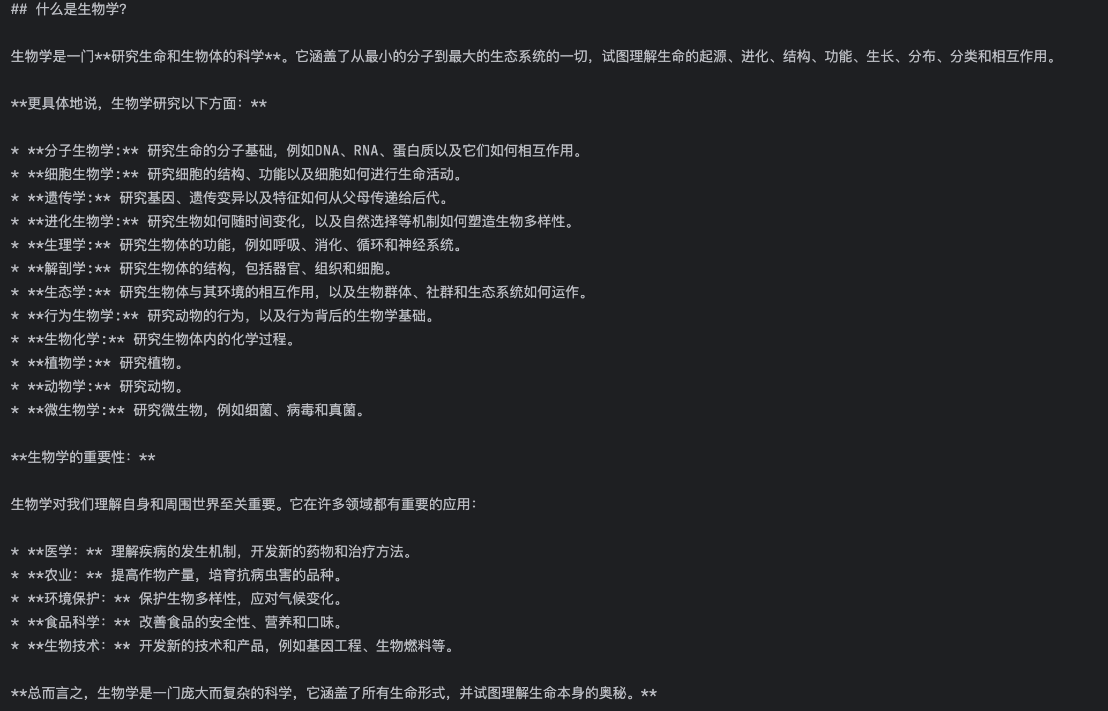
"prompt": "什么是生物学?主要研究哪些方向?",
"stream": false
}'
还可以增加更为复杂的参数进行curl请求,其中options里面就是模型的参数选择。
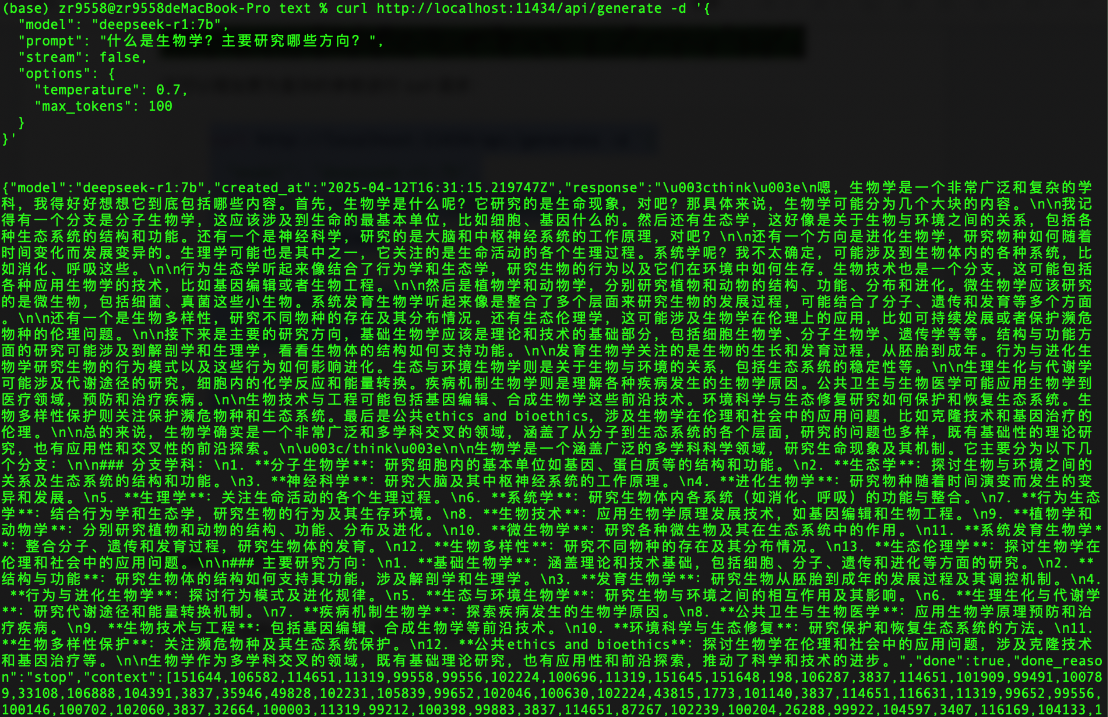
curl http://localhost:11434/api/generate -d '{
"model": "deepseek-r1:7b",
"prompt": "什么是生物学?主要研究哪些方向?",
"stream": false,
"options": {
"temperature": 0.7,
"max_tokens": 100
}
}'
如果选择stream是true,则用流式进行输出,那么则是逐行输出,每一行的输出是就是词语或者汉字字符,把每一行的response汇总到一起就是最终的输出。
curl http://localhost:11434/api/generate -d '{
"model": "gemma3:27b",
"prompt": "用一句话介绍数学是什么?",
"stream": true
}'
Python 交互 ollama提供了多种方式与Python代码进行交互,包括request,ollama SDK等。
requests 交互 可以直接使用Python的requests模块发送请求,并获得相应的结果。
import requests
# 生成文本
response = requests.post(
"http://localhost:11434/api/generate",
json={
"model": "gemma3:27b",
"prompt": "用一句话介绍什么是线性代数",
"stream": False
}
)
print(response.json())
另外,还可以这样去写代码:
import requests
response = requests.post(
"http://localhost:11434/api/chat",
json={
"model": "gemma3:27b",
"messages": [
{
"role": "user",
"content": "用一句话描述什么是实变函数"
}
],
"stream": False
}
)
print(response.json())
Ollama 交互 Ollama有python的SDK,可以使用python的版本,其GitHub源码链接是https://github.com/ollama/ollama-python 。使用pip就可以完成安装:
然后在Mac的PyCharm中使用以下代码,就可以发送请求给模型,进行结果的一次性返回:
from ollama import chat
from ollama import ChatResponse
response: ChatResponse = chat(model='gemma3:27b', messages=[
{
'role': 'user',
'content': '用一句话介绍什么是泛函分析',
},
])
# 打印响应内容
print(response['message']['content'])
print('-'*40)
# 或者直接访问响应对象的字段
print(response.message.content)
如果要做流式输出,则可以采用以下方法:
from ollama import chat
stream = chat(
model='deepseek-r1:32b',
messages=[{'role': 'user', 'content': '什么是数学分析?'}],
stream=True,
)
# 逐块打印响应内容
for chunk in stream:
print(chunk['message']['content'], end='', flush=True)
ollama的chat 方法可以与模型进行对话生成,发送用户消息并获取模型响应:
import ollama
print(ollama.chat(model='gemma3:27b', messages=[{'role': 'user', 'content': '用一句话介绍:数学中的动力系统是什么?'}]))
输出以下内容:
model=’gemma3:27b’ created_at=’2025-04-15T02:56:36.041842Z’ done=True done_reason=’stop’ total_duration=3464291750 load_duration=48093500 prompt_eval_count=20 prompt_eval_duration=433924792 eval_count=22 eval_duration=2981754125 message=Message(role=’assistant’, content=’数学中的动力系统研究的是随时间变化的系统,尤其是系统状态如何随时间演变。\n’, images=None, tool_calls=None)
如果只需要输出message中content 的部分,则可以这样修改代码:
import ollama
print(ollama.chat(model='gemma3:27b', messages=[{'role': 'user', 'content': '用一句话介绍:数学中的动力系统是什么?'}]).message.content)
ollama的generate方法用于文本生成任务。与chat方法类似,但是它只需要一个prompt参数。同时,如果只需要查看response的时候,就可以参考以下代码:
import ollama
print(ollama.generate(model='gemma3:27b', prompt='用一句话介绍:数学中的常微分方程是什么?'))
print(ollama.generate(model='gemma3:27b', prompt='用一句话介绍:数学中的常微分方程是什么?').response)
ollama的list方法可以列出所有可用的模型:
import ollama print(ollama.list())
ollama的show方法可以显示指定模型的详细信息:
import ollama print(ollama.show('deepseek-r1:32b'))
ollama的embed方法可以输出文本嵌入:
import ollama
print(ollama.embed(model='deepseek-r1:32b', input='The sky is blue because of rayleigh scattering'))
print(ollama.embed(model='deepseek-r1:32b', input='The sky is blue because of rayleigh scattering').embeddings)
另外,ollama还有create(创建新模型)、copy(复制)、delete(删除)、pull(拉取)、push(推送到远端)等常用的方法。另外,还可以使用ps命令查看运行的模型:
import ollama
print(ollama.ps())
客户端 还可以创建自定义客户端,来进一步控制请求配置,比如设置自定义的 headers 或指定本地服务的 URL。通过 Client,用户可以自定义请求的设置(如请求头、URL 等),并发送请求。
from ollama import Client
client = Client(
host='http://localhost:11434',
headers={'x-some-header': 'some-value'}
)
response = client.chat(model='gemma3:27b', messages=[
{
'role': 'user',
'content': '什么是生物学',
},
])
print(response['message']['content'])
如果用户希望异步执行请求,可以使用AsyncClient类,适用于需要并发的场景。异步客户端支持与传统的同步请求一样的功能,唯一的区别是请求是异步执行的,可以提高性能,尤其是在高并发场景下。
import asyncio
from ollama import AsyncClient
async def chat():
message = {'role': 'user', 'content': '用简单的语句描述工作中的日报有哪些内容?'}
response = await AsyncClient().chat(model='gemma3:27b', messages=[message])
print(response['message']['content'])
asyncio.run(chat())
如果用户需要异步地处理流式响应,可以通过将stream=True设置为异步生成器来实现。
import asyncio
from ollama import AsyncClient
async def chat():
message = {'role': 'user', 'content': '用简单的语句描述工作中的日报有哪些内容?'}
async for part in await AsyncClient().chat(model='gemma3:27b', messages=[message], stream=True):
print(part['message']['content'], end='', flush=True)
asyncio.run(chat())
文章总结 Ollama 是一个本地大模型运行框架,致力于让开发者在个人设备上快速部署和使用各类开源大语言模型(如 LLaMA、Mistral、Gemma、DeepSeek等)。它通过极简的 CLI 命令(如 ollama run llama3),帮助用户在无需复杂环境配置的情况下,一键拉起本地模型。Ollama 提供了统一的模型管理、会话API和内存管理机制,是开发者测试、原型开发、本地私有化部署的理想工具,也适合作为RAG、Agent框架中的模型后端接入点。
参考资料
官网链接:https://ollama.com ,https://ollama.org.cn
GitHub地址:https://github.com/ollama/ollama
Ollama中文文档:https://ollama.readthedocs.io/quickstart/
Ollama教程:https://www.runoob.com/ollama/ollama-tutorial.html
Ollama中文文档:https://ollama.readthedocs.io
LlamaFactory:https://www.llamafactory.cn