
在人工智能的浪潮中,生成式模型已经从学术研究进入到实际应用的领域。而在这其中,检索增强生成(RAG)技术作为一种创新性的突破性方法,正在逐步改变我们对信息获取与内容生成的理解。对于开发者、数据科学家以及所有致力于人工智能应用开发的人来说,《大模型RAG应用开发:构建智能生成系统》是一本不可或缺的宝贵资源,它不仅深入浅出地解读了 RAG 技术的核心概念、工作原理,还通过细致的案例展示了如何将这一技术应用于各个行业,为智能生成系统的构建提供了丰富的实践指导。

RAG:智能生成的前沿之路
在深入了解这本书之前,我们首先需要清楚什么是 RAG 技术。RAG,全称“Retrieval-Augmented Generation”,是将传统生成模型与信息检索技术结合的一种新型架构。与传统的纯生成式模型不同,RAG通过检索与生成的协同工作,不仅能够提高生成内容的质量,还能在处理实时、动态的信息时展现出巨大的优势。通过检索相关的外部知识,RAG系统能够在生成内容时引入最新、最相关的上下文信息,极大提升生成模型的实际应用能力。
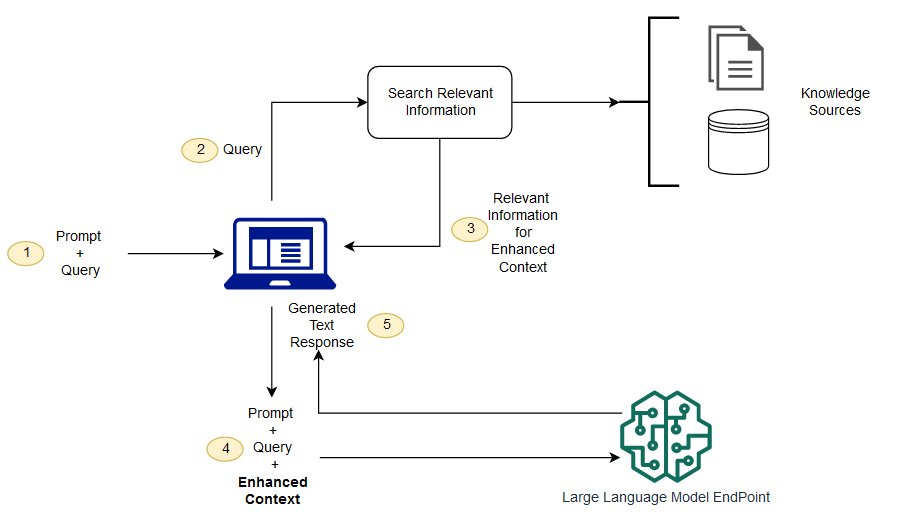
在传统的生成式AI中,模型主要依赖于预训练时学习到的知识。然而,随着数据的迅速变化和信息的不断更新,预训练模型的固有局限性显而易见。RAG的出现,正是对这一瓶颈的有效突破。通过集成检索模块,RAG不仅能够查询外部知识库,还能根据实时需求生成更为精确和符合时效性的内容,避免了传统生成模型无法处理最新信息的局限。

知识库的重要性
无论是个人知识库还是企业知识库,它们在RAG系统中都占据着至关重要的位置。在 RAG 的应用场景中,知识库不仅是信息检索的源泉,更是生成内容质量的保障。个人知识库可以帮助用户通过简洁、智能的方式快速获取自己曾经积累的知识,而企业知识库则通过整合全公司范围内的文档、报告、邮件等内容,为企业决策者提供可靠的信息支持,帮助企业提高工作效率。
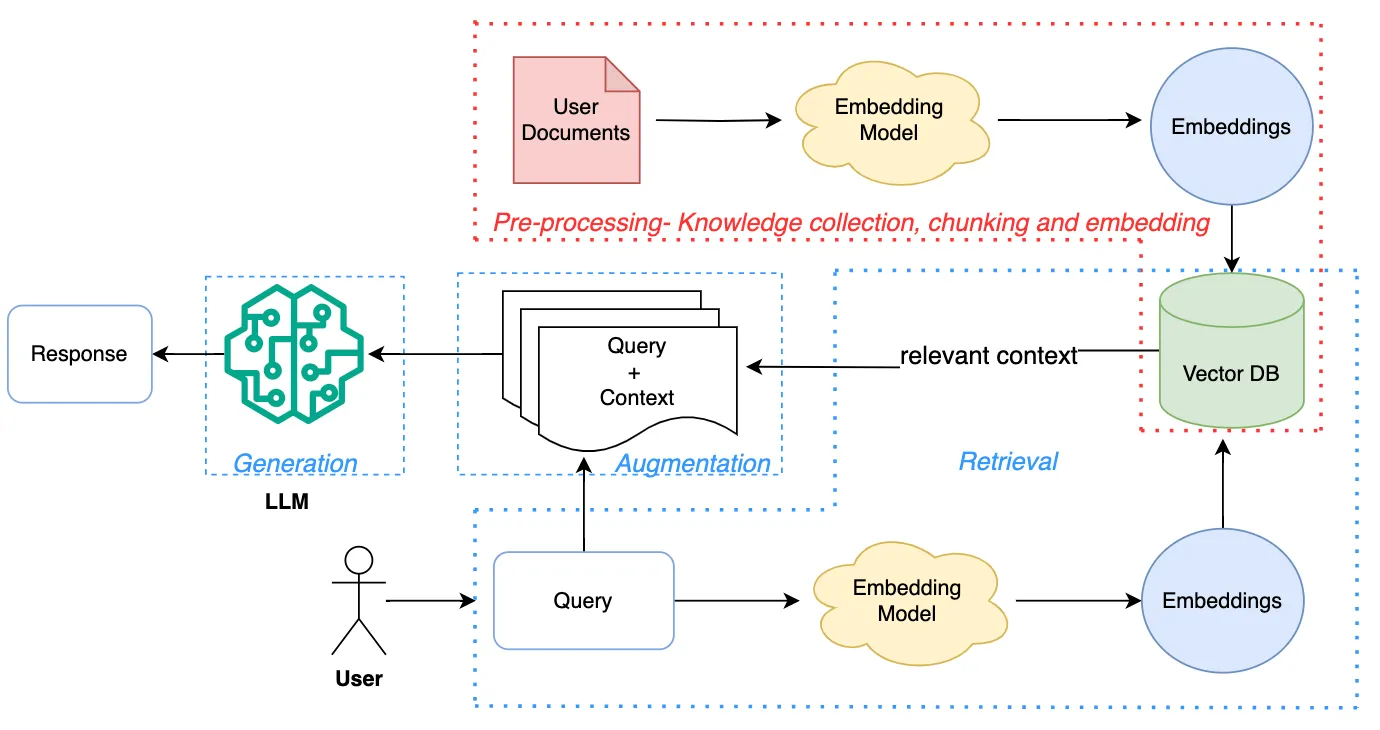
对于开发者而言,理解和构建一个高效的知识库是开发RAG应用系统的基石。书中对如何构建与优化向量数据库进行了深入的阐述,特别是在数据向量化与FAISS开发方面,提供了极为详细的步骤与技术细节。从数据清洗、向量化到向量检索的实现,每一步都紧密结合RAG应用中的实际需求。这些内容不仅帮助读者更好地理解向量数据库的构建过程,还为那些需要进行大规模数据处理与检索的应用开发提供了宝贵的经验与方法。
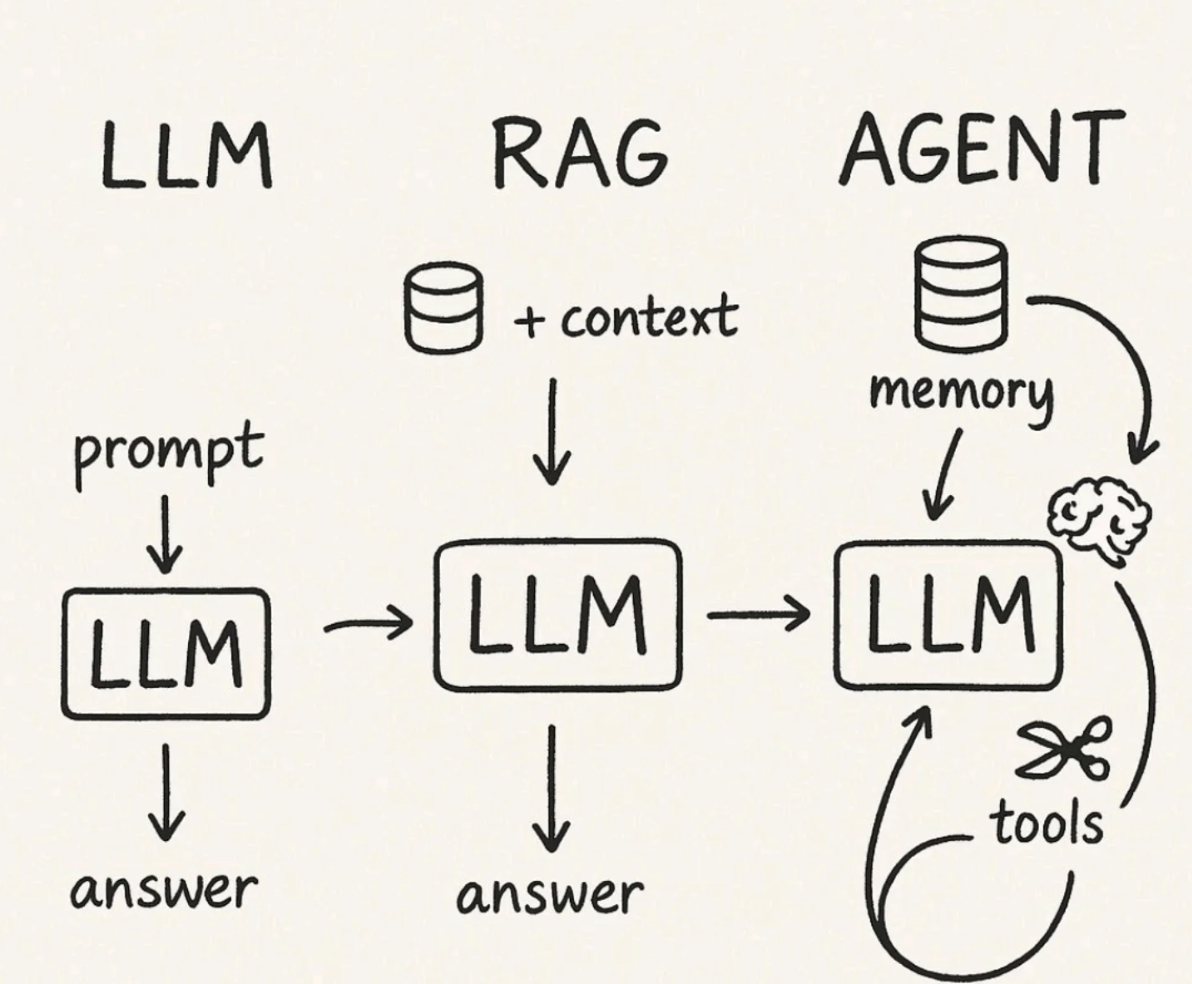
书籍内容的深入解读
《大模型RAG应用开发:构建智能生成系统》一书的第一大亮点,就是其系统全面地讲解了RAG技术的开发流程。书中的第1至第3章,重点介绍了RAG开发的基础内容,包括 Python 开发环境的搭建、Faiss 常用工具与模块的使用以及智能体的基本概念。对于初学者来说,这些内容可以帮助他们从零开始建立 RAG 系统的基本框架,理解其背后的技术原理。

而从第4章开始,书籍进入了 RAG 应用的具体开发过程。如何构建高效的检索增强模型,如何在开发中引入 FAISS 和 Transformer 等工具,以及如何优化检索结果以提高生成内容的准确性和一致性,这些细致的步骤和技术详解无疑为开发者提供了极大的帮助。特别是在第9至第11章,书中通过企业文档问答系统、医疗文献检索系统和法律法规查询助手等实际案例,让读者能够深入理解 RAG 技术在不同领域的具体应用,为今后的开发与实践提供了极为宝贵的参考。

对行业的深远影响
随着大模型的不断演进,RAG 技术的应用场景也在不断扩展。从企业内部知识管理,到医疗、法律等专业领域的智能辅助,RAG 系统正在成为一种新的行业标准。在医疗文献检索系统的开发过程中,RAG 不仅帮助医生更快地获取准确的医学文献,还通过生成模块提供精确的答案,节省了大量的查询和信息处理时间;在法律法规查询助手的开发中,RAG 通过对法规文本的向量化处理,帮助用户快速查找到相关法规条款,并结合上下文生成具有法律效力的解释,极大提升了法律工作者的工作效率。

随着大模型和 RAG 技术的不断普及,未来更多行业可能会在知识检索与生成内容的结合上产生革命性的变化。RAG不仅能帮助企业高效管理知识库,还能实现实时信息检索与智能内容生成,为企业提供精准、及时的决策支持。

总结
《大模型 RAG 应用开发:构建智能生成系统》是一本既具备理论深度,又具备实践操作性的技术书籍。它不仅详细讲解了 RAG 技术的基础概念和开发流程,还通过丰富的案例和具体的技术实现,帮助读者深入理解RAG 在各行各业中的应用价值。对于 RAG 技术初学者、大模型研发人员,以及数据分析和挖掘工程师等读者来说,这本书无疑是一本不可多得的指导书。

无论是在个人知识库的建设,还是在企业级智能生成系统的开发中,RAG 技术都展示了其巨大的潜力。随着 AI 技术的快速发展,未来的应用场景将更加广泛,RAG 将继续为智能生成和知识检索的结合开辟新的天地,而这本书,则为我们提供了走向这一未来的最强指南。
