代码规范
对于程序员而言,代码规范不仅仅是为了让代码看起来更整洁,它直接影响着代码的可读性、可维护性和团队的协作效率。统一的代码风格使得团队成员能够快速理解彼此的代码,无论是在日常的开发、代码审查还是修复bug时,都能有效避免因风格差异带来的误解或错误。遵循代码规范还能帮助提高代码质量,降低潜在的bug风险,并且对后期的扩展与重构更加友好。尤其是在大型项目或多团队协作的情况下,良好的代码规范更是保证项目可持续发展的基石。因此,始终坚持良好的代码规范是每个开发者应尽的责任,它不仅仅是为了提升个人编程习惯,更是为了整个团队的协同作战与代码的长期健康。
Python代码规范
Python 提倡简洁、清晰、易读的代码风格,PEP 8 是 Python 社区推荐的官方代码风格指南,它帮助开发者统一代码风格,提高代码的可读性和可维护性。遵循 Python 代码规范不仅有助于开发者之间的协作,还能让代码更加规范化,减少潜在的错误。以下是一些常见的 Python 代码规范。
1. 命名规范
- 变量、函数和方法的命名:使用小写字母,并通过下划线 _ 分隔单词(即蛇形命名法)。例如:user_age,calculate_total()
- 类名的命名:使用首字母大写的驼峰命名法。例如:UserProfile,OrderProcessor
- 常量命名:所有字母大写,单词间使用下划线分隔。例如:MAX_RETRIES,PI
- 私有变量和方法:以单下划线 _ 开头,表示该变量或方法是内部使用,不应直接访问。例如:_internal_data
- 避免使用Python保留字(如 class、if、try 等)作为变量名。
2. 缩进与空格
- 缩进:使用 4 个空格进行缩进,不要使用制表符(Tab)。这是 Python 语法要求的,错误的缩进会导致语法错误。
- 行内空格:在运算符两边加空格,增强可读性。
例如:对于赋值:x = 10
对于运算符:y = x + 5
- 函数参数的空格:函数定义和调用时,参数列表的两边不要加空格。例如:
def add_numbers(a, b):
return a + b
- 括号内的空格:不要在括号内多余的地方加空格。例如:
my_list = [1, 2, 3] # 正确
my_list = [ 1, 2, 3 ] # 错误
3. 行长限制
单行长度:每行代码的长度建议不超过 79 个字符。对于文档字符串(docstring)和长注释,推荐不超过 72 个字符。这有助于提高代码的可读性,尤其是在显示设备宽度有限时。如果行长超过限制,可以使用反斜杠 \ 进行换行,或者在括号、列表、字典等容器中自动换行。
4. 文档字符串(Docstring)
模块和类:在模块和类定义后,添加文档字符串说明其功能。文档字符串应该简洁明了,并且应说明类和模块的主要功能和用途。
class Calculator:
"""This class performs basic arithmetic operations."""
pass
- 函数和方法:为每个函数和方法提供文档字符串,描述其作用、参数和返回值。
def add(a, b):
"""
Add two numbers and return the result.
Parameters:
a (int or float): The first number.
b (int or float): The second number.
Returns:
int or float: The sum of a and b.
"""
return a + b
5. 异常处理
异常捕获:应该尽量避免使用过于宽泛的 except 块,避免捕获不必要的异常。应当明确捕获特定异常。
try:
x = 1 / 0
except ZeroDivisionError as e:
print(f"Error: {e}")
多个异常捕获:如果需要捕获多种异常,可以使用元组来列出这些异常类型。
try:
some_code()
except (TypeError, ValueError) as e:
print(f"Error: {e}")
6. 导入顺序
标准库导入:首先导入 Python 标准库模块,如 os、sys 等。
第三方库导入:其次导入外部安装的第三方库,例如 numpy、pandas、requests 等。
本地应用库导入:最后导入你自己编写的模块或应用库。
按照以上顺序,导入部分每一类模块之间应该留一行空行。例如:
import os
import sys
import numpy as np
import pandas as pd
from mymodule import my_function
7. 避免重复代码
Python 提供了许多库和工具,可以避免代码重复。如果发现自己写了类似的代码片段多次,应考虑将其提取成函数或类,提升代码的复用性。适当使用 Python 的标准库,如 itertools、functools 等,避免自己手动实现复杂的功能。
遵循 Python 代码规范能够帮助我们编写更简洁、更易于理解和维护的代码。最重要的规范包括命名规则、缩进与空格、行长限制、文档字符串、异常处理等。在大型项目中,团队成员遵循统一的规范可以提高协作效率,减少因代码风格不一致带来的混乱和错误。因此,开发者应该积极遵循 PEP 8 等官方规范,并利用代码规范检查工具(如 flake8、pylint 等)来保持代码质量。
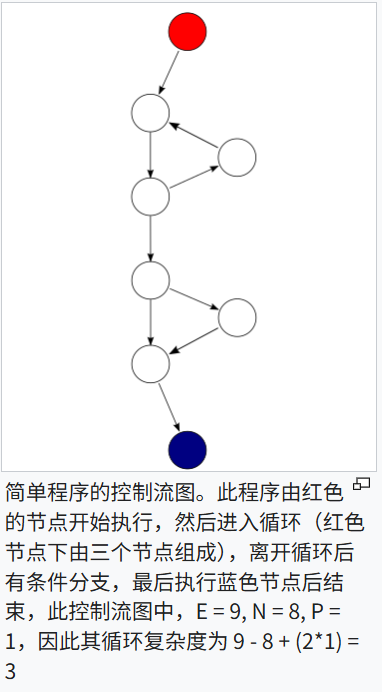
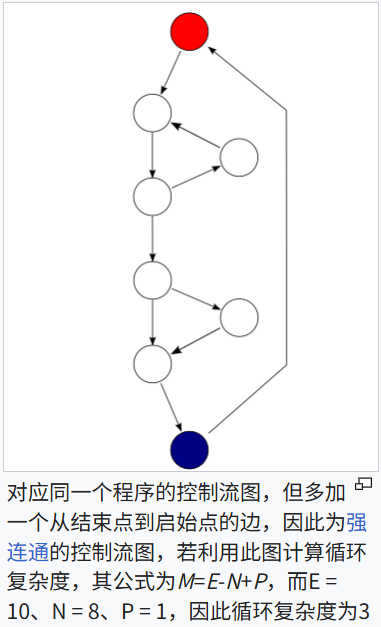
圈复杂度
圈复杂度(Cyclomatic Complexity)是衡量一个程序的控制流复杂度的一个指标,它由 Thomas McCabe 于 1976 年提出。圈复杂度的核心思想是衡量程序中独立路径的数量,反映了程序中控制流的复杂程度。简单来说,圈复杂度可以帮助你了解一个程序有多少条不同的执行路径。
为什么圈复杂度重要?
- 高圈复杂度:意味着代码中有很多的判断、循环和分支,程序的执行路径复杂。高复杂度的代码难以理解、测试和维护。
- 低圈复杂度:意味着代码结构简单,控制流清晰,容易理解和维护。
计算圈复杂度
圈复杂度的计算公式为:
V(G)=E−N+2P,其中:
- V(G) 是圈复杂度(Cyclomatic Complexity)。
- E 是程序图中的边的数量(边代表程序控制流的转移,比如跳转、条件等)。
- N 是程序图中的节点的数量(节点代表基本块,即一组顺序执行的语句)。
- P 是程序图中的连通组件的数量(一般情况下 P = 1,即程序是一个连通的整体)。
具体解释:
E:程序的控制流转移数量。例如,if、while、for、case 语句的数量都会增加边的数量。
N:控制流图中节点的数量,代表代码的块,例如顺序执行的语句组。
P:通常程序只有一个连通组件,即 P = 1,代表程序是一个整体。
直观解释
可以通过 控制流图 来理解圈复杂度。控制流图是一个图论的概念,它将程序的每个基本块(例如条件判断、循环等)表示为图中的节点,程序的控制流(跳转)表示为边。圈复杂度就是计算该图中所有独立路径的数量。
例如,下面是一个简单的代码示例:
def example(a):
if a > 10:
return "greater"
else:
return "lesser"
这段代码的控制流图非常简单,只有两个分支。它的圈复杂度为 2,因为有两个独立的路径(a > 10 和 a <= 10)。
计算圈复杂度的示例:
- 简单顺序执行:
def simple_function():
a = 5
b = 10
c = a + b
return c
- 控制流图:只有一个顺序的执行,没有条件和分支。
- 圈复杂度:1(只有一个路径,程序从头到尾顺序执行)
- 条件判断:
def function_with_if(a):
if a > 10:
return "greater"
else:
return "lesser"
控制流图:有一个 if 语句,形成两个分支路径。圈复杂度:2(一个条件判断,两个路径)
def function_with_while(a):
while a > 0:
a -= 1
return a
控制流图:有一个 while 循环,形成一个循环路径。
圈复杂度:2(一个循环结构,两个路径:一个是 while 循环路径,另一个是跳出循环后的路径)
如何使用圈复杂度?
- 代码可维护性:高圈复杂度意味着代码结构复杂,容易引入 bug,不利于维护。因此,圈复杂度高的代码通常需要重构。
- 测试覆盖率:圈复杂度的一个重要应用是 测试路径覆盖,它提供了最小路径集 的数量,这些路径集需要被单元测试覆盖。如果圈复杂度是 10,那么最少需要设计 10 个不同的测试用例来保证所有路径都被测试。
- 代码审查和重构:高圈复杂度通常提示代码不易理解或过于复杂,可能需要重构,降低复杂度,提高可读性。
小结:
- 低圈复杂度:代码清晰,易于理解和维护,测试更容易覆盖。
- 高圈复杂度:代码难以理解和测试,容易出错,可能需要重构。
圈复杂度是衡量代码复杂度的重要指标,它能帮助开发者评估代码的质量和可维护性。
Python代码检测工具使用指南
本文介绍多种常用的Python代码检测工具(pylint、flake8、ruff),涵盖安装方法、基本使用以及项目级检查的实践指导,帮助开发者快速实现代码质量分析与规范检查。
1. Pylint
1.1 安装
使用pip就可以轻松地把pylint这个工具安装好。
1.2 使用场景
检查单个文件
pylint my_script.py # 检查单个文件
检查文件夹
pylint src/ # 递归检查目录下所有.py文件
检查项目
pylint project/ --recursive=y # 检查项目
1.3 配置与过滤
生成配置文件:
pylint --generate-rcfile > .pylintrc
如果不想看某类错误的时候,我们可以选择忽略特定错误:
pylint my_script.py --disable=E1101,C0114 # 关闭未解析的属性和缺失docstring警告
2. Flake8
2.1 安装
使用pip就可以轻松地把flake8这个工具安装好。
2.2 使用场景
检查单个文件
flake8 my_script.py # 检查单个文件
检查文件夹
检查项目
可以通过下述命令来检查当前的目录和所有子目录
同时,flake8默认会使用pep8第三方包检查代码(经常会安装mccabe和pyflakes,安装之后,flake8就会提供个性的功能)。 pep8第三方包只能检查代码是否符合 pep8 代码规范(所以 flake8默认是使用pep8代码规范做检查)。
相对于Pylint ,flake8提供了些特有的功能。
- 检查代码的圈复杂度(flake8会调用mccabe计算圈复杂度)。
- 圈复杂度和if语句有关,选择分支越多,圈复杂度越高。
- 圈复杂度越低越好。圈复杂度高影响代码可读性,代码容易出错。
- flake8官网建议圈复杂不要超过 12 。
2.3 配置与扩展
配置文件支持:在 setup.cfg 或 .flake8 中配置规则:
pip install flake8-mutable # 安装可变默认参数检测插件flake8 --enable-extensions MutableDefaultArg
3. Ruff
3.1 安装
使用pip就可以轻松地把ruff这个工具安装好。
pip install ruff
# 或使用独立二进制(无Python环境依赖):
curl -Ls https://github.com/astral-sh/ruff/releases/latest/download/ruff-linux-amd64 | sudo tee /usr/local/bin/ruff >/dev/null && sudo chmod +x /usr/local/bin/ruff
3.2 使用场景
检查单个文件
检查文件夹/项目
ruff check src/ # 检查目录ruff check . # 检查整个项目
自动修复问题
ruff check --fix my_script.py
3.3 配置
兼容flake8配置:直接复用 .flake8 或 pyproject.toml,或在 pyproject.toml 中指定规则:[tool.ruff] line-length = 100 ignore = [“E501”, “F401”]
4. Mccabe
这是用来检查圈复杂度的工具
4.1 安装
pip install mccabe
pip install --upgrade mccabe
pip uninstall mccabe
4.2 使用场景
python -m mccabe --min 5 mccabe.py
("185:1: 'PathGraphingAstVisitor.visitIf'", 5)
("71:1: 'PathGraph.to_dot'", 5)
("245:1: 'McCabeChecker.run'", 5)
("283:1: 'main'", 7)
("203:1: 'PathGraphingAstVisitor.visitTryExcept'", 5)
("257:1: 'get_code_complexity'", 5)
5. Prospector
5.1 Prospector项目介绍
Prospector 是一款专为 Python 代码设计的强大分析工具,它旨在提供关于错误、潜在问题、规范违规以及复杂性方面的详尽信息。这款工具集成了诸如 Pylint、pycodestyle 和 McCabe 等众多Python代码分析工具的功能于一身。通过自定义配置文件(即“profile”),Prospector 提供了适用于大多数情况的默认配置,旨在帮助开发者在无需大量前期设置的情况下即可开始提升代码质量。它还能够适应项目所依赖的特定库和框架,比如自动调整对 Django 或 Celery 的支持,以减少误报。
5.2 项目快速启动
要迅速开始使用 Prospector,首先确保你的环境中安装了 Python 和 pip。然后,执行以下命令来安装 Prospector:
安装完毕后,在你的Python项目根目录下运行 Prospector,即可获取到代码审查报告:
cd /path/to/your/python/projectprospector
这将输出可能存在的问题列表,帮助你识别和修正代码中的隐患。对于更定制化的控制,可以添加额外参数,例如使用 –strictness medium 来设定中等严格的检查级别。
prospector --strictness high
5.3 应用案例和最佳实践
在使用 Prospector 时,一个典型的最佳实践是将其集成到持续集成(CI)流程中。比如,通过 .pre-commit-config.yaml 文件配置预提交钩子,确保每次提交前都经过代码质量检查:
repos:
- repo: https://github.com/PyCQA/prospector
rev: 1.10.0 # 使用具体版本或'master'以获取最新版本
hooks:
- id: prospector
args: ["--summary-only"] # 只显示总结,简化输出
对于团队协作项目,通过创建适合自己团队编码风格的配置文件(prospector.yml),可以进一步优化Prospector的行为,确保所有开发者遵循一致的标准。
5.4 典型生态项目
Prospector 在 Python 生态中扮演着重要角色,尤其是在那些重视代码质量和一致性维护的项目中。结合其他生态项目,如 mypy 进行静态类型检查,或 bandit 进行安全审计,可以构建出更全面的质量保障体系。Prospector的设计使其能与这些工具良好协同工作,通过在Prospector中启用相应插件,可以实现多维度的代码检查。
通过简单的配置和灵活的插件机制,Prospector不仅提升了单个项目的开发效率,也促进了整个Python社区代码标准的一致性和代码质量的普遍提升,成为了现代软件开发生命周期中不可或缺的一部分。
参考资料
- 代码检查工具文档介绍:https://wangmeng-python.readthedocs.io/en/latest/readability/code-analysis-tools.html
- Mccabe的GitHub链接:https://github.com/pycqa/mccabe
- Prospector的GitHub链接:https://github.com/prospector-dev/prospector
- ruff:https://myapollo.com.tw/blog/python-linter-ruff/