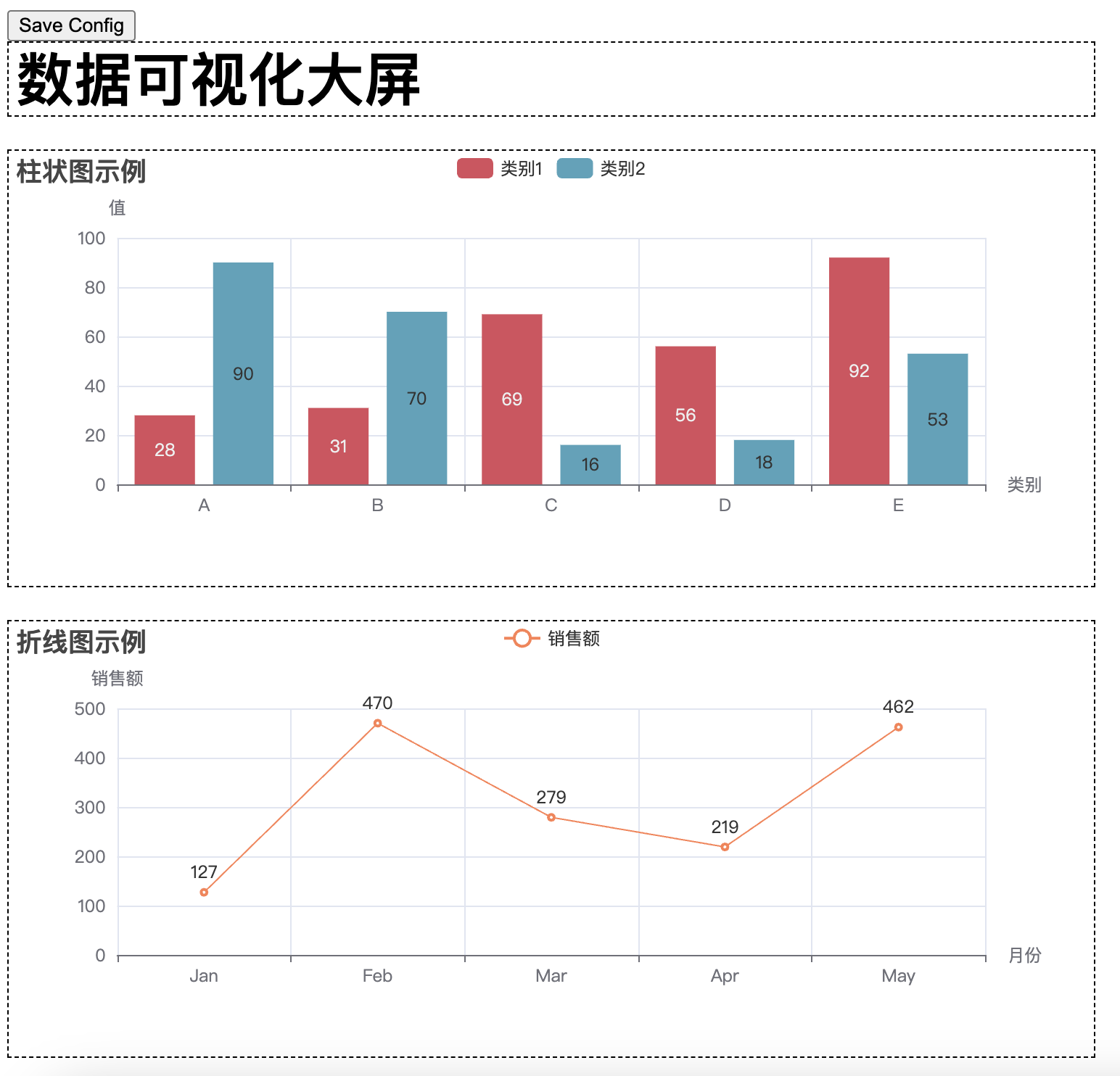
当我们掌握了各种图表的基本使用方法后,接下来一个非常重要的任务就是将这些图表有效地集成到网页中,展示数据的可视化效果。Pyecharts 提供了非常方便的功能,让我们能够将图表生成 HTML 文件,并嵌入到网页中进行展示。通过将图表集成到网页,用户不仅能够与数据进行互动,还能够获得更加直观、动态的展示效果。
在接下来的内容中,我们将详细介绍如何将多个图表(如柱状图、折线图、散点图等)融合到一个网页中,并通过 HTML 和 JavaScript 来增强页面的交互性和用户体验。通过这种方式,你可以将不同类型的图表展示在同一页面上,利用 Pyecharts 提供的丰富配置选项,轻松实现数据可视化的多样性和灵活性。
from pyecharts.charts import Bar, Line, Pie, Scatter, Page
from pyecharts import options as opts
import random
# 创建柱状图
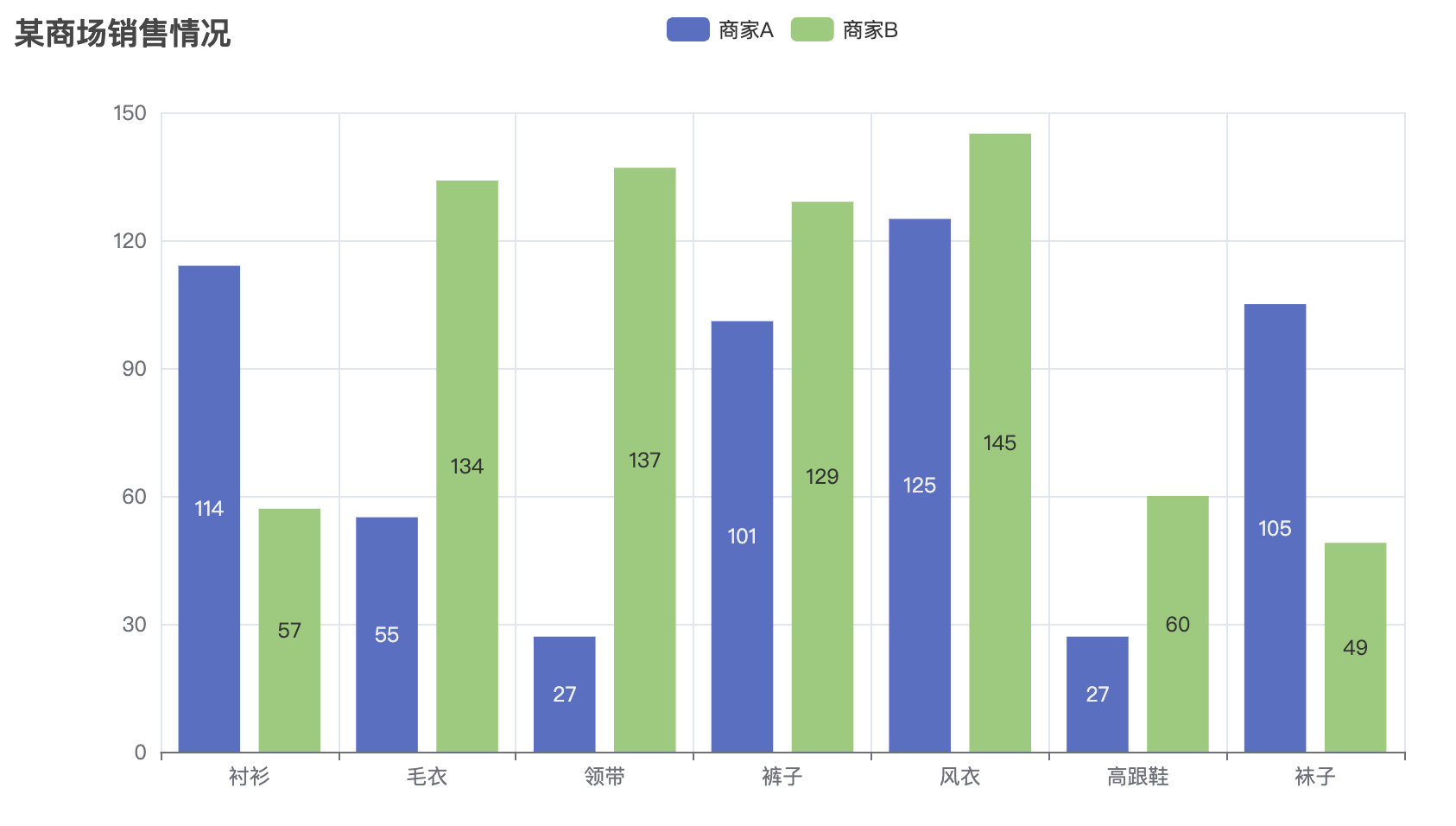
bar = Bar()
bar.add_xaxis(["A", "B", "C", "D", "E"])
bar.add_yaxis("类别1", [random.randint(10, 100) for _ in range(5)], color="#d94e5d")
bar.add_yaxis("类别2", [random.randint(10, 100) for _ in range(5)], color="#50a3ba")
bar.set_global_opts(
title_opts=opts.TitleOpts(title="柱状图示例"),
xaxis_opts=opts.AxisOpts(name="类别"),
yaxis_opts=opts.AxisOpts(name="值"),
)
# 创建折线图
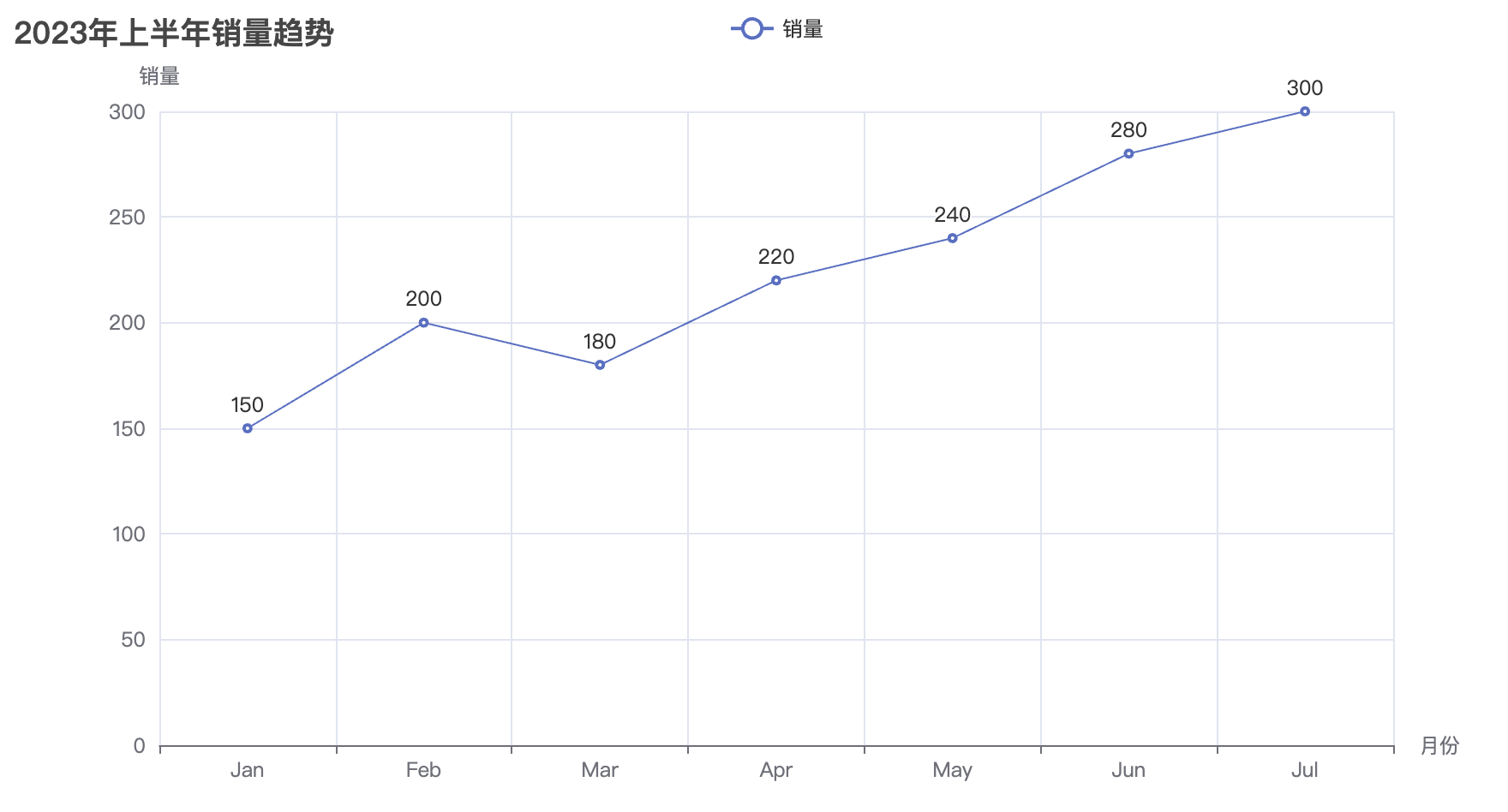
line = Line()
line.add_xaxis(["Jan", "Feb", "Mar", "Apr", "May"])
line.add_yaxis("销售额", [random.randint(100, 500) for _ in range(5)], color="#ff7f50")
line.set_global_opts(
title_opts=opts.TitleOpts(title="折线图示例"),
xaxis_opts=opts.AxisOpts(name="月份"),
yaxis_opts=opts.AxisOpts(name="销售额"),
)
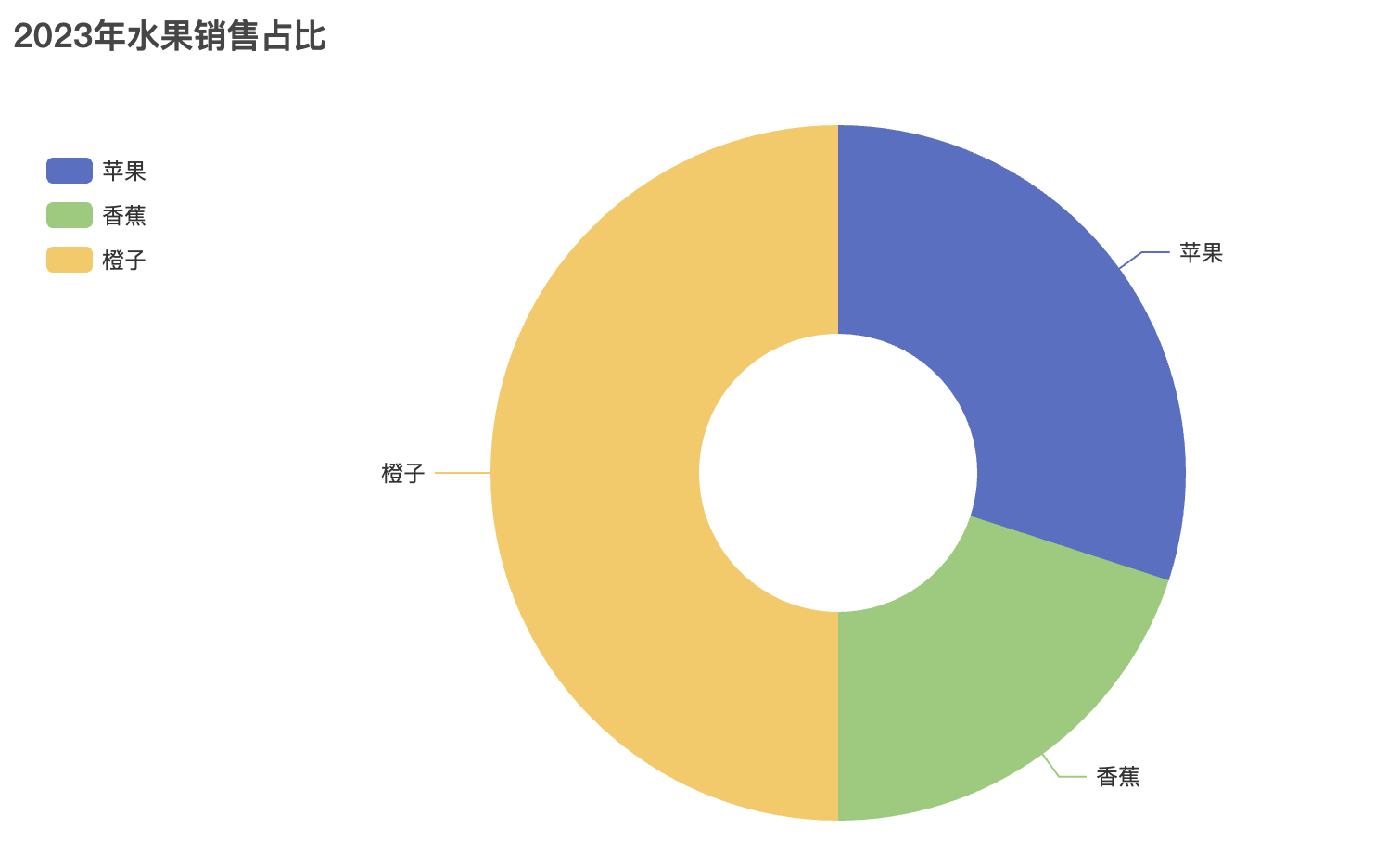
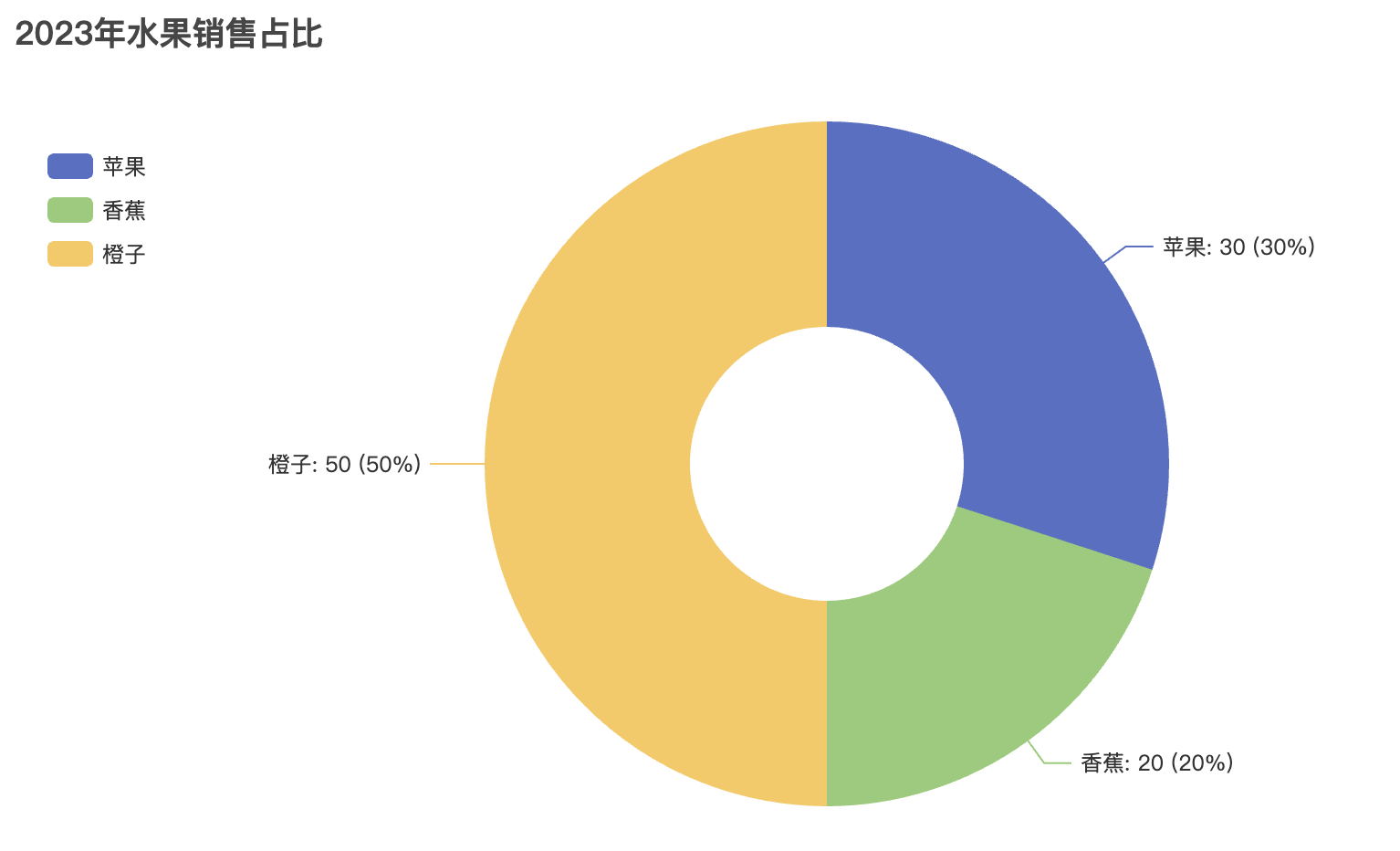
# 创建饼图
pie = Pie()
pie.add("产品占比", [("产品A", 40), ("产品B", 30), ("产品C", 20), ("产品D", 10)])
pie.set_global_opts(title_opts=opts.TitleOpts(title="饼图示例"))
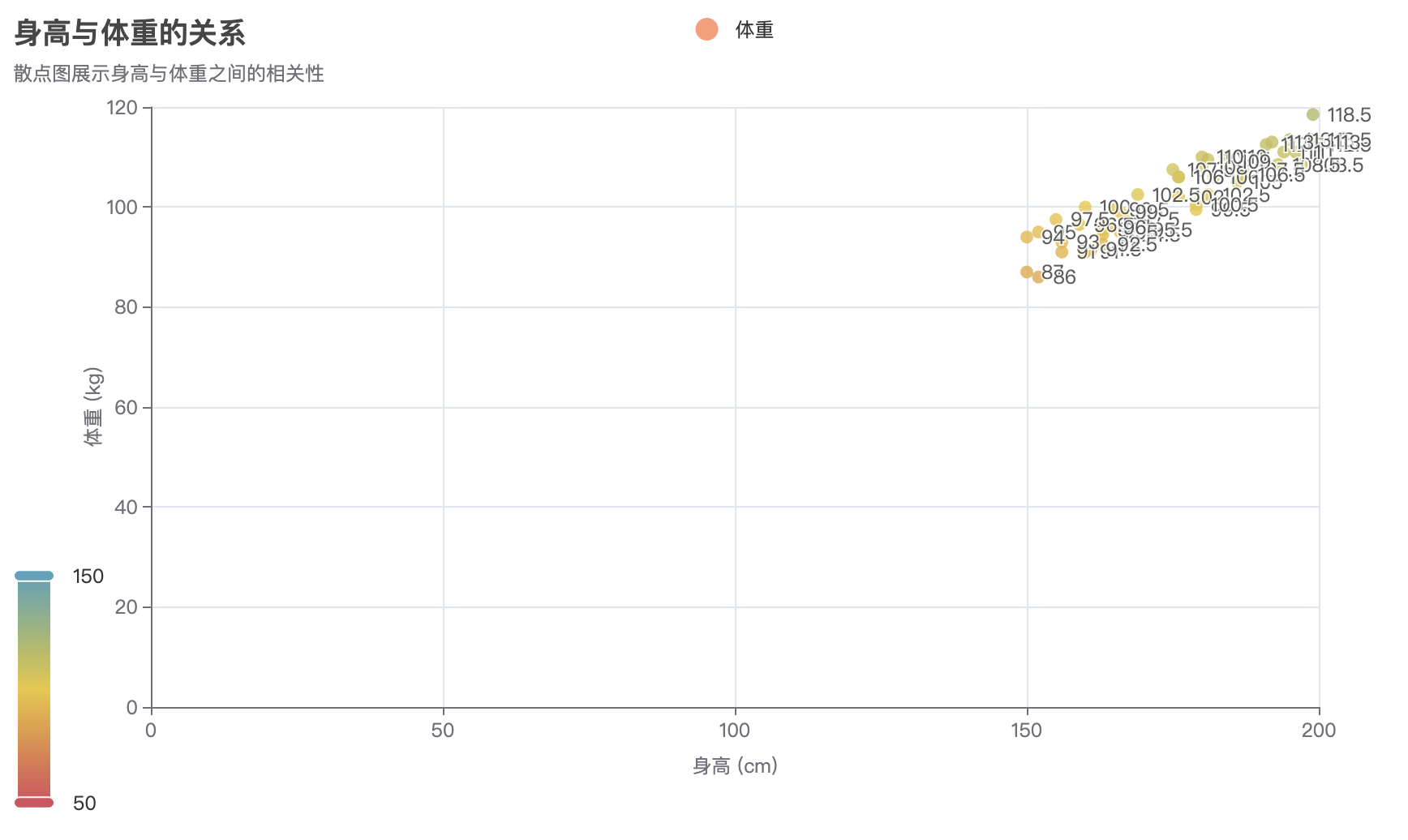
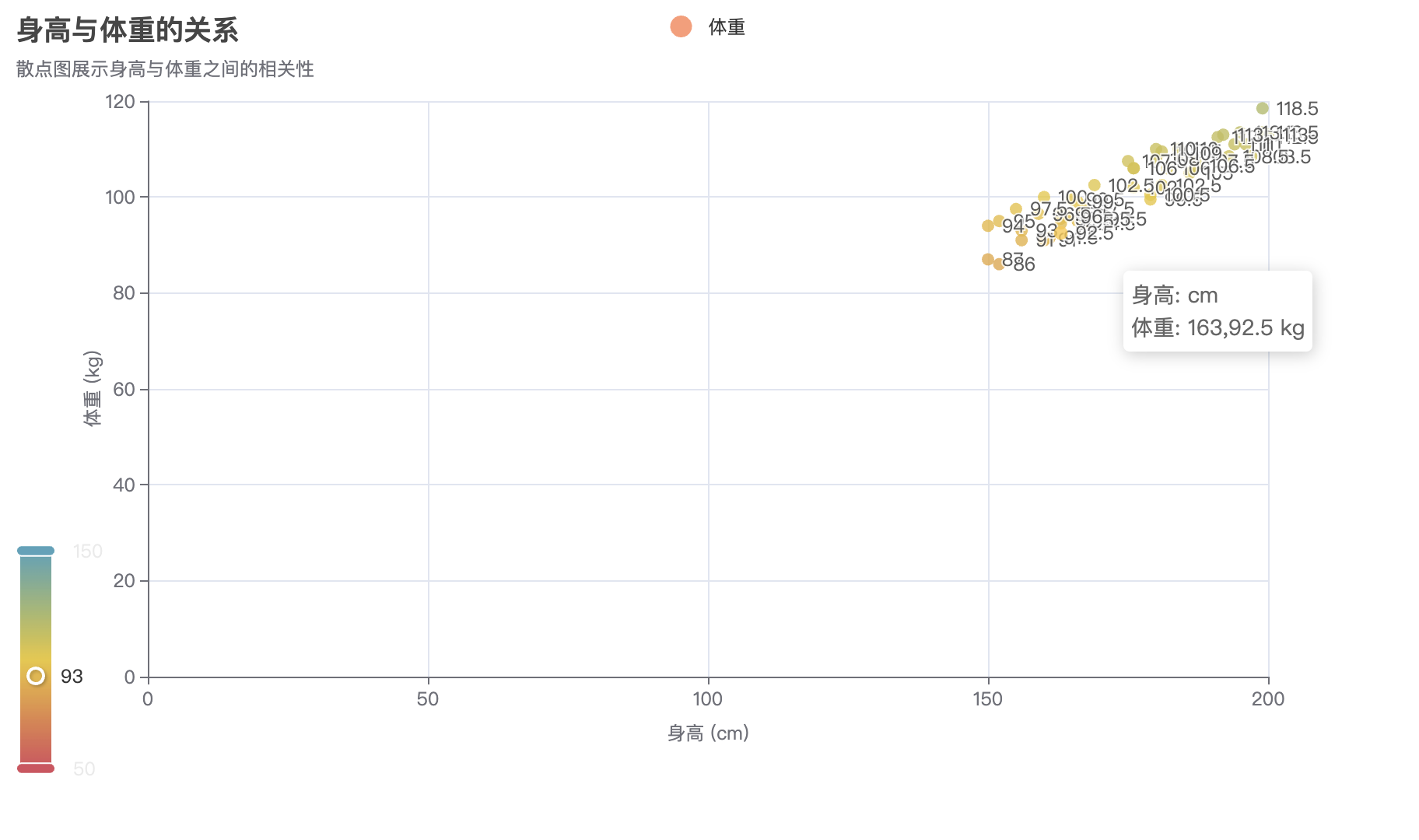
# 创建散点图
scatter = Scatter()
x_data = [random.randint(1, 100) for _ in range(30)]
y_data = [random.randint(1, 100) for _ in range(30)]
scatter.add_xaxis(x_data)
scatter.add_yaxis("散点数据", y_data, symbol_size=8, color="#ff7f50")
scatter.set_global_opts(
title_opts=opts.TitleOpts(title="散点图示例"),
xaxis_opts=opts.AxisOpts(name="X轴"),
yaxis_opts=opts.AxisOpts(name="Y轴"),
)
# 使用 Page 将多个图表放在一个页面中
page = Page()
page.add(bar, line, pie, scatter)
# 渲染页面到 HTML 文件
page.render("combined_chart.html")
print("所有图表已合并到 combined_chart.html 文件中。")
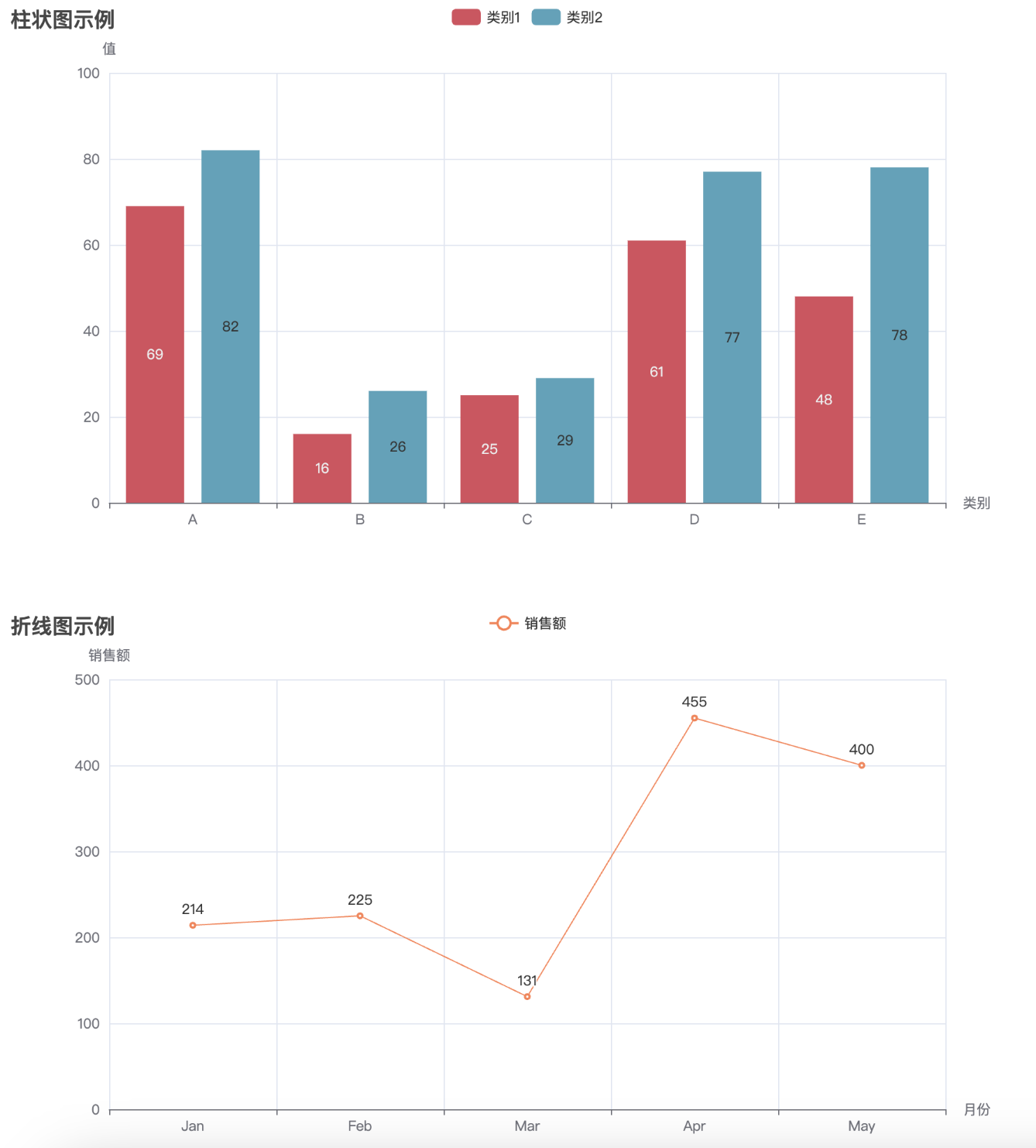
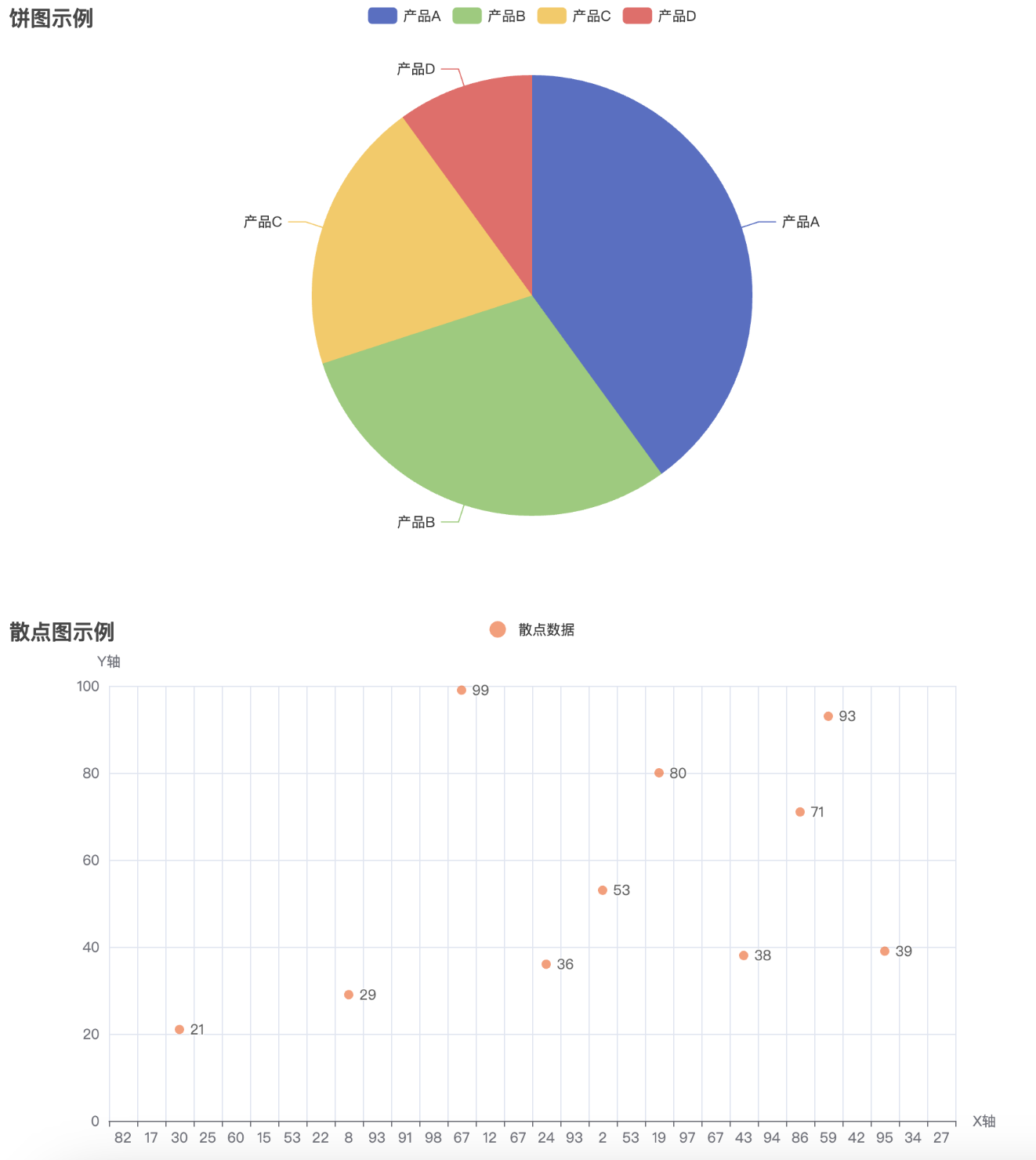
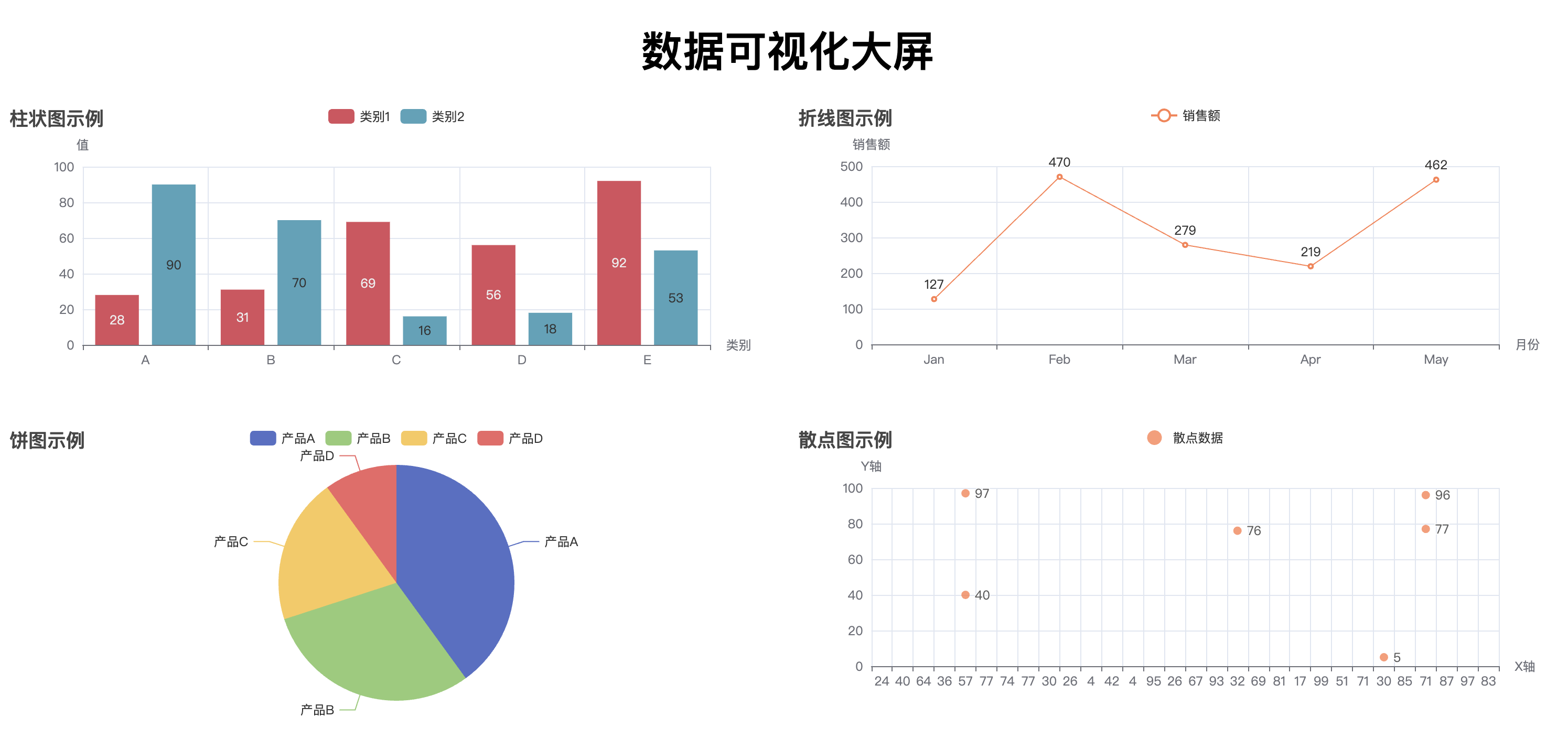
通过执行这段代码,最终会生成一个名为 combined_chart.html 的文件。打开该文件后,你将看到一个网页,包含四个图表(柱状图、折线图、饼图、散点图),它们将呈现在同一个页面中,用户可以浏览并查看不同图表的数据。通过 Pyecharts 提供的 Page 类,我们可以方便地将多个图表集成到一个 HTML 页面中进行展示,提升数据展示的效果和用户体验。
from pyecharts.charts import Bar, Line, Pie, Scatter, Page
from pyecharts import options as opts
import random
# 创建柱状图
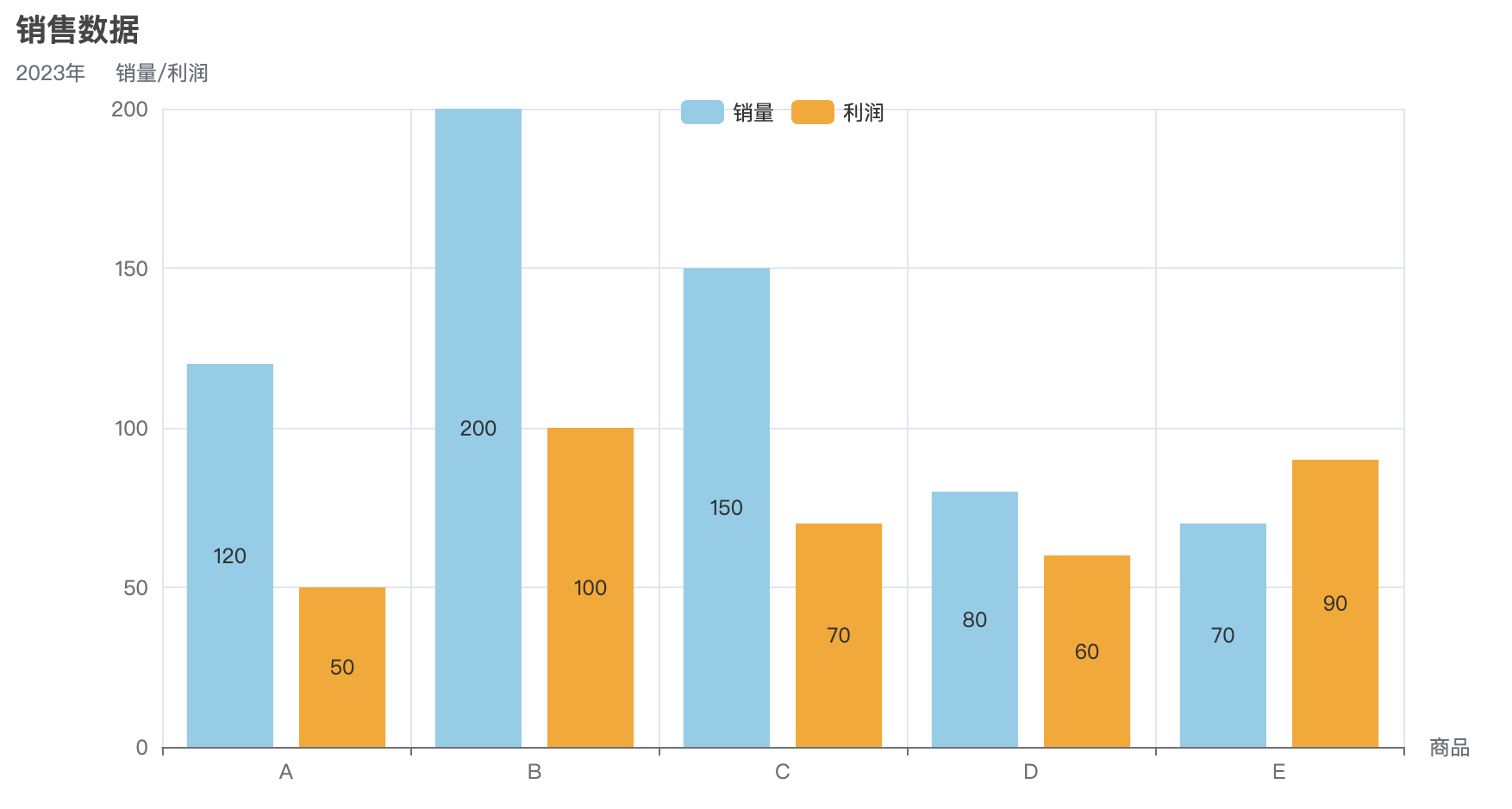
bar = Bar(init_opts=opts.InitOpts(width="50%", height="400px"))
bar.add_xaxis(["A", "B", "C", "D", "E"])
bar.add_yaxis("类别1", [random.randint(10, 100) for _ in range(5)], color="#d94e5d")
bar.add_yaxis("类别2", [random.randint(10, 100) for _ in range(5)], color="#50a3ba")
bar.set_global_opts(
title_opts=opts.TitleOpts(title="柱状图示例"),
xaxis_opts=opts.AxisOpts(name="类别"),
yaxis_opts=opts.AxisOpts(name="值"),
)
# 创建折线图
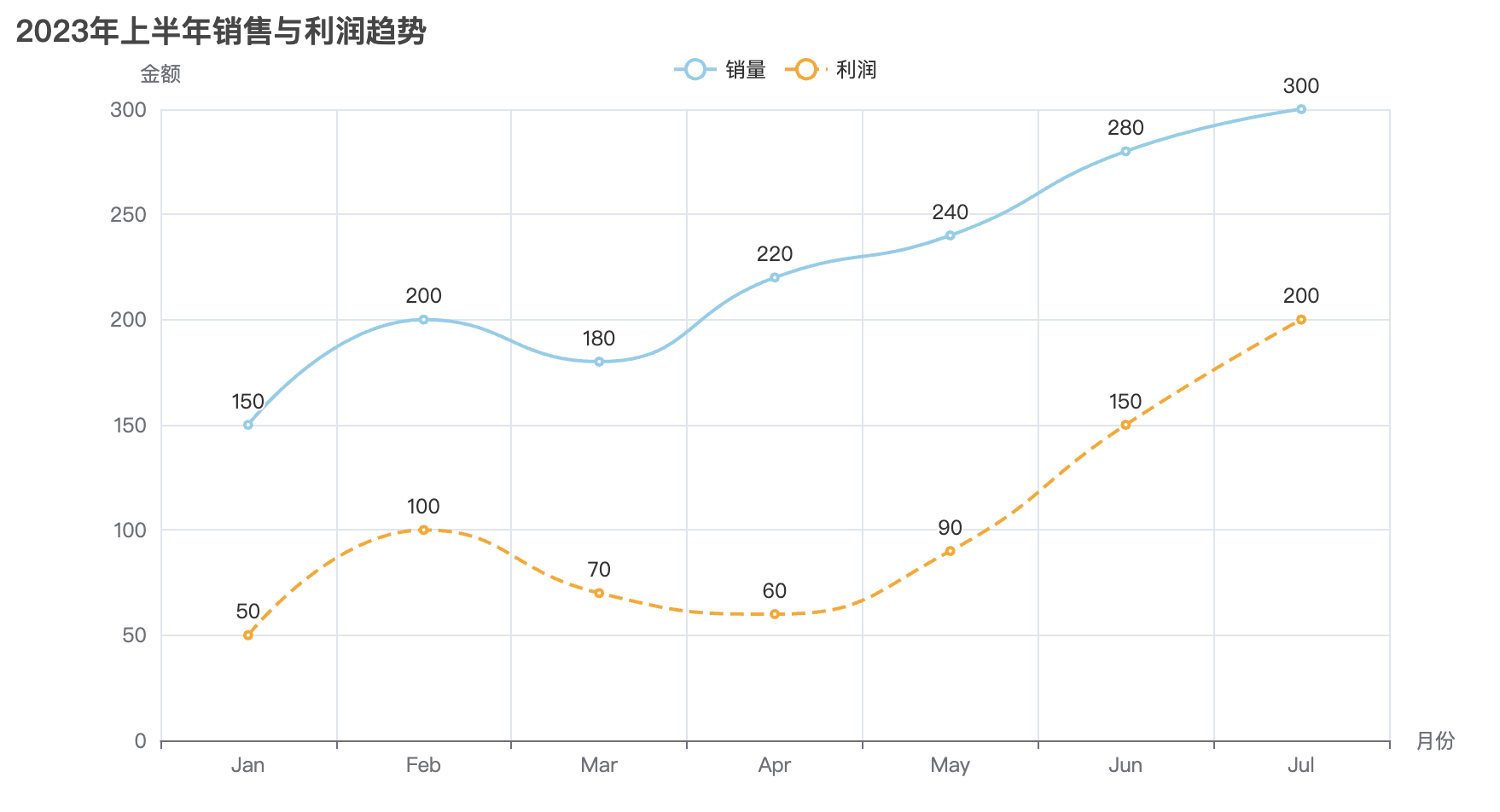
line = Line(init_opts=opts.InitOpts(width="50%", height="400px"))
line.add_xaxis(["Jan", "Feb", "Mar", "Apr", "May"])
line.add_yaxis("销售额", [random.randint(100, 500) for _ in range(5)], color="#ff7f50")
line.set_global_opts(
title_opts=opts.TitleOpts(title="折线图示例"),
xaxis_opts=opts.AxisOpts(name="月份"),
yaxis_opts=opts.AxisOpts(name="销售额"),
)
# 创建饼图
pie = Pie(init_opts=opts.InitOpts(width="50%", height="400px"))
pie.add("产品占比", [("产品A", 40), ("产品B", 30), ("产品C", 20), ("产品D", 10)])
pie.set_global_opts(title_opts=opts.TitleOpts(title="饼图示例"))
# 创建散点图
scatter = Scatter(init_opts=opts.InitOpts(width="50%", height="400px"))
x_data = [random.randint(1, 100) for _ in range(30)]
y_data = [random.randint(1, 100) for _ in range(30)]
scatter.add_xaxis(x_data)
scatter.add_yaxis("散点数据", y_data, symbol_size=8, color="#ff7f50")
scatter.set_global_opts(
title_opts=opts.TitleOpts(title="散点图示例"),
xaxis_opts=opts.AxisOpts(name="X轴"),
yaxis_opts=opts.AxisOpts(name="Y轴"),
)
# 使用 Page 将多个图表放在一个页面中,调整为左右布局
page = Page(layout=Page.DraggablePageLayout, page_title="综合数据展示")
page.add(bar, line, pie, scatter)
# 渲染页面到 HTML 文件
page.render("combined_chart.html")
print("所有图表已合并到 combined_chart.html 文件中。")
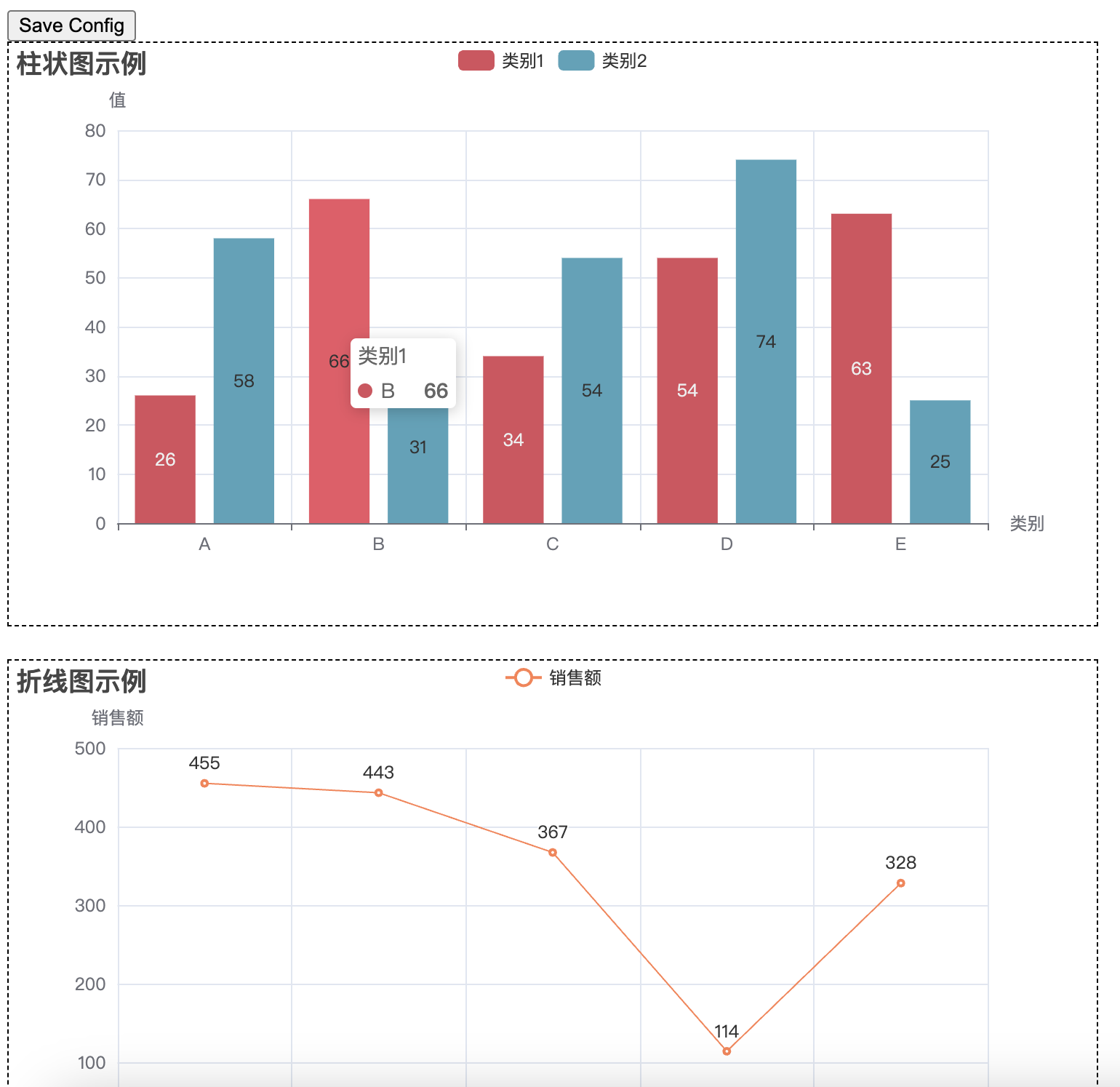
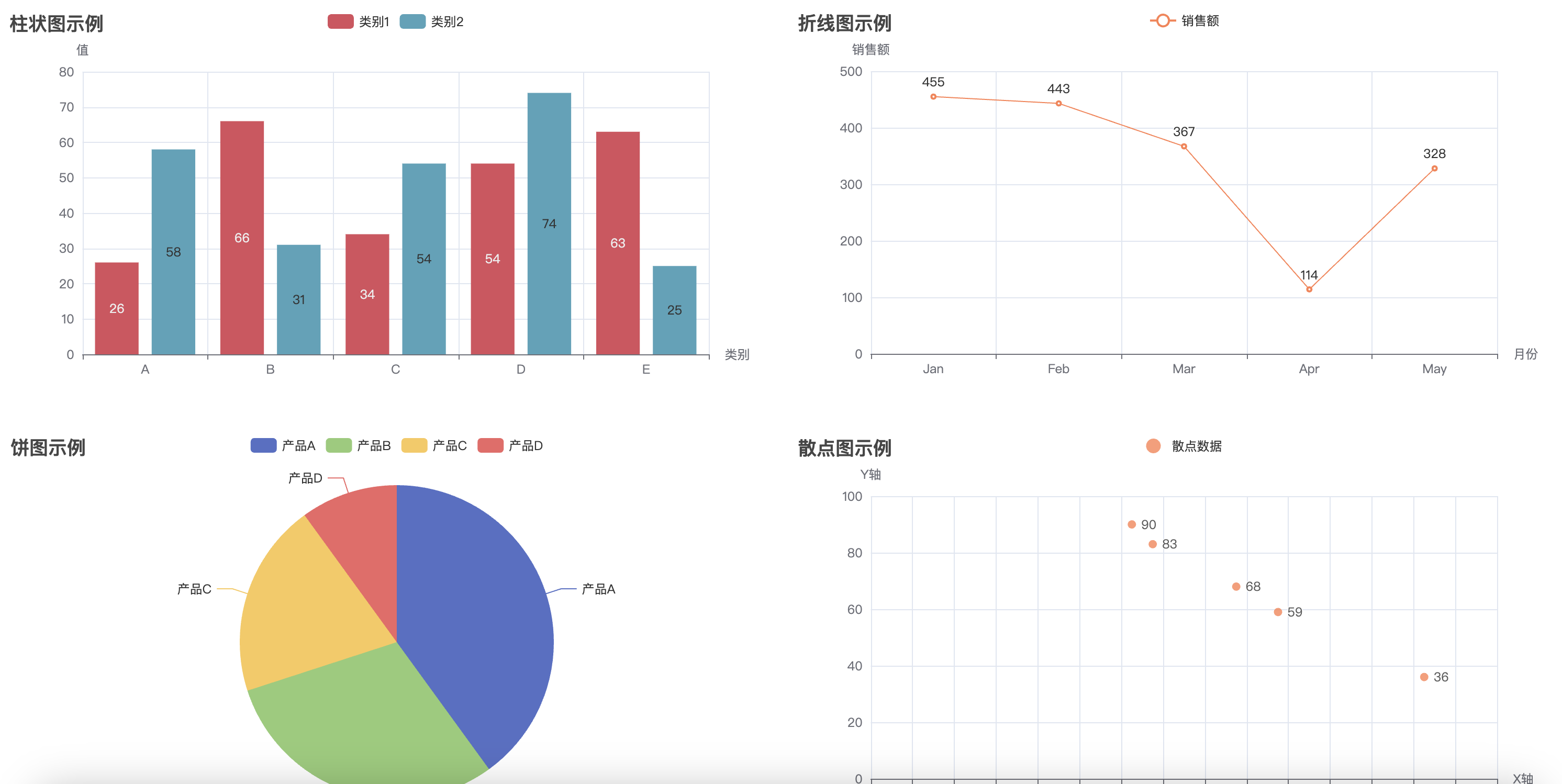
这样会形成一个可以拖拽式的网页,拖拽完成之后点击左上角的 Save Config 按钮,可以得到一个 chart_config.json 文件。然后写一个新的脚本,运行下面的代码,即可将原有的 html 文件(’combined_chart.html’)和 chart_config.json 文件一起生成新的 html 文件(’combined_chart_resize.html’)并且符合拖拽后的样式。
WARNING: This is a development server. Do not use it in a production deployment. Use a production WSGI server instead. Running on http://127.0.0.1:5000
在现代 Web 应用中,人工智能(AI)和机器学习(ML)算法的应用越来越广泛。将 AI 模型部署到 Web 服务中,可以让其他应用或用户通过 API 调用模型进行预测、分类、回归等任务。Flask 是一个轻量级的 Web 框架,非常适合将机器学习模型和 AI 算法封装成 API 服务。PyTorch 是一个流行的深度学习框架,广泛用于开发和训练神经网络。Flask 与 PyTorch 结合 可以实现将训练好的深度学习模型部署成 Web API,供外部应用调用。
当 AI 模型训练完成后,可以通过 Flask 构建 REST API,使得其他应用或前端可以轻松调用模型进行推理。Flask 作为一个轻量级的框架,能够快速构建 API 并且支持与 PyTorch 深度学习框架无缝对接。使用 Flask 和 Gunicorn 部署的 AI 模型,可以通过不同的方式进行扩展,如增加多台服务器、与其他微服务结合等。
构建 Flask API 服务与 PyTorch 模型结合
假设我们已经有了一个训练好的 PyTorch 模型,接下来将其部署为一个 Web 服务。以下是详细步骤:
Flask 使得将机器学习模型部署为 API 变得非常简单,适合快速开发和部署 AI 应用。PyTorch 是一个强大的深度学习框架,可以方便地加载训练好的模型进行推理,并与 Flask 紧密集成,提供 REST API 接口供其他系统或前端调用。通过结合使用 Flask 和 Gunicorn,可以让 AI 模型在生产环境中高效稳定地运行,满足高并发请求的需求。这种 Flask 与 PyTorch 的结合应用非常适合用于构建机器学习服务、推荐系统、图像处理、自然语言处理等领域的 Web 应用。
笔者算起来毕业已经将近十年时间,工作经验告诉我,人工智能的核心在于数据。没有数据作为支撑,任何所谓的 AI 研究都只是空洞的理想,根本无法落地。一些企业在手工作坊的环境下,根本没有搭建起完整的数据平台,也没有做出有效的数据积累,却一味地追求“AI”标签,这种做法不但不可行,还可能导致浪费大量资源。没有数据,AI 就像是没有燃料的火箭,根本飞不起来。
企业如果没有数据中台,没有清晰的数据治理体系,只靠离线 EXCEL、PPT、Word 和各种 txt 收集数据,如何能够通过 AI 来提升业务效率?事实上,这些企业往往只会做表面功夫,尝试在一些局部领域“做做样子”,但真正能够支撑 AI 运作的数据资源却没有形成。在 AI 的发展过程中,数据的采集、清洗、标注和存储都是至关重要的工作。如果连这些基础的工作都没有做好,怎能指望快速进行 AI 落地实践?在这种情况下,AI 只能成为一种营销噱头,只能停留在各种技术文档和 PPT 中。
AI 的核心并不仅仅在于算法,它依赖于大量的历史数据、持续的数据积累和强大的计算资源。而某些企业没有统一的数据库、没有数据管理平台、也没有足够的计算资源(比如 GPU),却妄想在短期内实现 AI 驱动的突破。这种做法本质上是在对 AI 的基本要求视而不见,忽视了其背后庞大的数据和硬件资源需求。
AI 赋能各种各样的业务并不是一蹴而就的过程,它需要大量的时间、资源和数据积累。很多企业在没有充分准备的情况下贸然推行 AI,只会在短期内制造出假象,看似在紧跟技术,实则是为了跟上时代的潮流而做的表面功夫。企业如果仅仅停留在“AI”这个概念层面,而没有实实在在的技术积累和数据支持,任何期望都注定是无果的。AI 的应用并不是“魔法”,它需要足够的时间、数据和资源来打好基础。从数据中台建设、计算资源的配置,到模型的迭代优化,都是企业需要一步步完善的工作。没有这些基础建设,单纯的“AI 梦想”终将被现实打破。
当前在一些企业中,人工智能的应用在某些领导眼中似乎并没有立即带来显著的效益,甚至被认为“只是锦上添花”,这主要源于基础设施的不完善和数据资源的不足。AI 的成功应用并不是一个短期的过程,它需要强大的数据支撑和持续的技术迭代。如果企业没有建立起数据中台、统一的数据架构,而是让各个团队在不同的云平台上搭建各自的数据库,那么数据的碎片化与不一致性必然会影响 AI 的效果。因此,AI 在短期内可能看不到立竿见影的“雪中送炭”效果,但它的长远价值仍然无法忽视。
与其让人工去做重复、低效的工作,不如逐步推动 AI 在可行范围内的应用。人工智能在处理大量数据、模式识别和自动化决策方面具有巨大的潜力,虽然当前可能只是初步落地,但它提供的是长期效益,不仅仅是一个“加分项”。通过系统性地收集数据、优化算法,AI 将逐步从“锦上添花”变成企业真正的生产力工具。
当一个企业没有充足的数据资源和必要的硬件支持时,所谓的 AI 研究只是徒劳的技术摆设,甚至可能引发更多的技术焦虑和误导。许多企业过于追求“人工智能”的标签,用 AI 项目吸引资本和眼球,却忽视了真正能够产生实际效益的基础工作。这种“无数据、无基础”的 AI 项目,无论做多少年,都难以突破瓶颈,最终只能沦为技术上的“空壳”。在一些企业的 AI 推广中,我们看到的不是扎实的技术积累,而是梦想与空谈。这些企业没有在数据、技术、团队等方面做好充分的准备,却一味地希望通过 AI 来获得市场竞争力。AI 发展不是一场幻想,它需要的是真正的基础设施建设:数据中台、清晰的数据架构、有效的数据采集和处理手段。在没有这些支撑的前提下,追逐“AI 时代”的梦想只会成为纸上谈兵。真正的技术迭代,应该是建立在现实基础之上的,而不是空洞的愿景中。
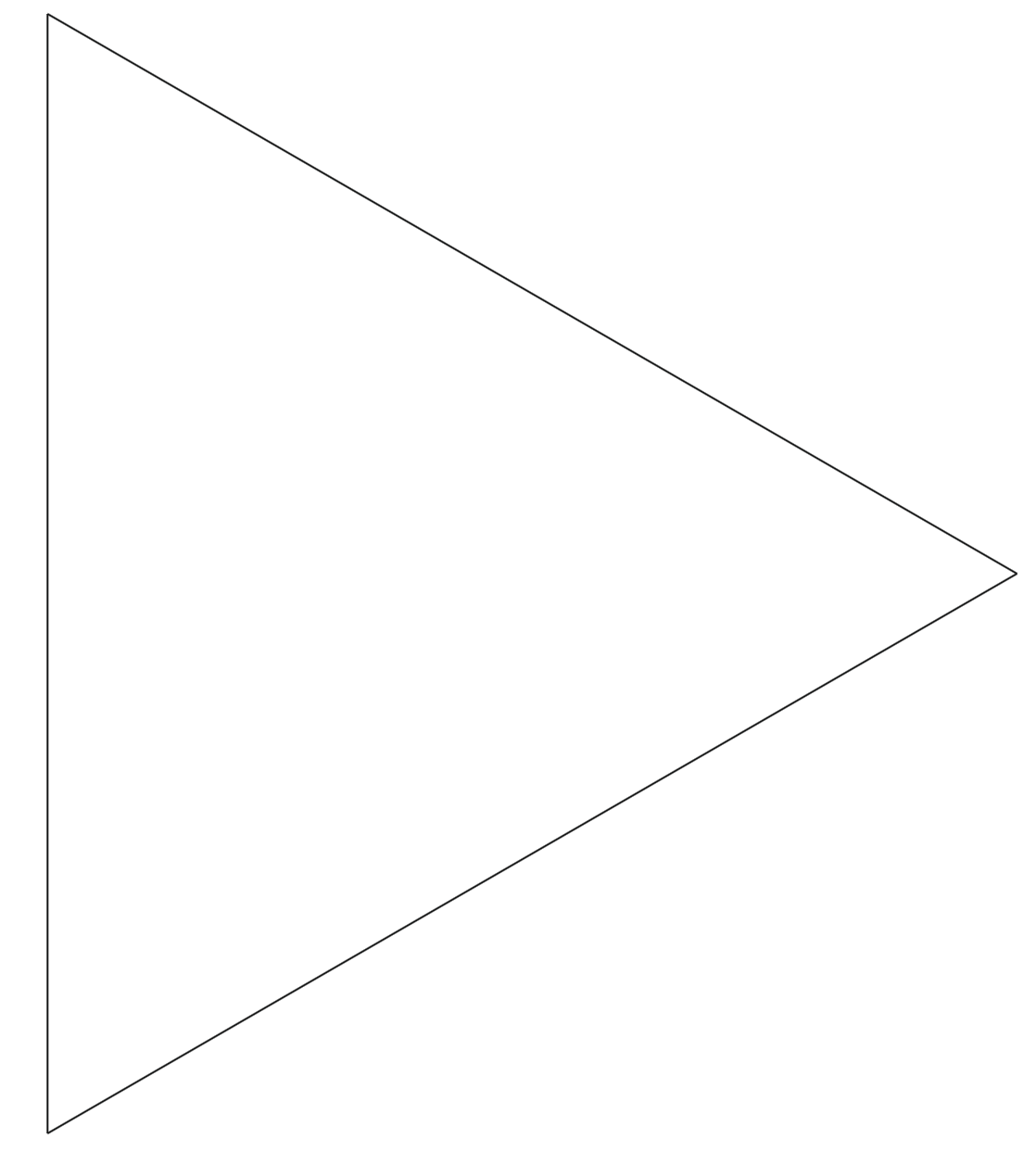
在数学的世界中,有一种特殊的几何形态——分形。分形不仅仅是由简单规则生成的复杂图形,还由于它们呈现出自相似性(self-similarity),在更细微的尺度上微观显示出相似甚至相同的结构。除了 Cantor 三分集之外,Koch 曲线和 Koch 雪花同样是数学界最著名的分形图形之一。
Koch 曲线,最早由瑞士数学家海里格·冯·科赫 (Niels Fabian Helge von Koch)在 1904 年提出,其撰写论文是《Sur une courbe continue sans tangente, obtenue par une construction géométrique élémentaire》,翻译成中文就是《关于一条连续而无切线,可由初等几何构作的曲线》。确实 Koch 曲线是一种由递归定义的分形曲线,就和 Cantor 三分集一样,通过简单的几何操作,即可创造出美妙的图形。在构造的过程中,Koch 曲线展现出了如何在有限的范围内呈现出长度是无穷的曲线。
除了电子工业出版社之外,笔者与人民邮电出版社也有着相应的合作,在合作期间阅读了一些人民邮电出版社的书籍,包括但不限于《建筑中的数学之旅》、《唤醒心中的数学家》、《微积分的历程》、《你不可不知的50个数学知识》这样一批优秀的数学科普书籍。自从离开数学界之后,自己阅读数学书籍的时间相对减少,而阅读计算机或者人工智能书籍的时间则相对增加。但是到了转行十年的时候,个人觉得数学这门学科却有着它独特的魅力,其魅力在于一种“永恒性”,无论时间怎么变化,历史怎么发展,在数学上正确的东西就会长期存在下去,即使是错误,也留给其他数学家攻克和解决的空间。而其他学科就不太一样,只要保证 work 就行,能用就好,或者在某些指标上面有一些提升,但是却很难保证一种“永恒性”。




































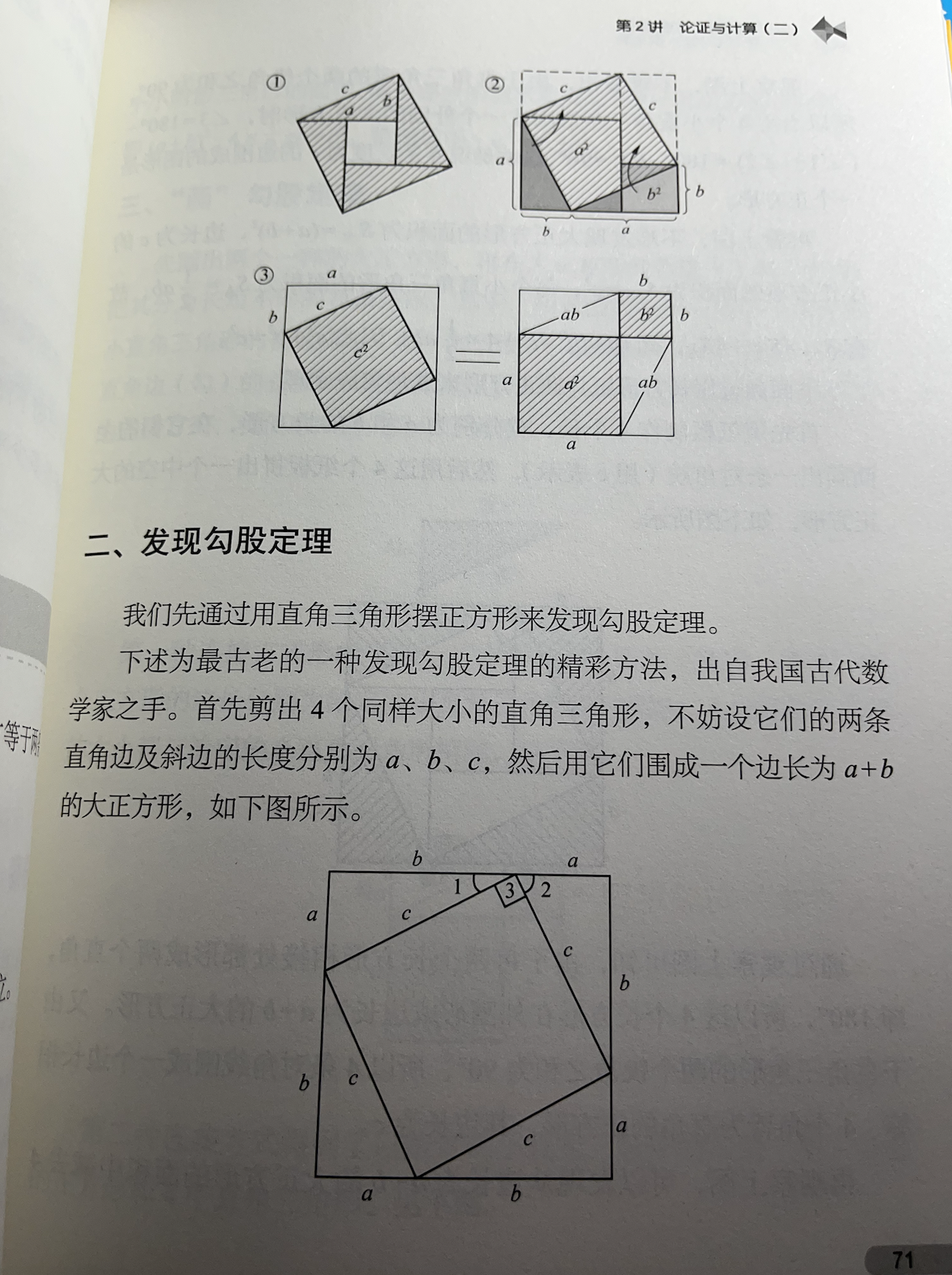





 ;
; ;
; ,如图所示。
,如图所示。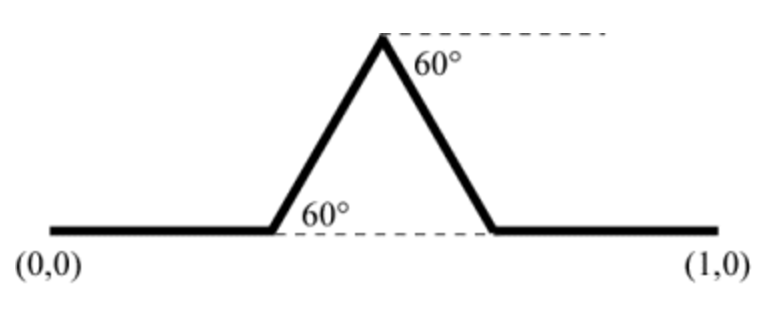
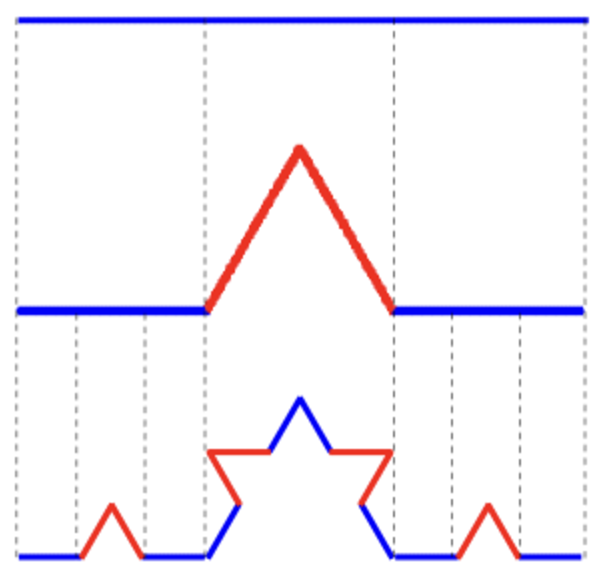

 表示向前,
表示向前, 表示左转
表示左转  表示右转
表示右转  。也就是说,每一次的迭代,都会使得总的长度变成原来的
。也就是说,每一次的迭代,都会使得总的长度变成原来的  倍。由于
倍。由于 ,
, 个大小一致且互不重叠的小物体组成,这些小物体的形状和这个物体本身相同。若这些小物体和大物体的大小比例为
个大小一致且互不重叠的小物体组成,这些小物体的形状和这个物体本身相同。若这些小物体和大物体的大小比例为  ,也就是说小物体放大
,也就是说小物体放大  倍之后与大物体完全重合,那么这个几何物体的 Hausdorff 维度(豪斯多夫维数)就定义为
倍之后与大物体完全重合,那么这个几何物体的 Hausdorff 维度(豪斯多夫维数)就定义为  ,
, 。
。 的线段可以被分成
的线段可以被分成 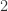 段(
段( ),每段的长度与原来线段的大小比例是
),每段的长度与原来线段的大小比例是  (
( ),因此 Hausdorff 维度是
),因此 Hausdorff 维度是  。
。 个边长是
个边长是 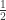 的小正方形,每一个小正方形与原来正方形的大小比例是
的小正方形,每一个小正方形与原来正方形的大小比例是  。
。 个边长是
个边长是  。
。 。
。 。
。

 。
。
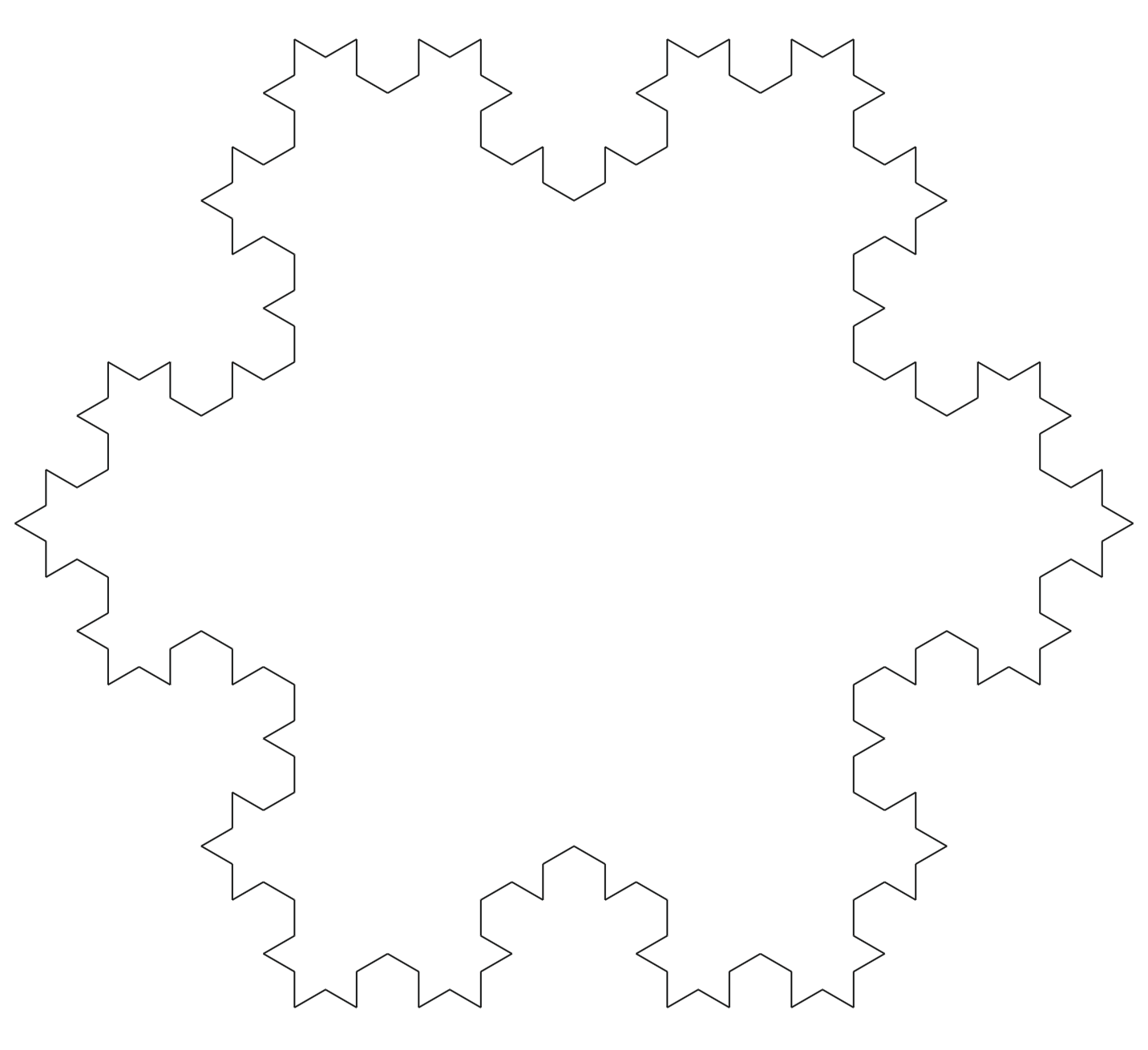

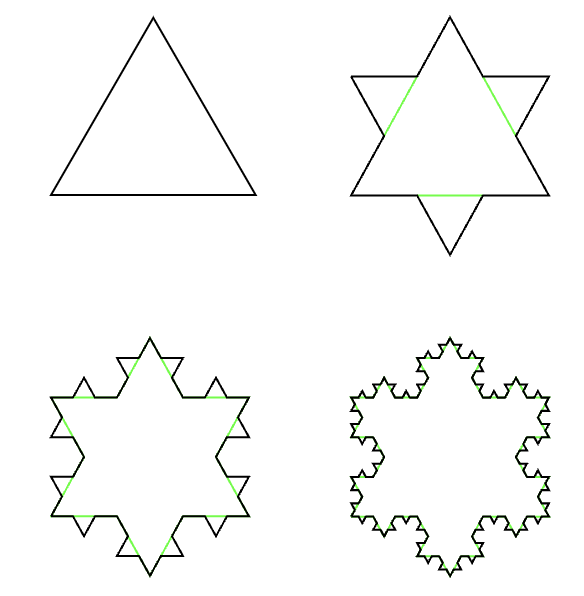
 是初始三角形的面积,
是初始三角形的面积, 表示第 $n$ 次迭代的三角形面积,其中
表示第 $n$ 次迭代的三角形面积,其中  。
。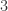 条,在第一次迭代的时候会生成三个小三角形,每一个小三角形的面积是初始的
条,在第一次迭代的时候会生成三个小三角形,每一个小三角形的面积是初始的  ,同时从
,同时从  条边。也就是说:
条边。也就是说: 。
。 ,同时从
,同时从  条边。也就是说:
条边。也就是说: 。
。

 。
。









 。除此之外,2025 这个数字在数字分解,求和以及各种特殊的数列中展现了其迷人的规律。从质因数分解到数论研究,2025 不仅仅是一个年份,更是一扇通向数论研究的窗口。在这篇文章中,我们将一同揭开 2025 的神秘面纱,探索它背后那些令人惊叹的数学性质和规律。或许,作为读者的你会发现,这个年份远比你想象的更加有趣。
。除此之外,2025 这个数字在数字分解,求和以及各种特殊的数列中展现了其迷人的规律。从质因数分解到数论研究,2025 不仅仅是一个年份,更是一扇通向数论研究的窗口。在这篇文章中,我们将一同揭开 2025 的神秘面纱,探索它背后那些令人惊叹的数学性质和规律。或许,作为读者的你会发现,这个年份远比你想象的更加有趣。
 ,这里的
,这里的  ,比 2025 略大的完全平方数是
,比 2025 略大的完全平方数是  。也就是说,在近代能够在一生中经历两个完全平方数年份的人必定是高寿之人。
。也就是说,在近代能够在一生中经历两个完全平方数年份的人必定是高寿之人。 。满足这个条件的自然数非常“稀疏”,通过计算可以得到:
。满足这个条件的自然数非常“稀疏”,通过计算可以得到: ,
, 。
。 ,
, 这五个数字有且仅被使用了一次,通过乘法和幂运算就得到了 2025 这个数字。
这五个数字有且仅被使用了一次,通过乘法和幂运算就得到了 2025 这个数字。 。
。 ,那么
,那么 。
。 ,
, 。
。 。所以,2025 可以进一步地写成
。所以,2025 可以进一步地写成 。
。 。
。
 。
。 。
。 。所以说,2025 就是 2 重哈沙德数,换言之,
。所以说,2025 就是 2 重哈沙德数,换言之, 。
。 ,
, ,把劈成两半的数加起来,再平方,正好是原来的数字。从此他就专门搜集这类数字。按照第一个发现者的名字,这种怪数被命名为“卡布列克数”或“雷劈数”或“卡布列克怪数”。
,把劈成两半的数加起来,再平方,正好是原来的数字。从此他就专门搜集这类数字。按照第一个发现者的名字,这种怪数被命名为“卡布列克数”或“雷劈数”或“卡布列克怪数”。 ,那么 3025 就是一个雷劈数。
,那么 3025 就是一个雷劈数。 ,而
,而  ,那么 2025 也是一个雷劈数。
,那么 2025 也是一个雷劈数。 ,
, ,
, ,
, ,
, ,
, 。
。 是雷劈数,且
是雷劈数,且  ,
, 是
是  ,那么
,那么  也是雷劈数。
也是雷劈数。
 ,
, ,所以可以进一步得到:
,所以可以进一步得到:
 ,
, 的形式。证明完毕。
的形式。证明完毕。 来找到另一个雷劈数
来找到另一个雷劈数  。
。